
Most no-QA-team startups already use Sentry. The question is not whether Sentry is useful. It is what layers does a no-QA-team safety net actually need, and which of them is Sentry the right shape for? Sentry is excellent at post-prod visibility. It is not the pre-deploy layer that proves a pull request still works before users touch it.
Autonoma is the pre-deploy testing layer for engineers shipping without a QA function. It helps teams catch bugs before they reach Sentry, while Sentry keeps doing the runtime monitoring job it is built for. Sentry catches what slips through. Both belong.
That distinction matters because many alternatives to Sentry articles collapse four different jobs into one list. Gartner-style, Betterstack-style, and G2-style pages are useful for vendor discovery, but they rarely explain layer fit for teams that say "we don't have any QA" and mean it literally. A cheaper error tracker, a synthetic monitor, a browser test suite, and a pre-deploy coverage layer are not interchangeable.
If your team is asking about a Sentry alternative because alerts keep finding product bugs after deploy, the practical question is not "which tool replaces Sentry?" It is "where should this failure have been caught first?" For no-QA startups, the answer is usually a layered safety net: pre-commit, pre-deploy, post-deploy, and post-prod. Sentry owns only one of those layers.
The four-layer safety net for no-QA teams
Teams without QA do not need a miniature enterprise test department. They need a safety net that matches how small teams actually ship: fast PRs, direct engineer ownership, thin release process, and production feedback that arrives fast. If something breaks, "we hear about it real quick" is not a testing strategy. It is a signal that the post-prod layer is doing its job after the user already paid the cost.
Here is the clean model.
| Layer | Question | Good tools | Sentry fit |
|---|---|---|---|
| Pre-commit | Did the code compile and pass local checks? | TypeScript, lint, unit tests | No |
| Pre-deploy | Does the changed product flow still work? | Autonoma, E2E checks | No |
| Post-deploy | Did the release land cleanly? | Synthetic checks, smoke tests | Partial |
| Post-prod | What failed for real users? | Sentry, logs, APM | Strong |
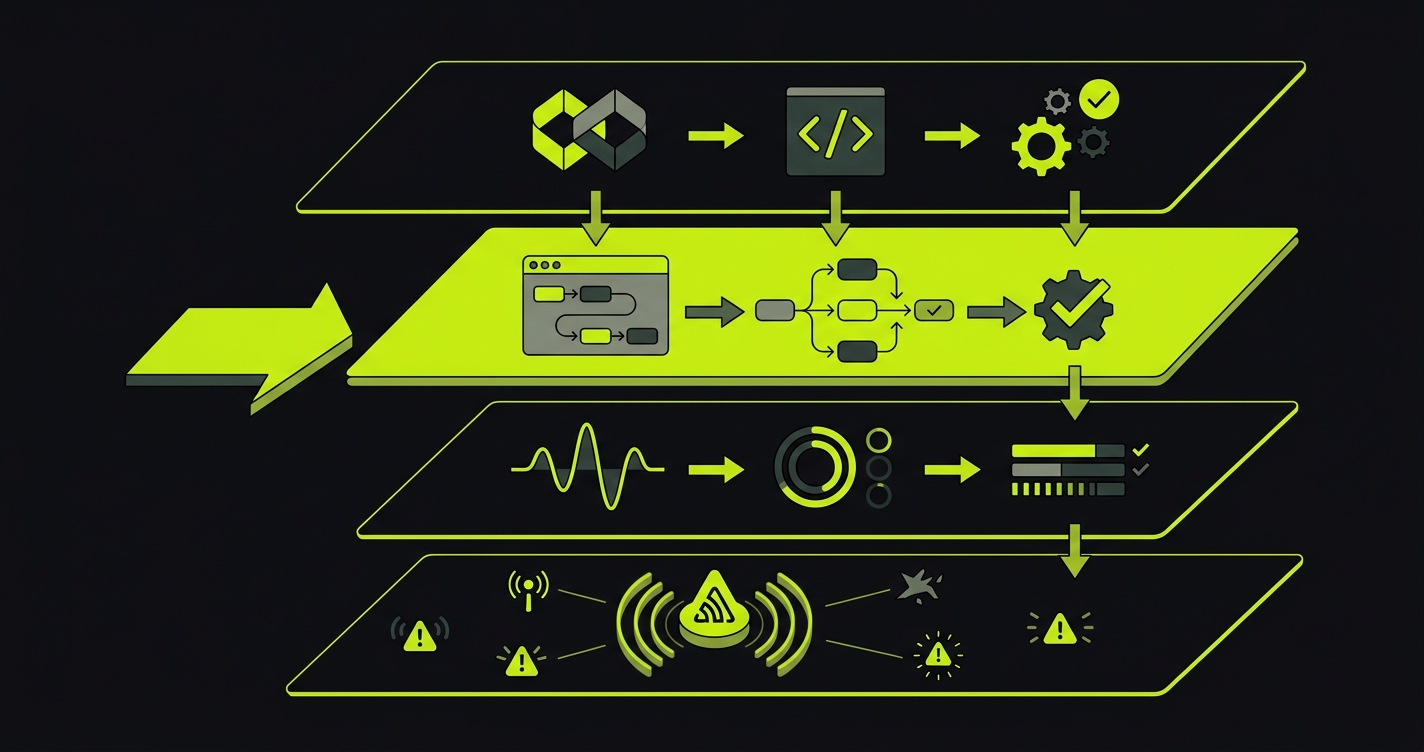
Pre-commit catches mistakes close to the editor. It is fast and precise, but it mostly sees code in isolation. A TypeScript error, a failing unit test, or a bad import should never wait for Sentry. This layer is table stakes.
Pre-deploy catches behavior in the running app before a release reaches users. This is where teams without QA feel the biggest gap. The code compiles, unit tests pass, CI is green, and the PR still breaks checkout, onboarding, permissions, billing, or a local to prod flow that was never covered by a unit test. That is the gap Autonoma is built for.
Post-deploy checks that the release is alive. A synthetic check can hit the homepage, log in, or exercise a small critical path after deploy. It is useful, but it is already downstream of merge. It answers "did we just break prod?" rather than "should we merge this?"
Post-prod monitoring observes real user failures. Sentry is excellent here. It gives stack traces, grouping, releases, source maps, alerts, and runtime evidence. For a small team, keeping Sentry is usually a no brainer because it tells you what escaped every upstream layer.
What an alternative should mean here
For a no-QA team, "alternatives to Sentry" should not mean "find a cheaper product with a similar dashboard." Sometimes that is the right buying motion, and the broader Sentry-alternatives listicle covers that comparison. But if the pain is product bugs reaching users, drop-in parity is the wrong promise.
The honest answer is layer complement. Sentry is post-prod monitoring. Autonoma is pre-deploy testing. A synthetic monitor is post-deploy confirmation. Unit tests are pre-commit precision. None of these layers can honestly replace all the others.
This is also why vendor-neutral comparison matters. Many vendors emphasize post-prod error visibility because it is easier to show: stack traces, session timelines, release markers, and dashboards. Those are valuable. They do not prove that a changed checkout path, invite flow, permission boundary, or upgrade screen still works before deploy.
If you are replacing Sentry because you need lower cost, SDK compatibility, or broader observability, compare monitoring vendors. If you are replacing Sentry because it keeps telling you about bugs customers hit first, the answer is not to drop Sentry. The answer is to add a pre-deploy layer upstream.
This is the practical buying distinction. A monitoring swap changes where production failures are reported. A safety-net upgrade changes when the team learns about the failure. If the same invite flow, checkout step, or onboarding path would still fail first in front of a user, the team did not solve the no-QA problem. It only changed the dashboard that receives the alert.
For small teams, the cleanest decision rule is this: replace Sentry only for post-prod monitoring reasons, and add upstream layers for upstream failures. If the team wants lower event cost, a simpler UI, or consolidated logs, compare runtime monitoring tools. If the team wants fewer production alerts caused by product-flow regressions, add pre-deploy testing. The second problem is where Autonoma fits.
Where Sentry ends and Autonoma starts
Sentry owns the evidence after code is live: production exceptions, stack traces, release-aware grouping, source maps, alerts, and debugging context. If a browser exception, backend exception, or release-specific runtime error happens in production, that is the monitoring layer to evaluate or improve.
Autonoma starts before that incident exists. It does not alert on prod stack traces, run session replay, reconstruct a user's production click path, or replace the runtime context an error-monitoring platform provides. It verifies user-facing web product flows before deploy, while the team can still decide whether code should ship.
That is the buying logic: compare Sentry alternatives when the missing job is runtime monitoring. Add Autonoma when the missing job is pre-deploy verification for checkout, onboarding, permissions, billing, or other web flows. The two products answer different questions in the release path.
Autonoma is also not a unit-test-level tool. If you need to prove a parser rejects a malformed value, a pricing function handles a decimal correctly, or a reducer returns the right state, unit tests are the right layer. Autonoma is for user-facing web flows where the browser, app state, and integrated product behavior matter.
When to drop Sentry
Drop Sentry when the problem is the monitoring layer itself: event cost, SDK fit, retention, alert routing, broader observability needs, or a maintained internal platform. In that case, compare runtime monitoring vendors and choose the product that best handles production evidence.
If the problem is product bugs reaching users before anyone catches them, the buying motion is different. Sentry is not failing at monitoring when it reports those bugs after production traffic hits them. It is revealing that the team is missing a pre-deploy verification layer upstream. That is where Autonoma fits.
For most startups without QA, the better move is to keep Sentry focused on production monitoring and add Autonoma where the release path is currently thin. Let pre-commit checks catch code-level mistakes. Let Autonoma catch web product-flow bugs before deploy. Let post-deploy checks confirm the release is alive. Let Sentry watch production. That layered model matches how bugs actually escape.
One more buying rule helps prevent tool confusion: decide what evidence you need before deciding which vendor to evaluate. If you need evidence from real production failures, you need Sentry or another runtime monitor. If you need evidence that a changed product flow still works before merge, you need a pre-deploy layer. If you need evidence that a small function is correct, you need unit coverage. No single dashboard makes those evidence types equivalent.
That is why the rest of this article goes deep on Autonoma only after naming Sentry's boundaries. Autonoma is useful precisely because it does not pretend to be a runtime monitor. It covers the missing point in the release path before the alert exists.
How to evaluate the safety net
Evaluate each layer by the decision it changes. Pre-commit checks decide whether code is internally consistent enough to leave the developer's machine. Pre-deploy checks decide whether a changed product flow is safe enough to merge. Post-deploy checks decide whether the new release is alive after rollout. Post-prod monitoring decides how fast the team can understand and repair failures that reached users.
That decision framing is more useful than asking which tool has the longest feature list. A runtime monitor can have excellent stack traces and still be the wrong answer for a checkout regression that should have failed before merge. A unit test suite can be fast and thorough while still missing a broken browser flow. A synthetic monitor can confirm the site is online while missing a role-specific permission bug. The layer has to match the failure mode.
For no-QA teams, the highest-risk gap is usually the moment between "CI passed" and "users are using it." That gap is where product behavior, integrated services, account state, and browser reality meet. It is also where small teams often rely on a founder, support lead, or engineer to click through the app from memory. That manual pass is fragile because it depends on who has time that day and what they remember to check.
The practical audit is simple. Take the last ten production bugs that mattered. For each one, ask which layer should have caught it first. If most of them were type errors or pure logic mistakes, strengthen pre-commit coverage. If most were broken product flows after a PR changed behavior, strengthen pre-deploy coverage. If most were release rollout failures, strengthen post-deploy checks. If most were unknown runtime exceptions, strengthen Sentry or the runtime monitoring layer.
Only after that audit should the team compare vendors. Otherwise "alternatives to Sentry" becomes a misleading search query. The real answer may be "keep Sentry and add the missing upstream layer."
How Autonoma fits in the no-QA-team safety net
The failure pattern is simple: a small team ships directly from engineer-owned PRs, has no dedicated QA function, and relies on Sentry to reveal breakage after production traffic finds it. Sentry is doing its job, but the organization is asking a post-prod monitor to compensate for a missing pre-deploy verification layer. That is why the alert feels late even when it is accurate.
Autonoma operates at the pre-deploy layer. It is not an API testing tool, unit test runner, native iOS or Android E2E tool, scraping library, test management platform, request builder, click-and-record tool, plain-language test builder, or Sentry replacement. It is the layer that reads the web app, builds runnable E2E coverage, reruns important flows before deploy, and gives engineers a reviewed signal they can act on before users are involved.
The workflow is easiest to understand as four plain-English phases: Planner, Generation, Replay, and Reviewer.
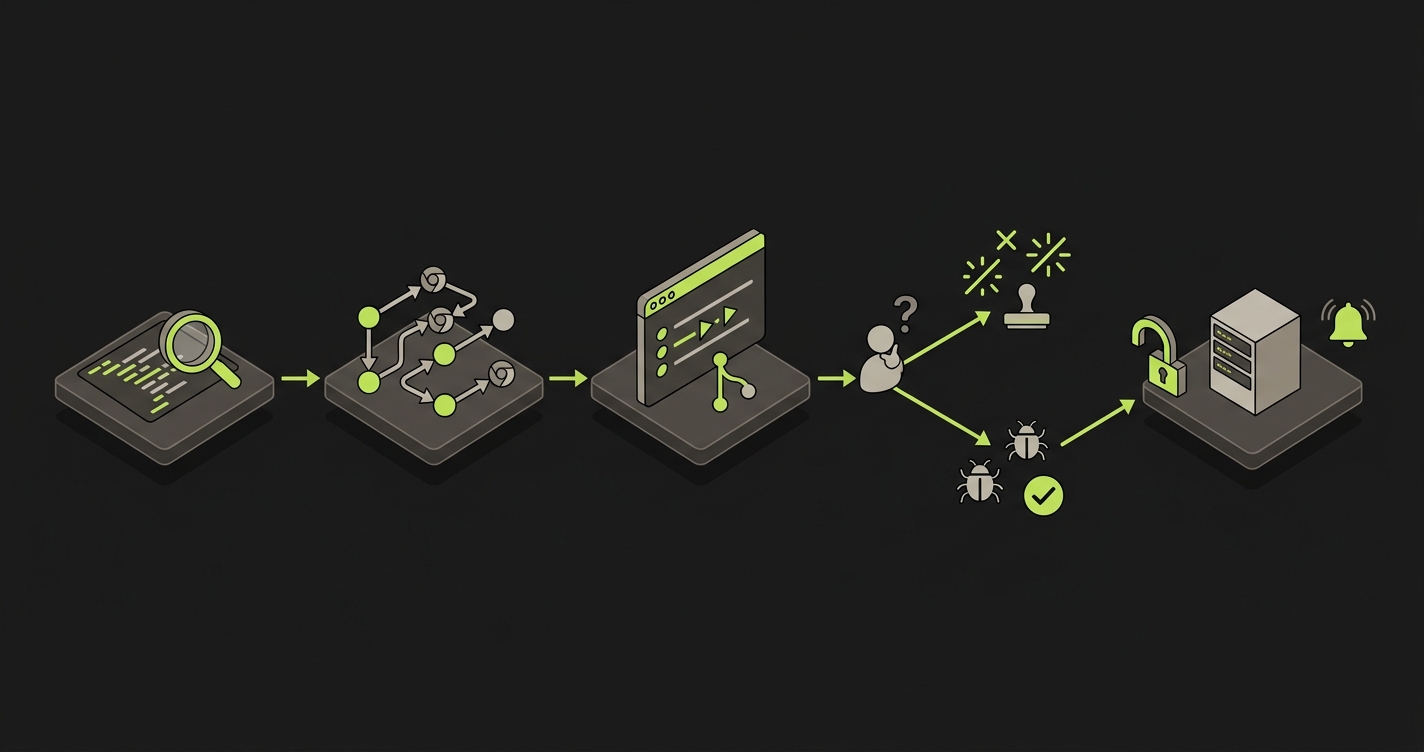
Planner reads the codebase. It looks at routes, components, forms, user flows, and the product structure implied by the code. The point is not to ask a founder, PM, or engineer to write a giant test checklist. The codebase is the spec. For a no-QA team, that matters because the product surface changes faster than any manually maintained spreadsheet.
Planner also has to understand state. A meaningful test is rarely just "visit page and click button." The flow may need a logged-in user, an existing workspace, a paid plan, a project with collaborators, a file already uploaded, or an invitation in a specific status. If the state is wrong, the test is theater. Autonoma plans tests with the setup needed to make the flow real instead of asking engineers to hand-wire every fixture.
Generation turns those plans into runnable coverage. This is where the pre-deploy layer becomes concrete. The team is not just getting a recommendation that "billing should be tested." It gets executable coverage for the product behavior the PR can affect. For a team saying "we don't have any QA," that is the difference between a quality ambition and a release gate.
Generation is also where Autonoma stays honest about scope. It is web E2E coverage. It does not replace unit tests for small pure functions. It does not replace API contract testing for backend-only surfaces. It does not turn into a mobile device lab for native iOS or Android. It covers product behavior where a user-facing web flow has to work before the deploy goes out.
For example, a pricing-page copy change may not need Autonoma. A checkout change that touches plan selection, payment handoff, account state, and confirmation messaging does. A button color change may be handled by review. A permissions change that affects who can invite teammates should be exercised as a running product flow. The point is not maximum test volume. The point is putting coverage on the paths where a small team would otherwise discover breakage through a Sentry alert or a customer message.
Replay reruns those flows against the environment that represents the release path, whether the team uses a preview URL, a branch environment, or a local to prod stack. The important part is timing: the check runs before the release becomes a real-user incident. Sentry cannot do that because Sentry observes runtime failures after code is already in production.
Replay also protects against the common "it worked locally" gap. A feature can pass local checks and still fail when services, auth, database state, browser behavior, and build output meet each other. That is why pre-deploy E2E coverage is different from pre-commit testing. It verifies the product as a running product.
Reviewer separates product bugs from noise for engineers. This matters because small teams do not have spare hours to triage flaky output. A raw browser failure is not enough. Engineers need to know whether the finding is a real product bug, a test artifact, an environmental issue, or a low-signal failure that should not block the release.
That review step is the difference between adding confidence and adding another dashboard. No-QA teams already have plenty of places where red status can appear. They need fewer ambiguous alerts, not more. The useful pre-deploy layer says: this flow failed, this is the likely product consequence, and this is why the engineer should look before merge.
This also keeps the engineering feedback loop short. When a failure appears before merge, the author still has the code path, product context, and implementation details in memory. When the same failure appears in Sentry two days later, the team has to reconstruct the release, inspect the stack trace, check whether users were affected, and decide whether to patch forward. Sentry helps with that work, but the work is still downstream. Autonoma is meant to move the discovery point earlier.
The other advantage is coverage drift. Manual suites tend to lag behind the product because no one owns maintenance on a team without QA. A flow changes, a selector changes, a required field appears, and the old test either fails noisily or gets skipped. Autonoma's pre-deploy role is to keep runnable coverage tied to the current code and product surface, not to preserve a stale checklist from three quarters ago.
Autonoma does not replace Sentry. It helps catch bugs before they reach Sentry. Sentry remains the runtime layer for production stack traces, grouping, release correlation, and the bugs that slip through. The complete safety net has both: Autonoma upstream of deploy, Sentry downstream of real traffic.
This complement is the practical takeaway for startups. If you currently ship with TypeScript, unit tests, CI, and Sentry, your weakest layer is usually not post-prod visibility. It is pre-deploy product verification. Adding another post-prod dashboard may improve triage, but it will not stop the same class of product bug from reaching users. Adding a pre-deploy layer changes where the bug is discovered.
It also changes the team workflow. Instead of assigning one engineer to manually click through the app on Friday, the PR itself carries the verification burden. Instead of waiting for Sentry to prove that a flow failed in production, the team gets a signal while the code is still cheap to change. Instead of making QA a role that the company has not hired yet, the team moves the most repetitive verification work into the release path.
For deeper context on this operating model, the shift-left testing for small engineering teams article explains why small teams should move meaningful checks closer to PR review. The autonomous testing platform article explains the broader category of generated E2E coverage. This post is narrower: in a no-QA safety net, Autonoma covers pre-deploy testing and Sentry covers post-prod monitoring.
The honest limitation is that Autonoma cannot make every quality problem disappear. It will not tell you whether a feature was strategically correct. It will not replace a product manager reviewing copy. It will not catch every backend invariant better served by unit or integration tests. It will not replace incident response after something breaks in production. It is the pre-deploy product-flow layer, not the entire engineering quality system.
That boundary is why the layer model is useful. Once the team names the layer, the purchasing decision gets cleaner. If the missing layer is post-prod monitoring, keep or improve Sentry. If the missing layer is pre-deploy product verification, add Autonoma. If the missing layer is unit-level correctness, write tests closer to the code. If the missing layer is release health, add synthetic post-deploy checks. Confusing those layers is how teams buy tools that do not solve their actual failure mode.
A useful implementation pattern is to start with the flows that would embarrass the team if they failed in front of a customer: signup, login, invite, upgrade, checkout, file upload, export, permissions, and the one workflow your sales team demos every week. Those are the flows where "we hear about it real quick" usually means a founder, support lead, or customer-facing engineer gets pulled into emergency triage. Put those flows into pre-deploy coverage first, then expand only when the signal stays clean.
FAQ
Usually no. A no-QA-team startup should keep Sentry for post-prod monitoring unless it is intentionally moving to another runtime monitoring product. If the pain is bugs reaching users before anyone notices, add a pre-deploy layer instead of removing Sentry.
A no-QA-team safety net is the set of checks that catches failures across pre-commit, pre-deploy, post-deploy, and post-prod layers. Type checks and unit tests cover pre-commit, Autonoma covers pre-deploy product-flow testing, synthetic checks cover release health, and Sentry covers post-prod monitoring.
Autonoma replaces the missing pre-deploy verification layer, not Sentry's post-prod monitoring layer. Autonoma is pre-deploy testing for web product flows. Sentry is post-prod monitoring for runtime errors, stack traces, release grouping, alerts, and production debugging.
Sentry fits at the post-prod layer. It tells the team what failed for real users after code is live. That makes it valuable, but it should be paired with upstream checks that catch bugs before production.
Sentry does not prove a pull request works before deploy. It does not replace unit tests, pre-deploy E2E testing, release smoke checks, or human product judgment. It is strongest as runtime monitoring after production traffic hits the app.



