
Self-healing tests repair test drift when the product changes, but no-QA teams need them to heal loudly, not silently. If a selector swap is accepted without an intent check, the suite can keep passing while clicking the wrong control, and a real product bug stays hidden because nobody is reviewing the test.
Autonoma's job is to self-heal loudly for engineers shipping without a QA team. A heal should not be a quiet rewrite that makes the dashboard green. It should be a reviewable event that says what changed, what still matched the user's intent, and what needs an engineer's attention before the release moves forward.
That distinction is the whole article. Self healing test automation is useful when it removes maintenance noise. It is dangerous when it removes feedback. For a team that says "we don't have any QA", the tool cannot assume a QA reviewer will inspect every changed locator, failed replay, or questionable replacement after the fact.
Why self-healing matters more for no-QA teams
In a larger company, a broken E2E test usually lands in a workflow with owners. Someone on QA, release engineering, or product engineering looks at the failure, decides whether the app or the test changed, and updates the suite. The cost is annoying, but there is a human-in-the-loop by default.
Small teams do not have that buffer. They ship from engineer-owned PRs, use TypeScript and unit tests for obvious correctness, keep Sentry for production visibility, and manually click the app when someone remembers. When something breaks in production, the internal story is often "we hear about it real quick." That usually means a customer, founder, support channel, or sales demo found the regression first.
Silent self-healing makes that operating model worse. If a brittle selector fails and the system quietly swaps to another button, you do not even hear about it real quick. The failure disappears from the only pre-deploy signal the team had. Nobody reviews the replacement. Nobody asks whether the test still proves the business outcome. The green check can mask the exact class of bug the team wanted self-healing e2e tests to catch.
The right bar is not "never heal." That would throw away real leverage. UI labels move. Components get refactored. DOM structures change. A good system should recover from safe mechanical drift so engineers are not burning hours on locator maintenance. The right bar is "heal only when intent still matches, and flag loudly when intent is uncertain."
This is why the no-QA context changes the risk profile. In a QA-heavy workflow, a questionable heal may still get caught in test review. In a no-QA workflow, the system is often the review layer. It has to preserve feedback, not only preserve pass rates.
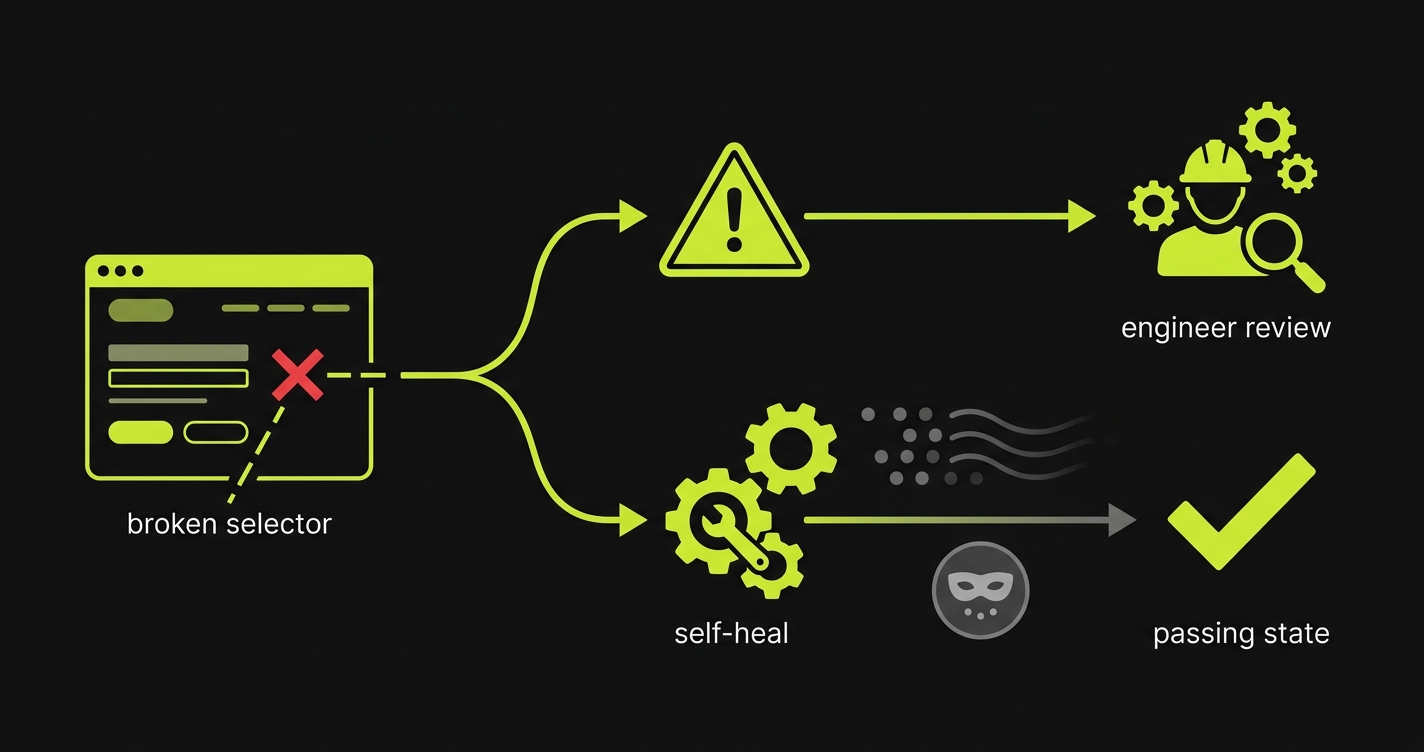
Failure modes for teams without a human-in-the-loop
Most self-healing failures are not dramatic. They are small, plausible decisions that look helpful until they erase the signal the team needed.
The first mode is silent selector swap (Generation 1). A selector breaks, the system finds another nearby element, and the test proceeds. That can be fine if a button changed from Save to Save changes and the resulting state is identical. It is not fine if the test now clicks Cancel, Archive, or a visually similar action in another panel. The selector healed, but the user intent did not.
The second mode is healed-into-the-wrong-button. This is the concrete version engineers fear. A test meant to submit an invite lands on a different button after a layout change. The browser run keeps moving, maybe even reaches a success-looking screen, but the teammate was never invited. The self-heal is worse than a failure because it converted a broken flow into false confidence.
The third mode is heal-on-spec-drift. The product intentionally changes behavior, but the test keeps trying to prove the old rule. Maybe the team removed a required field, moved an approval step, or changed the checkout path. A self-heal that forces the old path to pass is not maintenance. It is denial. The test should flag that the app's behavior changed relative to the old expected outcome.
The fourth mode is heal-without-confidence-signal. The system may have selected a replacement that is probably right, but it does not expose why. Engineers cannot see whether the match came from label similarity, role, DOM position, visual context, URL state, final assertion, or observed outcome. Without that signal, a no-QA team cannot decide whether to trust the heal, rerun it, or review the product change.
These modes matter because teams without QA are often trying to catch bugs before they reach production while also moving fast. They need fewer flaky failures, but they cannot afford fewer meaningful failures. The goal is not a suite that always passes. The goal is a suite that tells the truth about the product flow.
Signal semantics for healed vs flagged
How Autonoma signals healed vs flagged
Autonoma treats a heal as a claim about intent, not just a claim about a locator. In plain English, the system asks: did the alternative step still do the thing this test was trying to prove? If the expected intent was "invite a teammate", the candidate action needs to look like the invite action and produce invite-related evidence. A nearby clickable element is not enough.
That comparison uses the surrounding product context. The label, role, accessible name, page state, route, nearby form fields, and final outcome all matter. If a button moved but still submits the same form and the post-action state proves the invite exists, the run can be marked as healed. If the replacement changes the action, skips the side effect, or leaves the outcome ambiguous, the run should be flagged.
For the deeper mechanism discussion, see the May 4 mechanism deep-dive on AI self-healing test automation. This article is narrower: it focuses on what a no-QA team needs to see when ai self healing tests recover from drift without a dedicated reviewer waiting downstream.
The useful output is a difference in semantics. Healed means Autonoma found an alternative path and the evidence still supports the original user intent. Flagged means Autonoma found drift, but the evidence is not strong enough to treat the new path as equivalent. That distinction lets engineers spend review time where ambiguity lives.
This is also where silent self heal becomes a product risk, not just a testing preference. A silent heal optimizes for fewer red builds. A loud heal optimizes for trustworthy feedback. For no-QA teams, trustworthy feedback is the product.
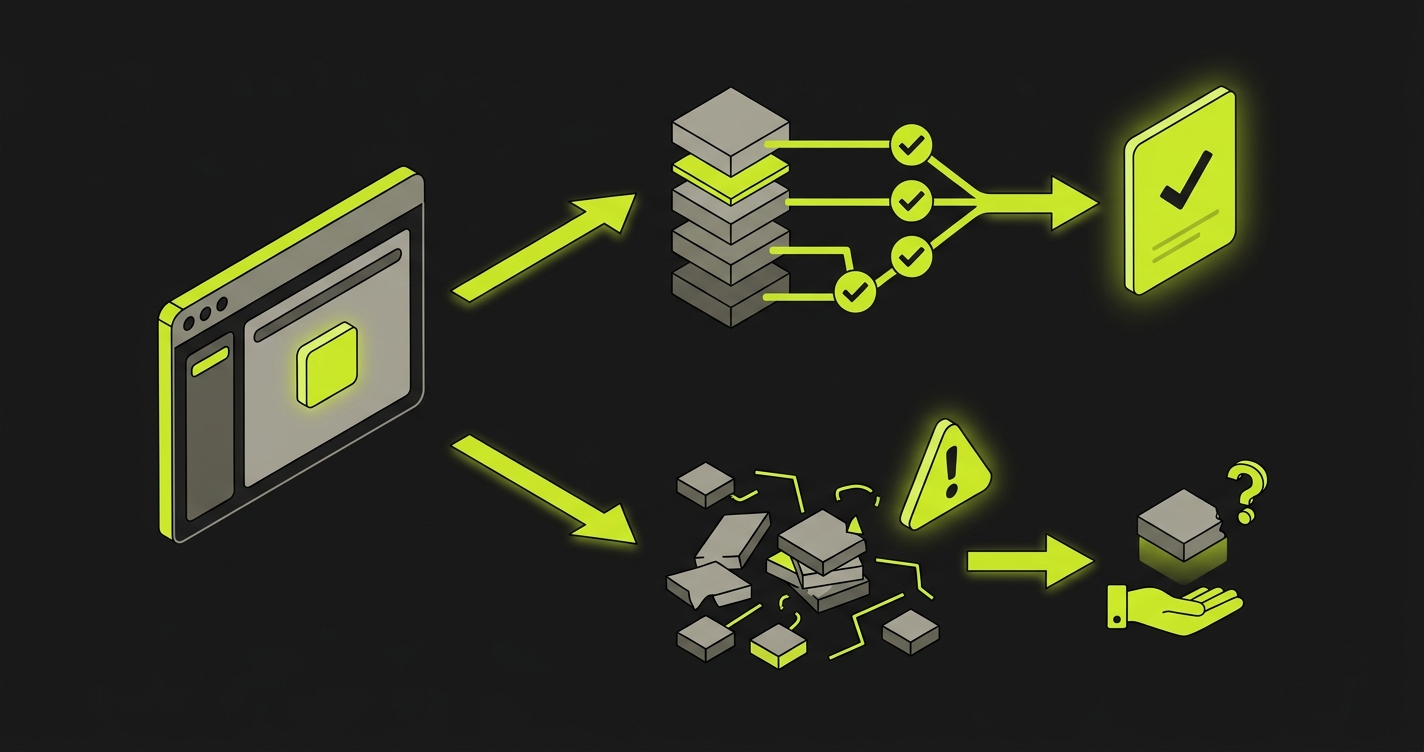
What engineers should require from any self-healing system
The minimum requirement is a visible change record. If a test healed, the PR should show the old target, the new target, the evidence used to match them, and the outcome that stayed valid. A sentence like "locator updated automatically" is not enough. It tells the engineer that something changed, but not whether the user flow remained true.
The second requirement is a confidence signal that reflects multiple checks. Label similarity alone is weak. DOM position alone is weak. Visual proximity alone is weak. Final outcome alone can be misleading if the wrong action still leads to a generic success page. The safer signal combines intent, page context, action semantics, and the expected user-visible result.
The third requirement is a flag path that feels normal, not exceptional. Engineers should expect some heals to become review tasks. That is not failure. It is the system refusing to invent certainty. If every heal is accepted automatically, the product is optimizing away the most valuable part of the feedback loop.
The fourth requirement is a way to update expectations when the spec changes. Heal-on-spec-drift is not solved by better selectors. It is solved by making the changed behavior explicit. If the product no longer requires an approval step, the test should be updated because the product changed, not because the tool found a way around the old assertion.
This is where self-healing tests and edge coverage meet. Many production regressions hide in corner cases where the happy path still looks fine. A self-heal that preserves only the happy path may miss the risky branch. The related article on edge case testing covers how to turn production signals into permanent coverage, but the same principle applies here: preserve the evidence that proves the business consequence.
How Autonoma self-heals for teams without QA review
Autonoma is built around Replay and Reviewer because self-healing is only useful if the repaired run can be inspected. Replay reruns the product flow and records what happened. Reviewer compares the observed path against the intended behavior and decides whether the run is healed, flagged, or a product failure worth attention.
Replay handles the mechanical part. It sees that a step no longer lands cleanly, searches for a viable continuation in the running app, and checks whether the flow can still reach the expected state. This is where Autonoma reduces the maintenance burden of self-healing e2e tests. The engineer should not have to repair every harmless class rename, moved component, or refactored wrapper by hand.
Reviewer handles the safety part. It asks whether the candidate continuation still proves the same thing. Did the signup complete, or did the run merely reach the dashboard through an existing session? Did the invite get created, or did the button only open a modal? Did checkout finish with the selected plan, or did the test drift into a different path that looks successful?
The healed-vs-flagged signal is deliberately conservative. If Replay finds a continuation and Reviewer sees strong evidence that the original intent still holds, the event can be marked healed. If Replay finds a continuation but Reviewer sees missing, conflicting, or weak evidence, the event is flagged. If the product behavior itself fails, the output is a bug signal, not a maintenance heal.
This reduces false positives, but it does not eliminate them. No self-healing system can perfectly infer product intent in every ambiguous state. Human review remains necessary for risky flows, changed business rules, auth state, payments, permissions, destructive actions, and any test where the expected outcome is a product decision rather than a mechanical UI fact.
The practical benefit is focus. Instead of asking a small team to review every selector change, Autonoma pushes routine drift into healed events and pushes ambiguous drift into flagged events. Engineers get a shorter review queue with better evidence. That is the difference between useful automation and a system that just moves uncertainty out of sight.
The output should also preserve the failure category. A selector-only repair is not the same as a product bug, and an environment failure is not the same as a spec change. When those categories collapse into one red or green status, engineers lose the diagnostic value of the run. Autonoma's Reviewer exists to keep those meanings separate so a founder-led engineering team can decide what actually needs work.
That separation matters during fast release cycles. A healed event can be reviewed later if it touched a low-risk UI path and preserved the expected outcome. A flagged event on billing, permissions, account creation, or data export should interrupt the release conversation because the system is saying the evidence changed. A confirmed product failure should go straight to the author while the implementation context is still fresh.
For broader context on agent behavior, the article on agentic QA explains how planning, execution, and review fit together without duplicating that loop here. The article on what an AI QA agent actually does is useful if you want the larger autonomy spectrum. The autonomous testing platform guide covers the broader platform layer around generated E2E coverage. This post stays focused on self-healing risk for no-QA teams.
A practical review policy for no-QA teams
Start by deciding which flows are allowed to self-heal automatically. Low-risk UI movement in a settings page can heal with a visible record. Signup, billing, invite, export, delete, permissions, and upgrade flows deserve a higher threshold, because a wrong click there can lock out a user, lose data, or charge the wrong plan. Then define what "healed" means: the same user intent, the same meaningful side effect, and enough evidence to explain the choice. If any of those are missing, the run should be flagged, not passed on the grounds that the browser did not crash.
The rest of the policy keeps that decision honest. Surface every heal in the PR, not a dashboard no one opens, so the author sees the healed path and the reason a run was flagged while the change is still fresh. Never let a heal become a silent merge bypass: update the expectation if the product changed on purpose, fix the bug if it changed by accident, review it if the system cannot tell. Keep an audit trail of accepted and rejected heals, and read it by flow rather than raw count, since ten harmless heals in a redesigned settings page are not the same risk as one ambiguous heal in checkout.
None of this is exotic, and that is the point. It is also exactly the behavior Autonoma is built to enforce. Replay recovers safe mechanical drift so engineers stop babysitting locators, Reviewer flags anything where the evidence no longer proves the original intent, and both land in the PR where the decision already happens. For a team without a QA reviewer, the real danger was never a red build. It is a green one that healed past a real bug. Self-healing should remove maintenance noise, not the feedback that tells you the product broke, and that is the line Autonoma is designed to hold for teams shipping without QA.
FAQ
Self-healing tests are automated tests that can recover when the UI changes, such as when a selector, label, or DOM structure moves. Safe self-healing checks whether the repaired path still matches the original user intent and expected outcome.
They are safe when heals are visible, evidence-backed, and flagged when intent is uncertain. They are risky when the system silently swaps selectors and keeps passing without showing engineers what changed.
Silent self-healing is when a test repairs itself without a useful review signal. The build may stay green, but the team may lose the evidence that a product flow, selector, or expected behavior drifted.
Yes. A self-heal can mask a real bug if it clicks the wrong replacement element, preserves an outdated expectation, or accepts a path without proving the same user outcome. That is why healed and flagged signals matter.
Autonoma separates healed from flagged outcomes. A healed outcome means the repaired path still has evidence for the original intent. A flagged outcome means Autonoma found drift, but the evidence is too weak or ambiguous to accept automatically.



