
Agentic testing (also called autonomous testing) is a category of AI-powered test automation where AI agents generate, execute, and maintain tests autonomously by reading your codebase rather than requiring humans to write scripts. Traditional test automation (Selenium, Cypress, Playwright) requires engineers to write and maintain every test case manually. The architectural difference is fundamental: scripted tools execute instructions a human wrote; agentic tools derive tests from code analysis and self-heal when the application changes. This article compares both approaches head-to-head across test creation, maintenance burden, flakiness handling, CI/CD integration, debugging, cost, and learning curve, and maps a realistic migration path from scripted to agentic.
At some point, every engineering team with a mature Playwright or Cypress suite hits the same wall. The suite is large enough that maintenance is a real line item. Flaky tests are a recurring source of pipeline noise. A new engineer joining the team spends their first two weeks learning the testing conventions, not shipping features. The suite that was supposed to speed you up is slowing you down.
This is not a discipline problem. It is what happens when scripted automation scales. The architecture that makes traditional tools predictable and explicit is the same architecture that makes them expensive to maintain at volume.
This article gives you an honest, head-to-head comparison of both approaches. It includes the places where agentic testing tools are not yet ready, a realistic ROI model, and a phased migration path so you can make the call for your specific situation.
What Changes Architecturally With Agentic Testing
The phrase "AI testing" gets applied to two very different things. Understanding the distinction is the only way to evaluate vendor claims accurately.
The first category is AI-assisted scripting. Tools in this bucket use AI to help you write Playwright or Selenium code faster: autocomplete, natural language to test stub, selector suggestions. The test is still a script. A human still decides what to test, writes the assertion, and maintains the selector when the UI changes. The architecture is identical to traditional automation.
The second category is what agentic testing actually means. Instead of a human authoring a test script, an agent reads your codebase and derives test cases from it. The routes, components, and data models in your code become the spec. The agent plans which flows to cover, executes them against the running application, and updates the tests when your code changes. No human writes the test. No human runs maintenance when a selector changes.
This changes three things fundamentally. First, test creation is no longer a labor-intensive authoring step; it happens automatically when you connect your codebase. Second, test maintenance is no longer a recurring cost; the agent heals tests when the application changes. Third, coverage gaps are no longer a consequence of how much time your QA team has; they are a function of how completely your code describes your application's intent.
What does not change: you still need CI/CD integration, you still need meaningful assertions, and you still need someone who understands the results when something fails. The observability layer is different, but the engineering judgment required to act on a test failure does not go away.
Where Traditional Automation Excels (And Why That Still Matters)
Before going further, it is worth being precise about what traditional test automation tools do well, because the migration conversation only makes sense with an honest baseline.
Playwright, Cypress, and Selenium are mature. Playwright in particular has become the default choice for new projects because of its speed, reliability, and first-class TypeScript support. For a detailed Playwright vs Cypress comparison, see our dedicated analysis. The ecosystem is large. The debugging tooling is excellent. Your engineers already know it.
More importantly: the tests you write in these tools are fully deterministic and fully inspectable. When a Playwright test fails, you have a trace file, screenshots, and a network log. You can reproduce it locally in ten seconds. The failure surface is exactly the code you wrote.
Traditional scripted tests also work well for low-change surfaces. If you have a stable payments flow with five well-defined happy paths that has not changed in two years, a Playwright script for that flow is probably the right tool. It costs nothing to maintain and it runs in two seconds.
The issue is not with the tools. The issue is with the maintenance model at scale, and it compounds with the speed at which AI-assisted development now produces code changes.
The Maintenance Cliff: Where the Cost Calculus Shifts
The comparison between agentic and traditional automation is not interesting at 50 tests. It becomes interesting at 500, and it becomes urgent at 2,000.
When a team ships one PR per engineer per day and each PR touches one to three components, a test suite of 500 Playwright tests requires roughly four to six hours of maintenance per sprint. Manageable. When the same team adopts an AI coding tool (Cursor, Copilot, Claude Code) and ships three to four PRs per engineer per day, each touching a broader surface area, that same test suite requires twenty to thirty hours of maintenance per sprint. This problem is even more acute for vibe-coded applications where output velocity is highest. That is a full-time QA role consumed entirely by keeping existing tests green. If that math sounds familiar, explore our plans — Autonoma's self-healing agents eliminate the maintenance cliff.
This is the maintenance cliff. It is not a failure of Playwright. It is a structural consequence of a fixed-script model meeting an accelerating codebase. The more code your team ships, the more expensive your test suite becomes to maintain.
Agentic testing inverts this relationship. Because the agents derive tests from the codebase and self-heal when it changes, the maintenance burden does not scale linearly with output velocity. Adding autonomous testing does not add a maintenance backlog; it continuously closes coverage gaps.
The flip side: agentic systems require trust. A self-healing test has to make a judgment call about whether a change represents expected behavior or a regression. That judgment is increasingly reliable, but it is not perfect. Understanding when to override it is part of the learning curve.
Agentic Testing vs Traditional Automation: Head-to-Head
The table below compares traditional scripted automation (Playwright as the representative) against autonomous testing across the dimensions engineering leaders care about most.
| Dimension | Traditional (Playwright / Cypress) | Agentic Testing |
|---|---|---|
| Test creation | Engineers write scripts manually; AI-assist tools speed authoring but do not eliminate it | Agents derive tests from codebase analysis; no human authoring required for initial coverage |
| Maintenance model | Every selector, assertion, and flow must be updated manually when the application changes | Self-healing: agents update tests automatically when code changes; human review for ambiguous cases |
| Flakiness handling | Manual retry logic, wait strategies, and environment isolation required; flakiness is endemic at scale | Agents re-verify on failure and distinguish environmental noise from real regressions; see flakiness best practices |
| CI/CD integration | Native: all major CI systems support Playwright/Cypress out of the box; rich plugin ecosystem | Same: agentic platforms integrate with GitHub Actions, GitLab CI, CircleCI via standard webhooks and CLI |
| Debugging failed tests | Excellent: trace files, screenshots, network logs, local reproduction in seconds | Improving: agent execution logs and session replays available; local reproduction requires replay tooling |
| Initial setup cost | Low to medium: framework well-documented; first test runnable in under an hour | Medium: requires codebase connection and initial agent run; first results in hours rather than minutes |
| Coverage at scale | Proportional to QA investment: coverage grows only when someone writes new tests | Proportional to codebase completeness: coverage expands automatically as new routes and flows are added |
| Database / state setup | Manual: fixtures, factories, and seed scripts written and maintained by engineers | Automated: Planner agent generates the endpoints needed to put the database in the correct state for each test scenario |
| Learning curve | Low: TypeScript familiarity transfers directly; large community; most engineers already know it | Medium: understanding agent behavior, reviewing self-heal decisions, and setting coverage policies takes time |
| Cost model | Open-source tooling is free; cost is engineer time (authoring + maintenance) | Platform fee; engineer time cost drops significantly as maintenance burden moves to agents |
The comparison is not a clean "agentic wins." CI/CD integration is essentially the same. Debugging is still better in Playwright. The learning curve for agentic tools is higher. The categories where agentic testing has a structural advantage are test creation, maintenance, coverage at scale, and database state management: exactly the categories where traditional tools consume the most engineering time.
What Stays the Same
A lot of the anxiety around adopting agentic testing comes from imagining a full rip-and-replace. That is not how the category actually works, and it is not how teams successfully adopt it.
The fundamentals of good testing do not change. You still need meaningful assertions that reflect real user value, not just "the page loaded." You still need meaningful coverage of your critical paths, not just the paths that are easy to test. You still need someone who understands the difference between a failing test that indicates a real bug and a failing test that indicates a misconfigured environment.
CI/CD integration stays the same. Agentic platforms connect to GitHub Actions, GitLab CI, and CircleCI via the same mechanisms as Playwright. Pull request checks, blocking deploys on failure, Slack notifications: all identical.
Reporting stays the same. Engineering leaders still want a dashboard that shows pass/fail by suite, trend over time, and flakiness rates. Agentic platforms provide this. The underlying data is richer (agent execution logs, self-heal audit trails), but the reporting format is familiar.
What changes is who creates and maintains the tests, and how quickly the test suite reflects the current state of the application. For teams where that gap (between "how the application works" and "what the tests cover") is small and stable, the value is lower. For teams where that gap is large and growing, the value compounds quickly.
ROI: Realistic Numbers
The ROI conversation for agentic testing usually collapses into vague claims about "saving QA time." Here are the actual cost drivers, with realistic ranges.
A mid-market SaaS team with 10 engineers and a test suite of 800 Playwright tests typically spends:
A senior QA engineer at $130,000-$170,000 per year spends roughly 35-40% of their time on test maintenance when a team is actively shipping. At 800 tests and moderate velocity, that is $45,000-$68,000 in annualized maintenance labor per QA FTE. Teams with two QA engineers are spending $90,000-$136,000 per year keeping their test suite green, before accounting for the engineering time when developers have to fix broken tests in their own PRs.
The platform cost for an agentic testing tool is typically in the $2,000-$8,000 per month range depending on team size and execution volume, which annualizes to $24,000-$96,000. The maintenance labor drops to roughly 10-15% of the QA role (reviewing self-heal decisions and setting coverage policy) rather than 35-40%.
At the low end, the economics are approximately neutral. At the high end (fast-moving teams with large test suites and multiple QA engineers), the maintenance savings materially exceed the platform cost. The more important ROI factor for most engineering leaders is velocity: teams that reduce maintenance burden ship features faster because QA is not a bottleneck.
Where Agentic Testing Is Not Ready Yet
Building trust requires honesty, so here is the part of the assessment that the vendor pitch decks leave out.
Debugging experience is immature. When a Playwright test fails, you have a trace file and you can reproduce it in ten seconds. When an agentic test fails, you have session logs and execution replays, but the debugging workflow is less familiar and less fast. Teams that rely heavily on test failures as debugging starting points (rather than just pass/fail signals) will find the transition friction higher. This is the category improving fastest, but it is a real gap today.
Highly custom test logic does not transfer. If you have tests that encode complex business rules, multi-tenant permissioning logic, or financial calculation assertions that took months to specify correctly, an agentic system starting from your codebase may not capture the full depth of those assertions in the initial pass. Hybrid coverage (agentic for coverage breadth, hand-authored for critical business logic) is a more realistic model for these cases.
New application categories are harder. Agentic testing derives intent from code. If your application is primarily an API with a thin frontend, agent coverage is strong. If your application has complex real-time collaborative features, heavy WebRTC usage, or interactions that span multiple device sessions simultaneously, the coverage model is less complete. These are edge cases, but they are real.
Trust takes time. Self-healing means an agent is making a judgment call about whether a change is intentional. Early in a deployment, those calls require more human review. Teams that are not willing to invest two to four weeks in calibrating the system will undervalue it.
None of these are disqualifying for most teams. They are the honest constraints that should shape how you sequence adoption.
Agentic Testing Maturity Model: Where Is Your Team?
Rather than asking "should we adopt agentic testing," the more useful question is "where are we on the automation maturity spectrum, and what is the right next step?"
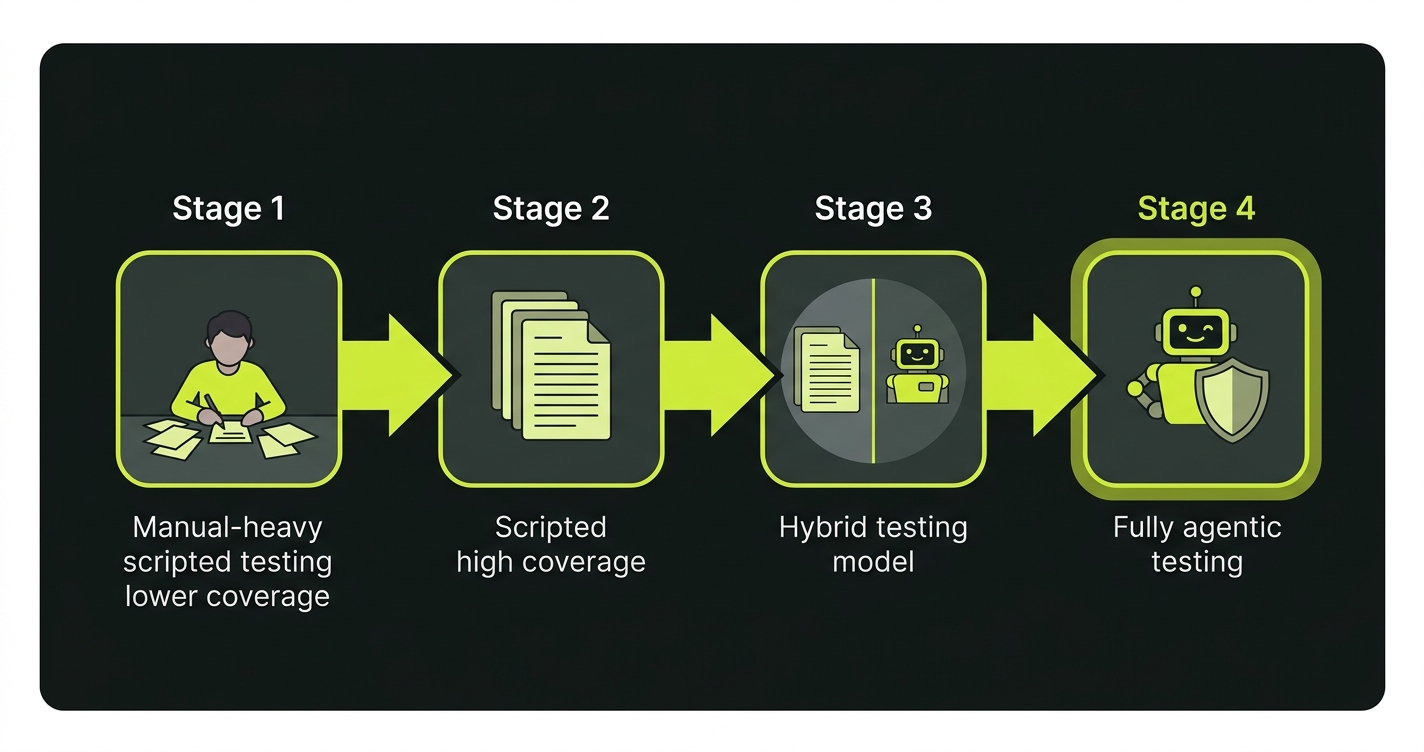
Stage 1: Scripted, manual-heavy. Most tests are written by QA as manual test cases. Automation coverage is below 40%. The biggest constraint is not maintenance; it is creation. At this stage, either scripted automation or agentic testing accelerates you. Agentic has a faster path to coverage if you have a well-structured codebase.
Stage 2: Scripted, high coverage. A mature Playwright or Cypress suite with 60-80% coverage of critical paths. The team is hitting maintenance friction. Sprints include test-fix work that should be feature work. This is the profile where the agentic value proposition is strongest. A hybrid approach (keep existing scripts for stable critical paths, use agentic tooling for new coverage and maintenance) is the lowest-risk entry point.
Stage 3: Hybrid. Agentic agents handle routine coverage and self-healing. Hand-authored tests cover the highest-stakes business logic where the precision of a human-specified assertion is worth the maintenance cost. Most mature teams end up here. It is not a stepping stone to "fully agentic"; for many codebases it is the right steady state.
Stage 4: Fully agentic. The full test lifecycle (planning, execution, maintenance) is owned by agents. The QA function shifts from test authoring to coverage policy and failure review, which is what autonomous QA looks like in practice. This is the right destination for teams whose codebase is the authoritative spec for their application's behavior.
For a broader look at the AI testing tools landscape, including where traditional tools and agentic testing platforms each sit, that guide maps the category in more detail.
Migration Path: Not Rip-and-Replace
The practical migration from traditional to agentic testing has four phases. Each phase is independently valuable, so you can stop at any point if the ROI calculation changes.
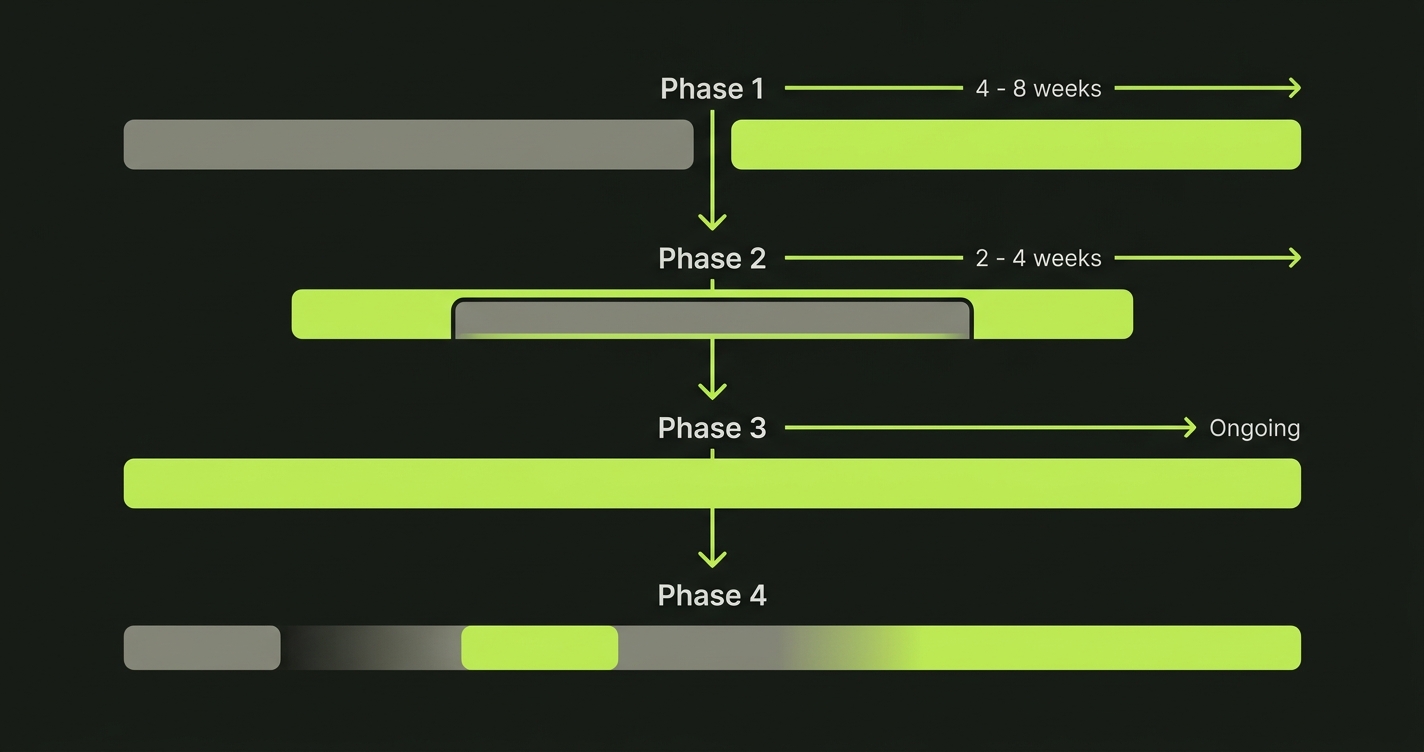
Phase 1: Parallel coverage. Keep your existing Playwright suite running. Add agentic coverage for new features only. This generates a direct comparison of agentic test quality against your existing tests on the same application surface. It also surfaces false positive rates without putting your existing coverage at risk. Duration: four to eight weeks.
Phase 2: Maintenance handoff. Once you trust the agentic tool's self-heal quality on new coverage, extend it to maintain your existing Playwright scripts as well. Some agentic platforms can ingest existing test files and manage maintenance from that baseline. Duration: two to four weeks.
Phase 3: Coverage expansion. Use the agentic system to fill coverage gaps in areas where you have no existing tests. This is typically the highest ROI phase because you are getting new coverage without any authoring cost. Duration: ongoing.
Phase 4: Selective consolidation. Retire Playwright scripts that are fully superseded by agentic coverage. Keep the hand-authored tests that encode business logic too complex for the agent to derive from the codebase alone. This is not an obligation; many teams run both indefinitely.
If you are evaluating where to start with Selenium alternatives or Playwright alternatives that include agentic options, the framework context in the test automation frameworks guide maps the decision criteria clearly.
Autonoma in This Stack
We built Autonoma specifically for the Phase 2 and beyond scenario described above: teams that have already invested in traditional automation and are hitting the maintenance cliff at scale.
The architecture is three specialized agents. The Planner agent reads your codebase and derives test cases from your routes, components, and data models. It also handles database state setup automatically, generating the endpoints needed to put your application in the right state for each scenario. The Automator agent executes those test cases against your running application with verification layers at each step, so execution paths are consistent rather than probabilistic. The Maintainer agent watches for code changes and self-heals tests when the application evolves.
The result is that connecting your codebase to Autonoma generates an initial test suite without anyone authoring a script. As you ship, the Maintainer agent keeps tests passing. The QA function shifts from "write and maintain test scripts" to "review coverage policy and triage failures." See pricing to compare tiers.
We designed it to coexist with existing Playwright and Cypress suites, not to replace them on day one. The AI for QA context explains the broader role that AI plays across the QA function, including where agent-based testing fits versus AI-assisted scripting.
What to Do With This
If you are an engineering lead evaluating this category, the decision criteria are straightforward.
If your maintenance burden is below 20% of QA bandwidth and your team has strong Playwright coverage, the ROI case is not urgent. File this for six months from now.
If your maintenance burden is above 30% of QA bandwidth, if your team is shipping faster than QA can cover, or if you are considering hiring a QA engineer primarily to maintain existing tests rather than to design new coverage, that is the signal that autonomous testing deserves evaluation. The maintenance cliff is already affecting your velocity.
The right first step is not a full platform evaluation. It is running a four-week parallel coverage experiment on one application surface: run agentic coverage alongside your existing tests, measure the false positive rate and the maintenance time saved, and let the data make the case (or not).
The tools are mature enough for production use in most standard web application contexts. The question is whether your team's specific constraints (debugging workflow, custom business logic, edge case application types) are in the category where the gaps still matter. Start free and run a parallel coverage experiment on one surface.
AI-assisted test automation uses AI to help engineers write test scripts faster: autocomplete, natural language to test stub, selector suggestions. The output is still a manually-authored script that a human maintains. Agentic testing uses AI agents that read your codebase, derive test cases autonomously, execute them, and self-heal when the application changes. No human writes the test script. The architectural difference is fundamental: one accelerates manual authoring, the other replaces it.
For most teams, a hybrid model is more realistic than full replacement. Agentic tools handle coverage breadth and maintenance automatically. Hand-authored Playwright tests remain the right choice for high-stakes business logic that requires precisely specified assertions. Over time, teams typically retire Playwright tests where agentic coverage is complete, while keeping custom tests for complex scenarios.
This is one area where agentic testing has a genuine structural advantage. Traditional automation requires engineers to write and maintain fixtures, factories, and seed scripts manually. In Autonoma's architecture, the Planner agent automatically generates the endpoints needed to put the database in the correct state for each test scenario. Database state management becomes part of the test planning process rather than a separate infrastructure task.
The biggest risk is underinvesting in the calibration period. Self-healing means the agent makes judgment calls about whether a change is intentional or a regression. Early in a deployment, those calls require more human review. Teams that skip this calibration phase end up either over-trusting the system (missing real regressions) or under-trusting it (ignoring self-heal decisions that are actually correct). Budget two to four weeks of active review before treating the system as fully autonomous.
Agentic testing platforms integrate with standard CI/CD systems (GitHub Actions, GitLab CI, CircleCI, Jenkins) via webhooks and CLI. Pull request checks, blocking deploys on failure, and Slack/PagerDuty notifications work identically to how they work with Playwright or Cypress. The integration layer is not where the architectural difference lies.
Yes. AI testing tools based on agentic architectures are production-ready for most standard web application contexts: multi-page SaaS products, REST and GraphQL APIs, standard authentication flows, and CRUD-heavy applications. The areas where coverage is still maturing include real-time collaborative features, complex WebRTC interactions, and multi-session cross-device flows. For teams whose application falls in the mainstream, the tooling is production-ready.



