
Parallel AI agent PRs are pull requests generated by multiple AI coding subagents running simultaneously against the same repository. When five agents each produce a PR touching overlapping files, the merge sequence determines which features survive. Without deliberate workflow architecture: branch isolation, task scoping, serialized merge queues, and behavioral verification. Parallel AI agents don't multiply your throughput. They multiply your conflict surface area.
Teams using AI coding agents are discovering a counterintuitive problem: the faster they spin up subagents, the more time they spend recovering from merges. The velocity gain from parallelism exists. So does the velocity loss from bad merges. And because the bugs are behavioral, not syntactic, they don't show up until a customer, a QA run, or a demo reveals that something that should be there isn't.
The good news: this is a solvable engineering problem. It's not a fundamental limitation of AI coding agents. It's a workflow architecture problem, and it has well-defined solutions.
Why This Is Harder Than It Looks
The naive assumption about parallel AI agents is that more parallelism equals more throughput. Five agents working on five features simultaneously should produce five features in the time it previously took to build one. The math holds for isolated features that touch completely separate code paths.
Most real codebases don't have isolated features. They have shared services, shared utilities, shared types, shared configuration. The more interdependent your codebase, the more your agents' workspaces overlap, and the more their PRs will conflict.
When a conflict happens between two human engineers, there's a social mechanism to resolve it: one engineer reads the other's PR, understands the intent, and resolves the conflict deliberately. When a conflict happens between two AI agents, neither agent knows the other exists. The merge conflict is resolved by whichever agent or automated process handles it, and that process is optimizing for syntax, not for the intended product behavior.
The teams that have made parallel AI agents work well share a common thread: they treated agent workflow design with the same rigor they applied to the codebase architecture itself.
Strategy 1: Scope Agents to Non-Overlapping Work Units
The most direct solution to parallel AI agent conflicts is to prevent the overlap in the first place. Before spawning agents, decompose the work into units that touch clearly separate parts of the codebase.
This requires upfront task analysis that most teams skip. When you're spinning up agents to parallelize a sprint, the natural instinct is to map each task roughly to a user story or a Jira ticket. The problem is that user stories are defined in terms of user behavior, not code topology. Two tickets that appear unrelated from a product perspective can both modify the same service class.
A better heuristic: scope each agent's work to a single directory boundary, a single service, or a single data model. If two tasks both require touching the AuthService, they should be sequential tasks for the same agent, not parallel tasks for different agents. The cost of sequencing two tasks is lower than the cost of debugging a merge conflict that silently changes authentication behavior.
Some teams use a dependency graph approach: before running agents, map each task to the files it will likely touch (based on the task description and existing code structure), then assign agents to tasks only if their expected file sets are disjoint. This doesn't eliminate all conflicts: agents sometimes touch files outside their expected scope. But it dramatically reduces the overlap rate.
Strategy 2: Branch Isolation with Frozen Base Snapshots
Every parallel agent should work from the same frozen snapshot of the main branch, taken at the start of the parallel work session. This sounds obvious but is frequently violated when teams run agents asynchronously over time.
When Agent A starts at 9:00 AM and Agent B starts at 10:00 AM, they're working from different base snapshots. Agent B's base already includes Agent A's partially merged changes, or doesn't include them at all if Agent A hasn't merged yet. Either way, the snapshot inconsistency creates invisible conflict risk.
The right pattern: commit to a synchronization point before each parallel agent session. Pull the latest main, pin that commit SHA as the base for all agents in the session, and don't merge any agent's PR until all agents in the session have completed. This turns the parallel session into a controlled batch: N agents produce N PRs simultaneously, and then the PRs are merged sequentially with verification after each one.
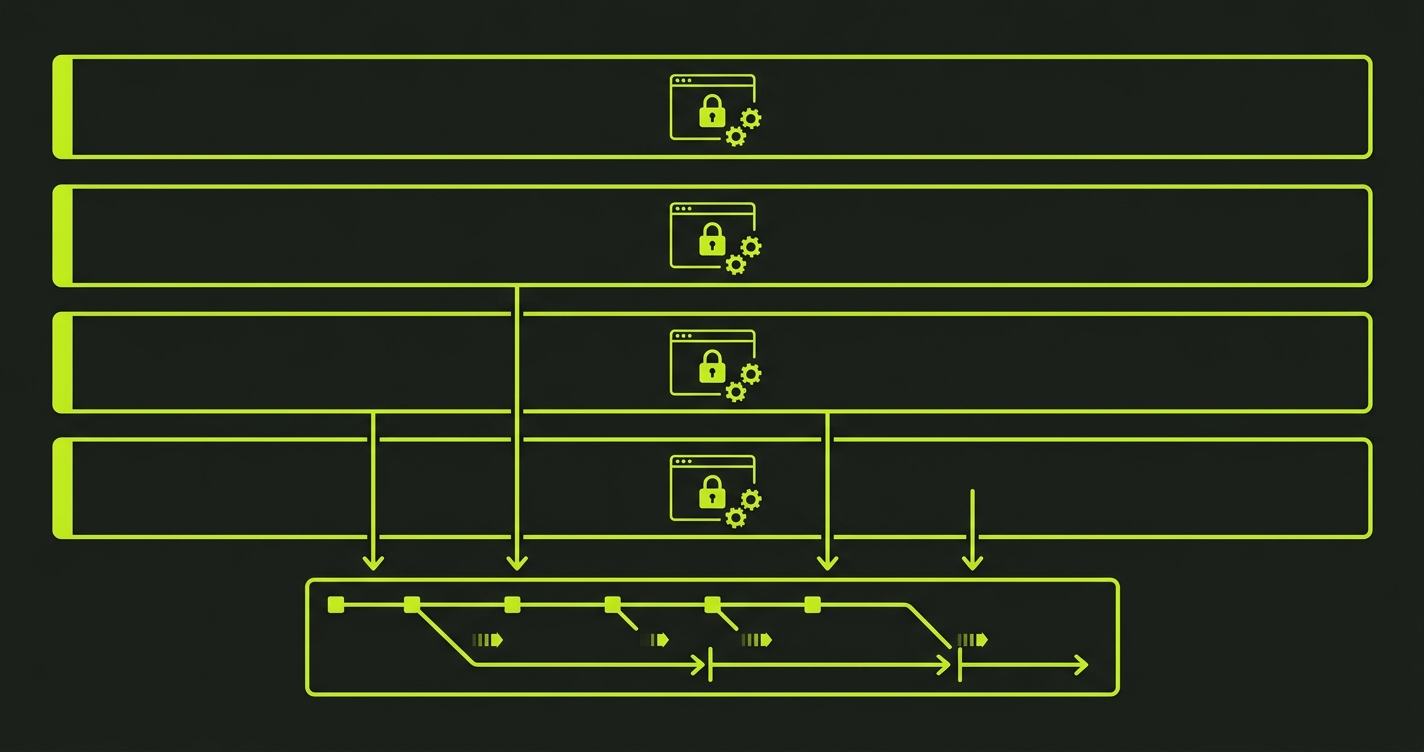
This approach trades a small amount of parallelism for a large amount of predictability. Instead of continuous asynchronous merging (high throughput, high conflict), you get batched synchronous merging (slightly lower throughput, dramatically lower conflict rate and debugging cost).
Strategy 3: Serialize the Merge Queue
Parallel generation, sequential merging. This is the core principle that prevents compounding conflicts.
The temptation when you have 10 completed PRs is to merge them all at once, or to let them merge concurrently. This is where most of the problems happen. Each merge changes the main branch. The next PR was written against an older main. The further apart the PRs were in time, and the more overlapping their file scope, the higher the probability of a silent regression.
A serialized merge queue means: merge one PR, run your verification suite, confirm the application behavior is correct, then merge the next PR. The verification step is the critical one: it's not just about CI passing. CI catching compilation errors and unit test failures. Behavioral verification catches the regression where the authentication middleware stopped checking a permission that a parallel agent removed from the service it was refactoring.
The overhead of serialization is not as high as it sounds. If your behavioral verification runs in 5-10 minutes per merge (which is achievable with Autonoma against a Vercel preview), and you have 10 PRs to merge, you're spending 50-100 minutes on verification that would otherwise manifest as 4-8 hours of post-deployment debugging. The math strongly favors serialization.
Strategy 4: Define Explicit Overlap Zones
Not all overlapping file touches are equally risky. Changing a utility function that's called from 40 places is more dangerous than changing a leaf component used by one view. Teams that have operationalized parallel agent workflows often maintain an "overlap zone registry": a list of high-impact files and services that require special handling when an agent's task touches them.
When an agent's PR touches an overlap zone file, it triggers a mandatory human review before merge, regardless of whether CI passes. The overlap zone acts as a speed bump for risky changes, not as a general bottleneck.
Common overlap zones: authentication and authorization code, database migration files, shared configuration, API contract definitions, core business logic services. The overlap zone list is cheap to maintain and highly effective at catching the class of merge conflict that causes the worst behavioral regressions.
Strategy 5: Verify Behavior, Not Code, After Every Merge
The first four strategies reduce the frequency of subagent conflicts. The fifth strategy ensures you catch the ones that get through.
End-to-end behavioral testing after every merge is not a nice-to-have for teams running parallel AI agents. It's the mechanism that makes the whole system safe. Unit tests verify that individual functions work. Integration tests verify that connected components work. End-to-end behavioral tests verify that the deployed application does what it was supposed to do.
When Agent A's settings page PR merges cleanly but silently breaks the permission model that Agent B built, no unit test catches it. The permission service's unit tests still pass. The settings page's unit tests still pass. Only a test that logs in with a restricted role and tries to access a restricted setting catches the regression.
Autonoma integrates into your CI and runs these behavioral tests per PR against an isolated preview environment, either one Autonoma provides or your own. After each merge, it runs the full suite against the new deployment. If something behavioral has changed that shouldn't have, it surfaces immediately: before the change is live, before a customer encounters it, and while the merge history is short enough that the culprit merge is easy to identify.
The combination of serialized merging and post-merge behavioral verification is the practical answer to parallel AI agent workflow management. You don't need to eliminate parallelism to make it safe. You need to control the merge sequence and verify the results.
Putting It Together: A Practical Parallel Agent Workflow
Here's what a well-structured parallel agent session looks like in practice:
Before the session: Take a frozen snapshot of main. Decompose the sprint into scoped task units with minimal file overlap. Identify any overlap zone files each task touches.
During generation: Spawn agents from the frozen snapshot. Let them generate and test independently. Do not merge any PRs until all agents have completed (or a defined timeout has passed).
Merge phase: Sort PRs by risk (lowest overlap zone exposure first). Merge sequentially. After each merge, trigger behavioral verification against the preview deployment. If verification fails, stop the queue, investigate, and fix before proceeding. Do not merge the next PR on a broken baseline.
After the session: Update your task scoping model with what you learned. If two tasks created a conflict you didn't predict, adjust the file-scope mapping so it doesn't happen again.
This workflow is not fully automated yet. The task scoping and overlap zone decisions still require human judgment, but the merge sequence and the post-merge verification can be fully automated, and that's where most of the safety value lives.
Teams that have adopted this pattern report a shift in where they spend their debugging time: from "tracking down what happened after a bad deploy" to "catching behavioral mismatches during the merge phase." The total debugging effort is lower. The signal arrives earlier. And the product that gets shipped is the product that was designed.
Parallel AI agent PRs are pull requests generated by multiple AI coding subagents working simultaneously on the same repository. They're risky because each agent works from a frozen snapshot of the codebase and has no awareness of what parallel agents are building. When their PRs touch overlapping code and merge, features can be silently dropped or broken without any compilation error or test failure.
Scope each agent's work to a single directory boundary, service, or data model. The goal is to minimize file overlap between agents. Use a dependency graph to map each task to the files it will likely touch before assigning tasks to agents. Only run tasks in parallel if their expected file sets are disjoint or nearly so.
A serialized merge queue means merging PRs one at a time: merge one PR, run behavioral verification, confirm the application works correctly, then merge the next. This prevents compounding conflicts where each merge introduces a slightly different regression. The verification step is critical: CI alone won't catch behavioral regressions from subagent merge conflicts.
Include high-impact files that are touched by many parts of the codebase: authentication and authorization code, database migration files, shared configuration, API contract definitions, and core business logic services. When an agent's PR touches an overlap zone file, trigger a mandatory human review before merging, regardless of CI results.
Autonoma integrates into your CI and runs end-to-end behavioral tests per PR in an isolated environment. It either provides the preview environment or plugs into yours. This catches the silent behavioral regressions that parallel AI agent merges introduce, before they reach production.