
Test data management (TDM) is the practice of creating, maintaining, and controlling the data used in software testing environments, spanning generation, anonymization, provisioning, and lifecycle cleanup. Teams that skip a deliberate TDM strategy spend 30-40% of their total testing time on data preparation alone: hunting for the right seed, waiting for a colleague to finish with the shared staging database, or debugging a test failure that turned out to be a data problem disguised as a code problem. A working TDM practice eliminates that overhead by making test data a managed asset rather than an accident.
At some point in the last 12 months, someone on your team copied a production database snapshot to staging "just for this one thing." It's still there. It contains real customer records. Three people have staging access who probably shouldn't. Nobody has thought about this since the day it happened because the tests pass and there's always something more urgent.
This is not a hypothetical. It's the single most common test data finding when engineering teams do a pre-SOC 2 audit. It shows up at companies with strong engineering culture, rigorous code review, and well-maintained CI pipelines. It shows up because test data management is invisible until it isn't.
This guide gives you the framework to change that, starting with where your team sits right now and the specific steps that move you forward without derailing everything else in the sprint.
The TDM Maturity Model: Where Are You Right Now?
The clearest way to diagnose a test data problem is to identify which stage of maturity your team is operating at. Most teams move through four stages, though not always sequentially, and many get stuck between stages for months or years.
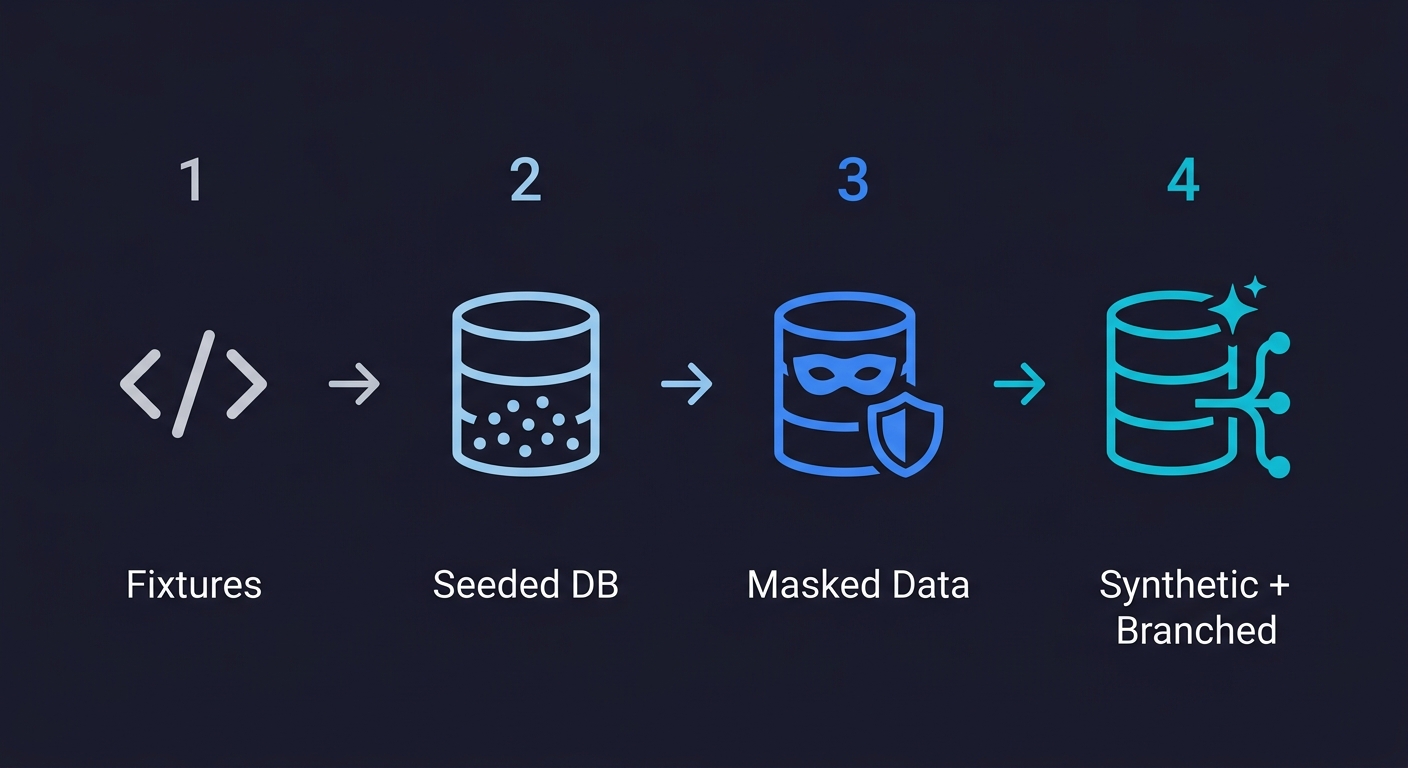
| Stage | Approach | Primary Problem | Team Size Where It Breaks |
|---|---|---|---|
| Stage 0: Hardcoded Fixtures | JSON/YAML files or inline constants in test code | Tests only cover one narrow state; brittle on schema change | Breaks at 2-3 engineers |
| Stage 1: Seeded Databases | SQL seed scripts or ORM factory libraries (Factory Boy, Faker) | Shared mutable state causes test pollution; slow to reset | Breaks at 5-8 engineers |
| Stage 2: Masked Production Data | Anonymized copies of production snapshots | Compliance risk if masking is incomplete; stale data drift | Breaks at compliance audit or GDPR/SOC 2 conversation |
| Stage 3: Automated Synthetic + Branched Data | AI-generated synthetic records, per-branch isolated databases | Upfront investment in pipeline; agents need schema awareness | Scales to 50+ engineers without friction |
Stage 0 is where every team starts. You hard-code a user object with a known ID, a product with a fixed price, an order in a known state. It works for the first few tests. It falls apart the moment your schema changes or you need to test any edge case that wasn't anticipated when the fixture was written. Stage 0 fixtures encode assumptions that become lies over time.
Stage 1 feels like real progress. You introduce seeding: factory functions, Faker libraries, SQL scripts that populate a test database before the suite runs. The tests are less brittle and cover more cases. The new problem is that the database is shared. Two engineers run tests simultaneously and step on each other's data. A test passes locally and fails in CI because someone left a record in a broken state. You're spending more time resetting the database than running tests.
Stage 2 is what most compliance-conscious teams land on: copy production data, mask the sensitive fields, restore it to staging. The data is realistic because it literally was real. The problems arrive when the masking is incomplete (a custom field with PII that the script didn't catch), when the snapshot goes stale (it was taken three months ago and your schema has drifted), or when someone discovers that even anonymized production data creates GDPR implications in certain jurisdictions. For a deeper look at what complete masking actually requires, see our guide on data anonymization for testing.
Stage 3 is the destination. Synthetic data generated on demand, isolated per branch or per test run, cleaned up automatically after. No shared mutable state. No PII risk. No schema drift. No "ask Dave if the staging DB is free." This is achievable today, but it requires investment in pipeline tooling that most teams delay until the pain becomes acute.
Types of Test Data and When to Use Each
Before choosing a generation approach, it helps to know what categories of test data exist. Each type serves a different purpose in your test suite, and most teams need a combination.
| Type | What It Is | When to Use It |
|---|---|---|
| Positive / Valid Data | Inputs that should pass all validations and produce expected results | Happy-path testing, smoke tests, basic regression |
| Negative / Invalid Data | Inputs that should be rejected (wrong types, missing required fields, out-of-range values) | Error handling, validation logic, input sanitization |
| Boundary / Edge-Case Data | Inputs at the exact limits of accepted ranges (min, max, zero, empty string, Unicode edge cases) | Boundary value analysis, off-by-one detection, encoding issues |
| Performance / Load Data | Large volumes of records designed to stress-test throughput and latency | Load testing, scalability validation, database query optimization |
| Security Test Data | Payloads that probe for vulnerabilities (SQL injection, XSS, CSRF tokens, malformed headers) | Penetration testing, OWASP validation, auth boundary testing |
| Production-Representative Data | Masked or subsetted copies of real production data that preserve statistical distributions | Realistic integration testing, ML model validation, data pipeline testing |
| Synthetic Data | Artificially generated data with no relationship to real users, designed to cover specific scenarios | Compliance-sensitive testing, edge-case coverage, regulated industries |
Most teams at Stage 0-1 only use positive and maybe negative data. Moving to Stage 2-3 means deliberately covering boundary, performance, and security data types as well. The maturity model progression maps directly to expanding which types of test data your team can generate on demand.
Autonoma complements your test data strategy by handling the E2E test execution — AI agents generate and run tests from your codebase, so your team can focus on managing the data that drives them.
The Real Cost of Ignoring Test Data Management
The 30-40% testing-time-on-data-prep figure is not abstract. For a team of 8 engineers spending 20% of their time on testing, this translates to roughly one engineer's full weekly capacity consumed by data setup and cleanup. That's before accounting for the bugs that slip through because the data conditions needed to reproduce them never existed in the test environment.
The downstream effects compound. Tests that require specific data states get marked as "manual only" and run once a quarter. Coverage gaps grow. Engineers stop trusting the suite because the failures are as likely to be data problems as code problems. Eventually the team stops treating CI failures as meaningful signals, which defeats the purpose of having tests at all.
There's also a compliance dimension that catches teams off-guard. GDPR, CCPA, SOC 2, HIPAA: all of these frameworks have explicit requirements about where personal data can live and how it must be handled. A production snapshot sitting in your staging environment, even a "temporary" one from last year's hotfix, is a potential violation. For teams pursuing SOC 2 certification or dealing with enterprise customers, this is not a hypothetical. See our GDPR compliance testing guide for what auditors actually look for.
What Effective Test Data Management Actually Delivers
Teams that invest in a deliberate TDM practice consistently report the same improvements: reduced test flakiness (because data isolation eliminates cross-test pollution), faster CI pipelines (because fresh containers replace slow database resets), compliance readiness out of the box (because PII never enters non-production environments), developer self-service for data (because any engineer can spin up a realistic test environment without asking for help), and shorter onboarding time for new engineers (because the data setup is automated, not tribal knowledge). These are not aspirational outcomes. They're the predictable result of moving from Stage 0 or 1 to Stage 2 or 3.
Test Data Generation Approaches: Which One Belongs in Your Stack
The four primary approaches to sourcing test data are not interchangeable. Each has a domain where it performs well and conditions where it fails.

| Approach | Realistic Data? | Compliance Safe? | Setup Cost | Maintenance Cost | Best For |
|---|---|---|---|---|---|
| Hardcoded Fixtures | No | Yes | Very Low | High (schema changes break everything) | Unit tests, stable schemas |
| Production Copy (Masked) | Yes (when fresh) | Risky (if masking is incomplete) | Medium | Medium (must re-mask on schema changes) | Realistic load testing, data-quality validation |
| Seeded / Factory-Generated | Partial | Yes | Low-Medium | Medium (factories drift from schema) | Integration tests, moderate team size |
| Synthetic (AI-Generated) | Yes | Yes | High (initial) | Low (schema-aware generators adapt) | E2E testing, regulated industries, large teams |
Production copies are compelling because the data is real. Real edge cases, real distributions, real character encodings that trip up your validation logic. The compliance risk is manageable if your masking pipeline is rigorous, but "rigorous masking" is harder than it sounds. Unstructured text fields, JSON blobs, and application-level metadata frequently contain PII that column-level masking tools miss. See the comparison of current data masking tools for what each approach actually covers.
Factory-generated data using libraries like Factory Boy (Python), Fishery (TypeScript), or Fabricator (Ruby) hits a useful middle ground. You control the schema, you can generate edge cases explicitly, and there's no PII risk. The limitation is realism: generated data doesn't naturally contain the messy edge cases you find in production, so it's possible to pass all your factory-seeded tests and still get surprised by real user behavior. For a detailed walkthrough of building a generation pipeline, see our test data generation guide.
Data subsetting is a fifth approach worth knowing about, particularly for teams with large production databases. Instead of copying the entire database or generating everything from scratch, subsetting extracts a representative slice of production data that preserves referential integrity across tables. A 500GB production database might yield a 5GB subset that contains complete, valid records across all tables. The challenge is maintaining foreign key relationships during extraction. Tools like Tonic.ai and Datprof handle subsetting with referential integrity preservation, and Jailer is a capable open-source option.
AI and LLM-Generated Test Data: The Newest Frontier
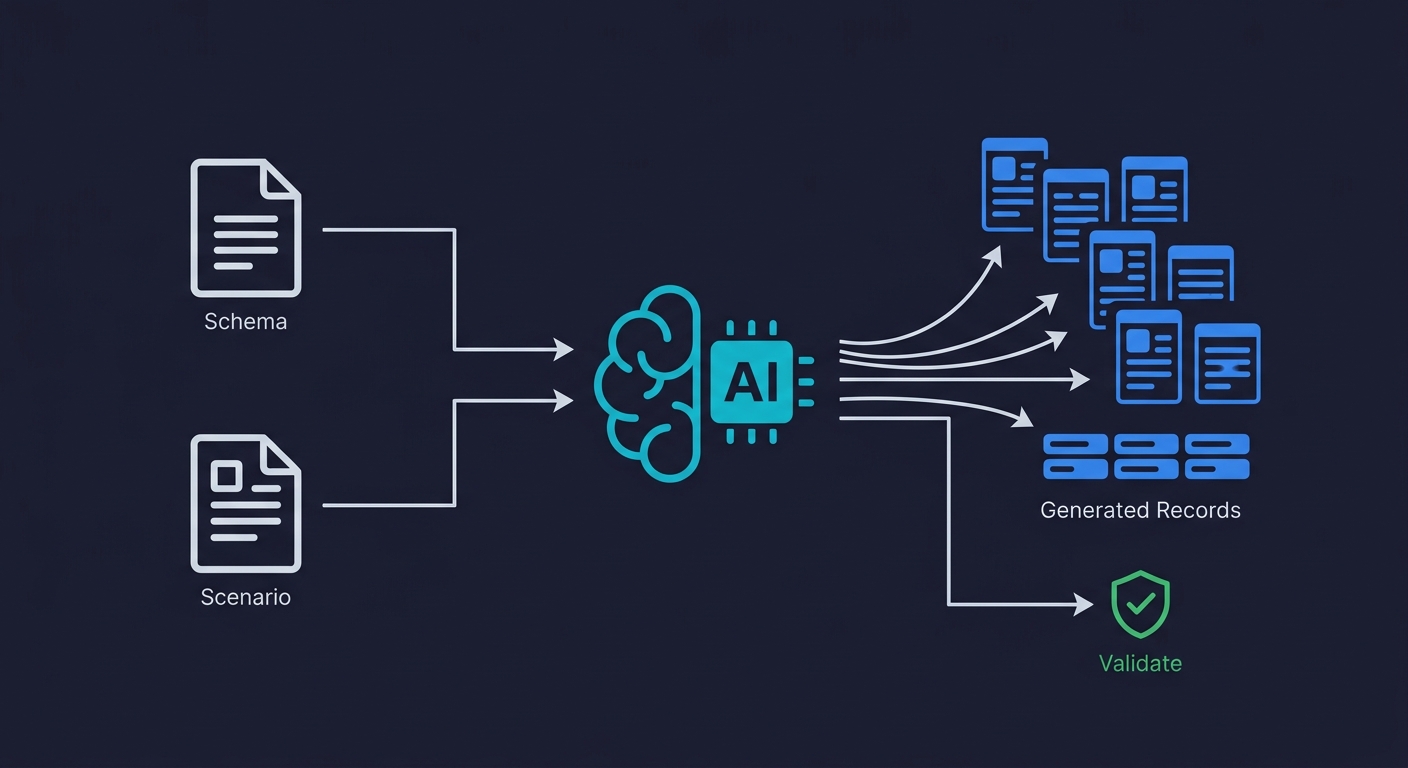
This is the area most guides haven't caught up on yet. In the past 18 months, LLM-based test data generation has moved from a curiosity to a legitimate part of the TDM stack for teams that know how to use it.
The core use case: give an LLM your schema definition and a description of the scenario you're testing, and it generates semantically coherent records that fit that scenario. Where a traditional Faker-based generator produces user.name = "John Smith" with a random address, an LLM-based generator can produce a complete, internally consistent user profile matched to the scenario, including realistic purchase history, realistic support ticket language, and realistic demographic distributions that reveal bias-related edge cases.
Three ways this is being used in practice right now. First, generating edge-case data for scenarios that are rare in production but important to test: expired payment methods, accounts with conflicting subscription states, users who have partially completed a multi-step flow. These are the exact cases that Faker-generated data misses and that production copies don't reliably contain. Second, generating locale-specific data that tests internationalization properly: names, addresses, and date formats that actually match the locale being tested, not just ASCII approximations. Third, generating "persona-based" datasets that represent specific user segments, which is particularly useful for feature testing where the data state should represent a particular user journey.
The current limitations are real. LLMs hallucinate constraint violations. A generated record might reference a foreign key that doesn't exist, use a date format that doesn't match your database column type, or generate a field value outside the valid enum range. LLM-generated data needs validation against the actual schema before insertion. This is a solvable pipeline problem, but it requires treating LLM output as a draft to be validated rather than a finished artifact.
The more significant limitation is that LLM-generated data lacks the true statistical properties of production data. If your application's behavior depends on data distributions (a recommendation engine, a fraud detection system, anything with a statistical model), LLM-generated data is not a substitute for production-representative data. Use it for correctness testing. Use masked production data for statistical testing.
The Open-Source TDM Landscape
Most articles on test data management jump directly to Informatica, Broadcom CA TDM, and IBM InfoSphere. Those are enterprise tools with enterprise price tags and enterprise implementation timelines. For a startup or growth-stage team, the open-source landscape is more immediately relevant.
Database branching tools are the most underutilized option in the open-source space. Neon (Postgres-as-a-service with branching), PlanetScale (MySQL with database branching), and Xata enable you to create an isolated database branch for each pull request in seconds. Tests run against a branch, the branch is deleted when the PR closes, and there's never contention on shared state. This solves the Stage 1 problem entirely. Database branching is a form of data virtualization, where isolated copies share the same physical storage through copy-on-write, making them fast to create and cheap to maintain. Enterprise tools like Delphix pioneered this approach for larger organizations. For a full explanation of how branching works and when to use it, see our guide on database branching.
Factory and seeding libraries are mature across every stack. Factory Boy (Python), Fishery or Faker.js (TypeScript/JavaScript), FactoryBot (Ruby), and GoFakeIt (Go) are all production-ready. The main limitation is that they require maintenance as your schema evolves, and they need to be explicitly updated when new required fields are added.
Data anonymization tools worth knowing: Faker (for replacing PII in place), Presidio (Microsoft's open-source PII detection and anonymization library), ARX (data anonymization for tabular data with formal privacy guarantees), and mkcert-style approaches for generating synthetic certificates and tokens. For teams dealing with regulated data, Presidio is the most practical starting point because it combines NLP-based PII detection with configurable anonymization operators.
Snapshot and restore tooling: pg_dump/pg_restore for Postgres, mysqldump for MySQL. Combine with schema migration awareness (via Flyway or Liquibase) and you can maintain a known-good snapshot that's automatically updated when migrations run. Not sophisticated, but reliable.
Test Data Management Tools at a Glance
| Tool | Category | Open Source? | Best For |
|---|---|---|---|
| Neon | Database Branching | Yes (Postgres) | Per-branch isolated databases, instant clones |
| PlanetScale | Database Branching | No (MySQL SaaS) | MySQL teams needing branch-based isolation |
| Factory Boy / FactoryBot | Factory Libraries | Yes | Python/Ruby integration test seeding |
| Faker.js / GoFakeIt | Data Generation | Yes | Realistic fake data across any stack |
| Presidio | PII Detection + Masking | Yes (Microsoft) | NLP-based anonymization for regulated data |
| ARX | Anonymization | Yes | Formal privacy guarantees (k-anonymity, l-diversity) |
| Tonic.ai | Synthetic + Subsetting | No (SaaS) | Realistic synthetic data with referential integrity |
| Delphix | Data Virtualization | No (Enterprise) | Large orgs needing virtual data copies at scale |
| Informatica TDM | Enterprise TDM Platform | No (Enterprise) | 50+ engineer teams with multi-jurisdiction data |
| Jailer | Data Subsetting | Yes | Extracting referentially intact subsets from large DBs |
Build vs. Buy vs. Open-Source: The Decision Framework
The right TDM approach depends on team size, budget, and compliance requirements. Here is how the decision branches in practice.
| Situation | Recommended Approach | Why |
|---|---|---|
| Pre-seed, 1-4 engineers, no compliance requirements | Open-source factories + seeding scripts | Zero cost, low overhead, sufficient for the scale |
| Seed-Series A, 5-15 engineers, SOC 2 on the roadmap | Database branching (Neon/PlanetScale) + Presidio for masking | Eliminates shared state, starts building compliance posture |
| Series A-B, 15-50 engineers, regulated data (HIPAA/GDPR) | Synthetic data pipeline (LLM-assisted + schema validation) + enterprise masking | Production data is too risky; synthetic covers correctness testing at scale |
| Scale-up, 50+ engineers, data in multiple jurisdictions | Enterprise TDM platform (Informatica, Broadcom CA TDM) or purpose-built internal tooling | Cross-team coordination, audit trails, and data catalog integration require platform-level features |
The most common mistake is buying enterprise tooling at Series A. A 12-person team does not need Informatica. The complexity and cost of an enterprise TDM platform will slow you down more than the data management problem it solves. Database branching and open-source factories handle the real problems at that stage.
The opposite mistake is staying on homegrown seeding scripts until Series B and beyond. Once you have 20+ engineers running tests simultaneously against shared infrastructure, the contention and flakiness will cost more in engineering time than a proper branching setup would have.
Test Data Management and Test Environment Management in Modern Stacks
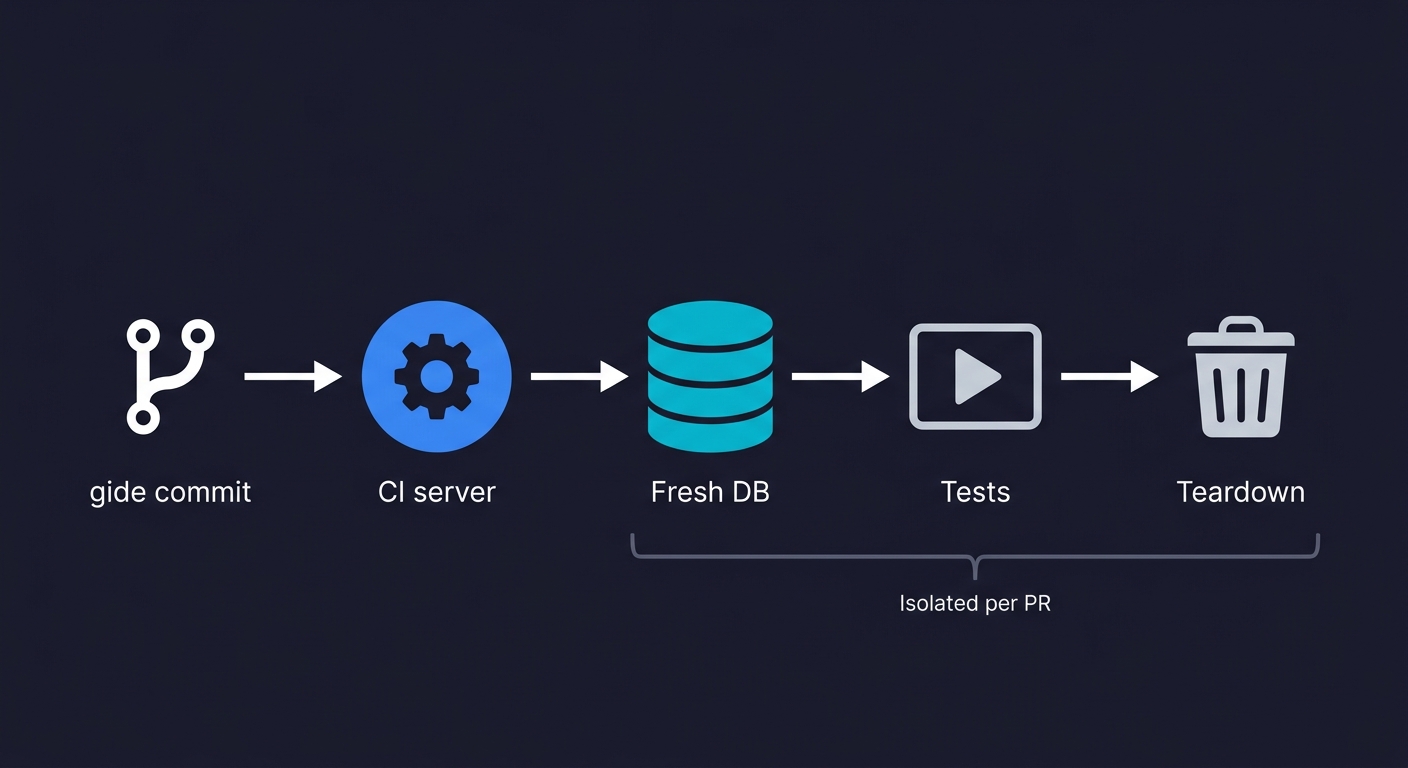
Abstract "best practices" for test data management and test environment management are unhelpful without addressing the actual infrastructure most teams are running. Here is how TDM integrates with Docker, GitHub Actions, and Kubernetes.
Docker Compose is the standard way to run isolated databases for local development and CI. A well-structured compose file spins up a clean database, runs your seed scripts, and tears it down after the test suite. The key discipline is making seeds idempotent: running the seed script twice should not produce duplicate data. Postgres's INSERT ... ON CONFLICT DO NOTHING and MySQL's INSERT IGNORE make this tractable.
# docker-compose.test.yml
services:
db:
image: postgres:16
environment:
POSTGRES_DB: test_db
POSTGRES_USER: test
POSTGRES_PASSWORD: test
volumes:
- ./seeds:/docker-entrypoint-initdb.d
ports:
- "5433:5432"
healthcheck:
test: ["CMD-SHELL", "pg_isready -U test"]
interval: 5s
timeout: 5s
retries: 5GitHub Actions can run a fresh seeded database on every pull request with this pattern. The key is using service containers: GitHub Actions spins up the database as a side-car to your test job, runs your seed script, runs your tests, and discards everything when the job finishes. No shared state across runs.
# .github/workflows/test.yml
jobs:
test:
runs-on: ubuntu-latest
services:
postgres:
image: postgres:16
env:
POSTGRES_PASSWORD: test
POSTGRES_DB: test_db
ports:
- 5432:5432
options: >-
--health-cmd pg_isready
--health-interval 10s
--health-timeout 5s
--health-retries 5
steps:
- uses: actions/checkout@v4
- name: Seed database
run: psql postgresql://postgres:test@localhost/test_db -f ./seeds/test_seed.sql
- name: Run tests
run: npm testKubernetes introduces additional complexity because test jobs may run across multiple nodes with no shared filesystem. The practical solution is to treat the database as an external service (not a pod) and use database branching tools (Neon, PlanetScale) where each test job gets its own branch. Kubernetes-native approaches using init containers to seed a shared database will cause test pollution when multiple jobs run concurrently. Don't do it. Use database branching or per-job database instances instead.
Test Data Management Challenges and Anti-Patterns
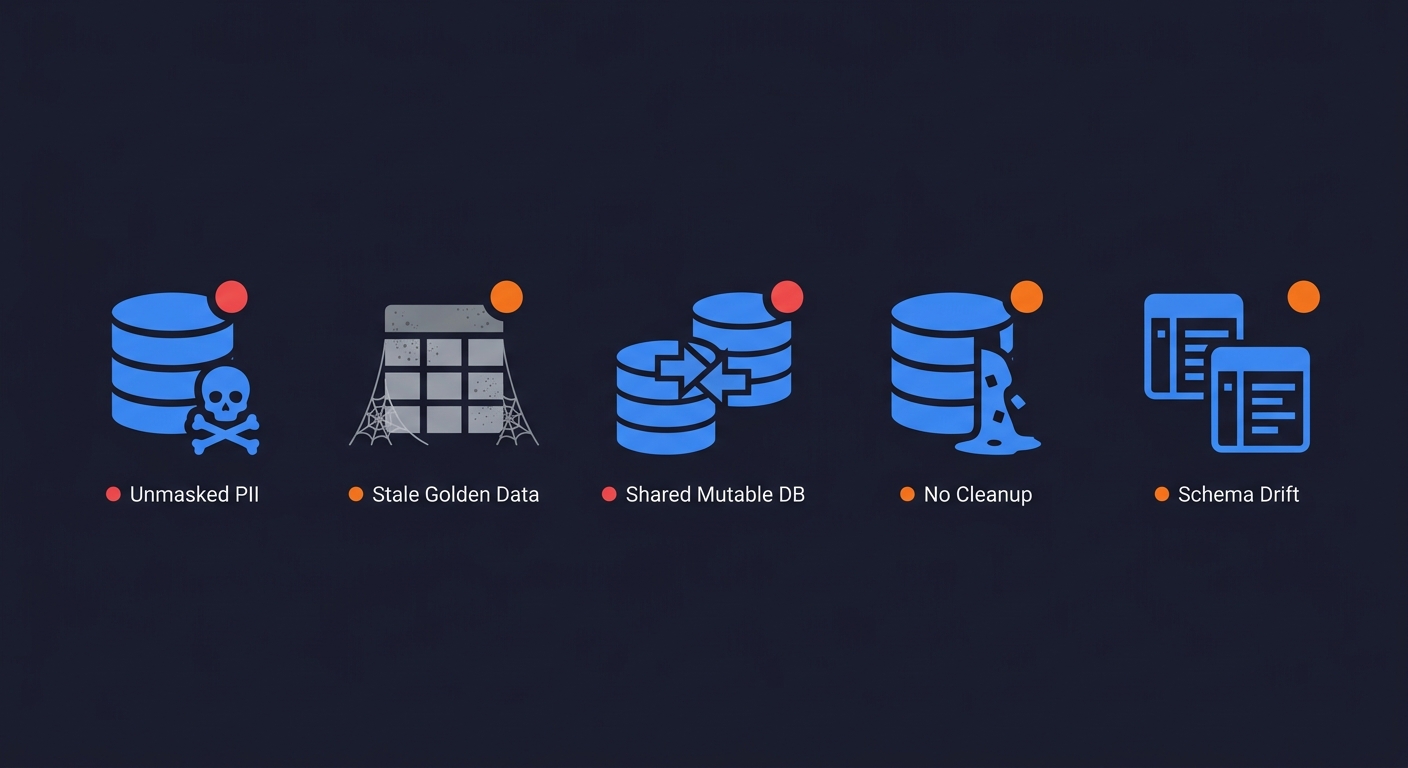
These are the patterns we see most often when engineering leads describe their data problems. Each one is fixable, but all of them are invisible until you've named them.
Copying production to staging without masking. This is the most common compliance time-bomb. Teams do it because it's quick and the data is realistic. The risk materializes when: an intern gets staging access (now they have production PII), a contractor is given staging credentials (potential data exfiltration), a staging environment gets breached (it happens; staging security is usually weaker), or a compliance audit reveals the practice. The fix is not a one-time cleanup. It's a masking pipeline that runs automatically whenever staging is refreshed.
The "golden dataset" that nobody maintains. A golden dataset is a fixed, shared database snapshot that was carefully curated for testing at some point in the past. It encoded all the important scenarios perfectly, the first week. Since then, the schema has changed, new features have added required tables, and the golden dataset has quietly become incorrect. Tests that depend on it still pass, but they're testing behavior that no longer reflects real application state. The tell: if nobody has touched the golden dataset in 3+ months and the application has shipped features, the dataset is wrong.
Shared mutable test databases. This is the Stage 1 trap at its worst. Multiple engineers or CI jobs write to and read from the same database concurrently. Tests fail for reasons that have nothing to do with the code being tested. The failures are intermittent, so engineers waste time investigating code changes that aren't actually broken. The fix is isolation: each test run needs its own data scope, whether through database branching, transaction rollback, or fresh containers.
No data lifecycle management. Test data accumulates. Synthetic records created for tests are never deleted. Staging databases grow to a size where refreshing them takes hours instead of minutes. Clone and restore operations that used to take 10 minutes now take 90. The symptom is "our staging environment is slow," but the root cause is a 200GB database that should be 2GB.
Schema drift between environments. Production has run 47 migrations since the last staging refresh. Staging has a different schema from production. Tests that pass in staging fail in production because a column was added, renamed, or removed, and the seed data doesn't account for it. The fix is automating staging refreshes as part of the migration process, not as a separate manual task.
How Autonomous Testing Handles Test Data
Test data management and test execution are usually treated as separate problems. We built Autonoma to treat them as one.
When our Planner agent reads your codebase, it doesn't just plan test cases. It understands the database state each test case requires. For a test that validates the checkout flow for a user with an expired payment method, the agent generates the API calls needed to put the database in that specific state before the test runs. You don't write seed scripts for that scenario. You don't maintain a golden dataset with an "expired payment" user in it. The agent derives what state is needed from the code itself and sets it up automatically.
The Maintainer agent handles the lifecycle problem. When your schema changes, the Planner re-reads your code and updates not just the test logic but the data setup. A new required field doesn't break your existing tests and leave you debugging a constraint violation at 11pm. The agent sees the migration, understands the implication, and updates the test data setup accordingly.
This matters specifically for the 30-40% data preparation overhead problem. Most of that overhead is not "creating the data." It's figuring out what data state is needed for a test, then manually constructing it, then cleaning it up, then repeating when the schema changes. Deriving data requirements from the codebase eliminates the figuring-out step. That's where the time actually goes.
Measuring TDM ROI: KPIs That Matter
If you're making the case for investing in test data management, these are the metrics that engineering leaders and VPs actually respond to. Track them before and after implementing TDM improvements to quantify the impact.
Data preparation time per test cycle. Measure how many hours per sprint engineers spend setting up, resetting, or debugging test data. This is the 30-40% figure, and it's the most viscerally understood metric. Even a 50% reduction here frees significant engineering capacity.
Test flakiness rate attributable to data. Tag flaky test failures by root cause. In most teams without TDM, 40-60% of intermittent failures trace back to data contention, stale state, or missing records rather than actual code bugs. Track this percentage monthly.
Environment provisioning time. How long does it take to spin up a fully seeded test environment from scratch? If the answer is "more than 15 minutes," you have a TDM bottleneck. Database branching can bring this under 30 seconds.
Compliance audit readiness. Can you prove, right now, that no production PII exists in any non-production environment? If the answer requires investigation, that's a TDM gap. Track time-to-answer for this question; mature TDM brings it to zero.
Mean time to onboard a new engineer's test environment. If a new hire can't run the full test suite locally on day one, test data and test environment management are part of the reason. This metric captures both the human cost and the automation maturity of your setup.
Test Data Management Best Practices: A Getting-Started Checklist
If you're starting from Stage 0 or Stage 1, here is the sequence that gives you the most improvement with the least upfront investment.
This week: Audit your current data approach. Where does test data come from? Who controls the staging database? When was it last refreshed? Is there any PII in staging? The audit takes two hours and tells you exactly which problems are acute.
This month: Introduce database isolation. If you're on Postgres, evaluate Neon for branching. If you're running Docker Compose locally, make sure your test containers start fresh on every run. If you have a shared staging DB that CI writes to, separate CI into its own isolated instance. Isolation alone eliminates 60-70% of test flakiness that's actually a data problem.
This quarter: Add a masking pipeline if you're using any production data anywhere in testing. Even a lightweight Presidio-based script that scrubs known PII fields is dramatically better than nothing. If you're pursuing SOC 2, this is no longer optional.
Before Series B: Evaluate whether your data generation approach can support the test coverage your team needs. If your factories are generating data that doesn't cover realistic edge cases, consider supplementing with LLM-generated scenarios for specific test categories. If your schema is evolving rapidly, automate the connection between migrations and test data updates.
Frequently Asked Questions
Test data management (TDM) is the practice of creating, maintaining, and controlling the data used in software testing environments. It covers the full lifecycle: generating test data in the right state for each scenario, keeping that data isolated between test runs, anonymizing or replacing any personally identifiable information, and cleaning up data after tests complete. Teams without a deliberate TDM strategy spend 30-40% of their testing time on data preparation alone, debugging failures that turn out to be data problems rather than code problems.
The best test data management tools for startups include Autonoma (which handles data state setup automatically as part of agentic test generation), Neon and PlanetScale for database branching (isolated per-branch databases with zero shared state), Factory Boy / FactoryBot / Faker.js for factory-generated seed data, and Microsoft Presidio for open-source PII detection and anonymization. Enterprise platforms like Informatica and Broadcom CA TDM are appropriate at scale but add unnecessary complexity for teams under 50 engineers.
Synthetic test data is artificially generated data that mimics the structure and statistical properties of real data without containing any actual personally identifiable information. Use it when: you're in a regulated industry (HIPAA, GDPR) and can't use production data; when you need to generate specific edge cases that don't reliably appear in production data; or when you need data at scale for load testing without incurring the compliance risk of production copies. Synthetic data is not a substitute for production-representative data when your tests depend on statistical distributions, such as recommendation or fraud detection systems.
For GDPR and HIPAA compliance in testing: never use production data in testing environments without a rigorous anonymization pipeline, and 'rigorous' means PII detection at the field, JSON blob, and free-text level, not just column-level masking. Use synthetic data for functional testing wherever possible. If you must use production-representative data, run it through a validated anonymization pipeline and document the process for your auditors. Store anonymized test data in a region-appropriate environment and enforce access controls that match your production data policies. For SOC 2, auditors will specifically ask about how PII is handled in non-production environments.
Test data generation creates new data from scratch (via factory libraries, Faker utilities, or LLM-based generators) with no relationship to real user data. Data masking takes real production data and replaces sensitive fields with realistic but fictional values while preserving the structure and statistical properties of the original. Generation is preferable for compliance and when you need specific edge cases. Masking is preferable when you need truly realistic data distributions or need to reproduce a specific production scenario. Most mature TDM strategies use both: generated data for standard test scenarios, masked production data for statistical or load testing.
Database branching creates an isolated copy of a database for each branch or test run, similar to how Git branches isolate code changes. Tools like Neon (Postgres) and PlanetScale (MySQL) implement this using copy-on-write storage so that creating a branch takes milliseconds rather than the minutes a full copy would require. Each CI job or developer environment gets its own branch, tests write to and read from that branch, and when the branch is deleted, all test data is cleaned up automatically. This eliminates the shared mutable state problem that causes intermittent test failures and test pollution.
To manage test data in CI/CD: use service containers (in GitHub Actions or GitLab CI) to spin up a fresh database for each test job, run idempotent seed scripts before the test suite starts, and let the container be discarded when the job finishes. For more sophisticated setups, use database branching tools so each pull request gets its own isolated database branch that is automatically deleted when the PR closes. The key principle is that test jobs should never share mutable database state. Contention on a shared test database is the most common cause of intermittent CI failures that turn out not to be code problems.
The cost of test data management ranges from zero (open-source factory libraries and seeding scripts) to six figures per year (enterprise platforms like Informatica or Delphix). For startups with fewer than 15 engineers, the most cost-effective approach is database branching via Neon or PlanetScale (free tiers available) combined with open-source factories like Factory Boy or Faker.js. The more relevant cost question is the cost of not having TDM: teams without it spend 30-40% of testing time on data preparation, which for an 8-person engineering team translates to roughly one full-time engineer's weekly output lost to data setup and debugging.
Test environment management covers the full infrastructure needed to run tests: servers, containers, networking, configurations, and deployed application versions. Test data management is a subset focused specifically on the data layer: generating, provisioning, isolating, and cleaning up the database records and state that tests depend on. In practice, the two are deeply connected. A perfectly provisioned test environment is useless if the data inside it is stale, shared, or contains PII that shouldn't be there. Modern approaches like database branching blur the line further by treating the data layer as part of the environment provisioning step.
Start by auditing your current state: identify where test data comes from, whether any production PII exists in non-production environments, and which test failures are actually caused by data problems rather than code bugs. Then locate your team on the TDM maturity model (Stage 0 through Stage 3) and identify the next stage. Prioritize database isolation first (it eliminates the most pain), then add masking if you use any production data, then evaluate synthetic generation for edge-case coverage. The strategy should specify who owns the test data pipeline, how often environments are refreshed, and what compliance constraints apply. Avoid the common mistake of jumping to enterprise tooling before you've solved the fundamentals of isolation and masking.



