
Test data management is the practice of creating, provisioning, masking, and maintaining the data your test suite needs to run reliably. A mature test data management strategy covers five stages: generation (creating realistic data that matches production schema), masking (removing PII so real data is safe to use in lower environments), seeding (loading the right data state before each test run), lifecycle management (versioning and refreshing datasets as the schema evolves), and cleanup (tearing down test artifacts after execution). Test data management automation handles these stages programmatically rather than relying on manual scripts that drift out of sync. Without it, test suites become flaky, compliance risks grow, and the cost of maintaining test data overtakes the cost of writing the tests themselves.
You already know something is wrong. The staging database nobody owns. The seed script that breaks every time a column changes. The developer who asks "did anyone else touch the test database?" in Slack because three tests just failed for no reason.
You have lived with it because fixing it properly requires time you do not have, and the current situation is uncomfortable but survivable. So you work around it. You rerun the flaky tests. You refresh staging manually when it gets bad enough. You add a comment in the seed script saying "update this when the schema changes" and quietly hope someone does.
The uncomfortable truth is that this strategy has a ceiling, and AI-assisted development brings you to that ceiling faster than you expect. When your team ships features four times faster, the test suite needs to cover four times as many scenarios, and every one of those scenarios needs reliable data underneath it. The workarounds that were merely inconvenient at ten tests per sprint become blockers at forty. This guide is the fix you have been putting off.
Why AI Development Creates a Test Data Explosion
Industry research consistently finds that 30 to 50 percent of test failures trace back to data issues, not code bugs. That number is about to get worse.
A developer using Cursor, Claude, or Copilot to write code ships features roughly four to ten times faster than before. That sounds like good news for throughput. It is, until you look at what it means for test coverage.
More features means more user flows. More user flows means more test scenarios. More test scenarios means exponentially more data permutations. A checkout flow that previously needed five data states (empty cart, single item, multiple items, out-of-stock item, coupon applied) now has fifteen when AI-generated features add gift cards, loyalty points, split payments, and saved addresses. Each of those permutations needs its own data. Each of those data states needs to exist in isolation so tests do not bleed into each other.
The math compounds fast. A team shipping five features per sprint at traditional pace needs a test data strategy. A team shipping twenty features per sprint with AI assistance needs one urgently.
What most teams have instead is a collection of decisions made in different years by different people:
A seed script written in 2022 that creates users but not the new subscription tiers added in 2023. A staging database that someone refreshed manually last quarter. A factory library that generates orders but not refunds. A .env.test file that points to a shared database that three developers are all running tests against simultaneously.
Each of these was a reasonable decision at the time. Together, they are duct tape on a pressure valve that keeps getting turned up.
The Test Data Management Lifecycle
Before fixing anything, it helps to name the stages clearly. Test data does not just exist or not exist. It moves through a lifecycle, and failure at any stage breaks the entire chain.
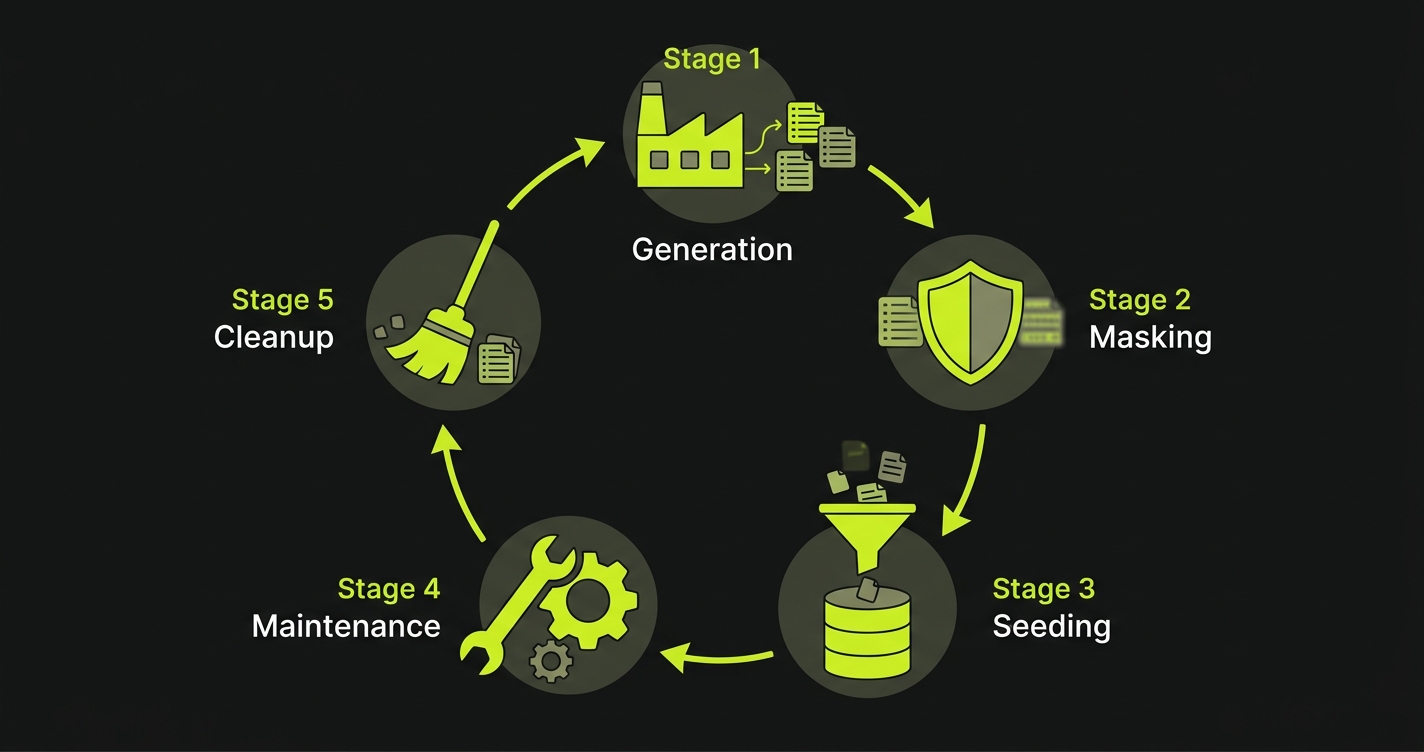
Generation is where test data begins. Either you create synthetic data from scratch using libraries like Faker, or you derive it from a snapshot of production data. Synthetic generation gives you full control and zero compliance risk. Production snapshots give you realism -- edge cases and data shapes you would never think to invent. Most mature teams use both.
Masking turns production data into safe test data. Raw production exports contain real emails, real names, real payment tokens, real health records. You cannot load those into a shared staging environment and call it compliant. Masking replaces sensitive fields with realistic but fake equivalents while preserving the structural relationships that make the data useful for testing. A masked user still has a plausible email, a plausible address, a plausible order history. It just cannot be traced back to a real person.
Seeding is the act of loading the right data into the right environment before a test runs. This is more than a one-time setup step. A good seeding strategy ensures each test starts from a known state, runs in isolation, and cannot be corrupted by tests running in parallel. For a deeper look at how AI handles this step specifically, the data seeding guide covers the full implementation pattern.
Maintenance is the quiet cost that teams underestimate. Schemas change. New columns appear. Old columns get renamed. A seed script that was accurate in January starts throwing foreign key constraint errors in March. Keeping test data in sync with a live schema is ongoing work, not a one-time task.
Cleanup closes the loop. Tests that create data should remove it. Environments that accumulate state from dozens of test runs become unreliable baselines. Cleanup is either explicit (teardown after each test) or environment-level (database snapshots that reset before each run).
Understanding these five stages lets you identify exactly where your current strategy is breaking. Most teams do not have a test data problem. They have a seeding problem, or a masking problem, or a maintenance problem. The solution looks different depending on where the pain actually is. For a broader overview of the maturity stages teams progress through, the test data management fundamentals guide covers the full progression from hardcoded fixtures to automated pipelines.
Synthetic Test Data Generation vs. Production Replicas
The first strategic decision in any test data plan is where your data comes from. There are two approaches, and the right answer almost always involves both.
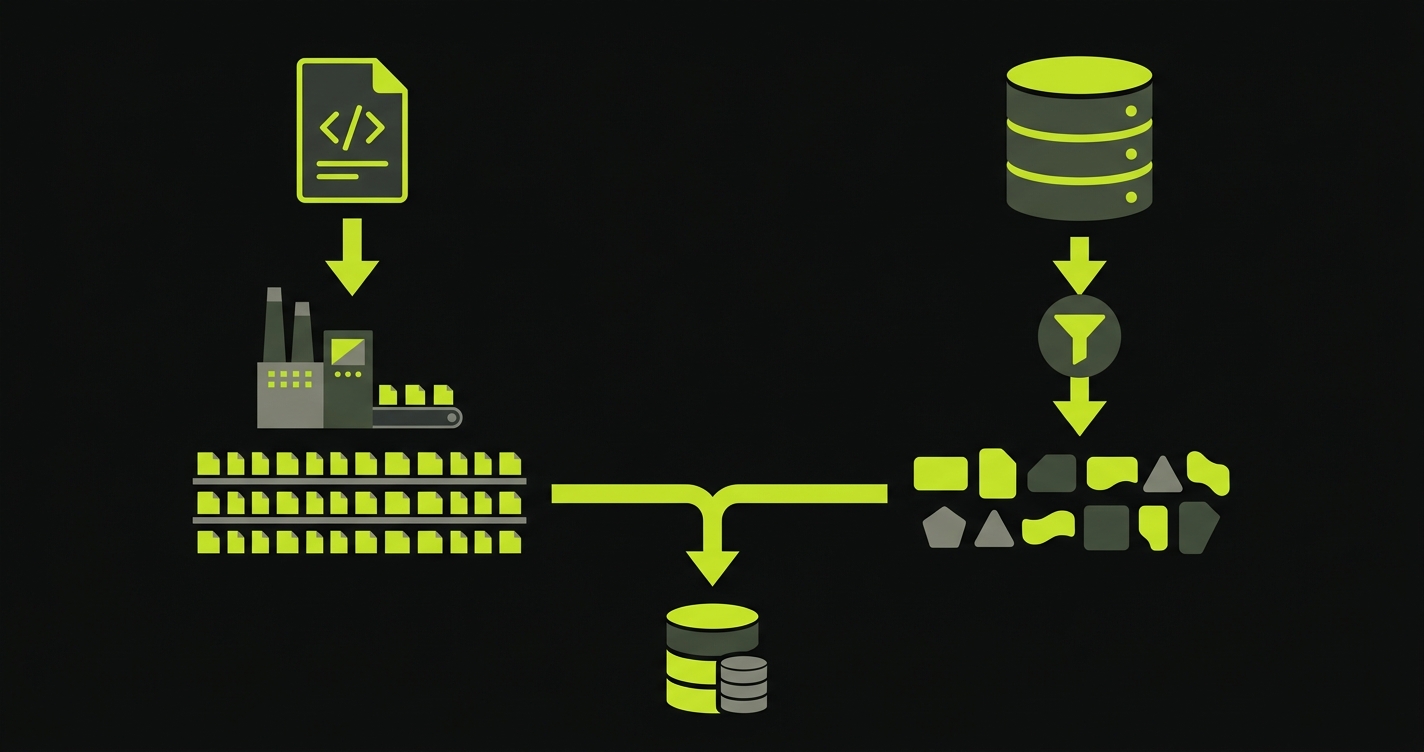
Synthetic data is generated entirely from code. Faker libraries, factory functions, and schema-aware generators create records that look real but reference no actual person or transaction. You control exactly what gets created. You can generate a thousand users in seconds, all with valid email formats, realistic names, and populated profile fields. You can create edge cases that have never happened in production -- a user with exactly zero loyalty points, an order with exactly one item at exactly the maximum quantity limit.
The downside is imagination. Your synthetic data is only as good as your model of what real data looks like. Production databases contain thirty years of edge cases: legacy users created before email was required, orders from countries you stopped supporting, records created during a data migration that left null fields in unexpected columns. A test suite running against perfect synthetic data will pass. The same code running against production-shaped data will surface bugs you never anticipated.
Production replicas -- masked copies of your actual database -- give you that realism. The schema, the relationships, the data distribution, the edge cases: all present. With proper masking applied, the data is safe to use in lower environments. The trade-off is pipeline complexity. You need a masking process, a refresh schedule, and a way to manage the resulting dataset across environments.
The practical synthesis: use synthetic data for the standard paths your tests define (the happy path, the expected error cases), and use masked production snapshots to periodically validate that your synthetic assumptions actually hold in the real world. The snapshot catches the bugs your factories could not imagine. For a focused comparison of the three main generation approaches, see the test data generation guide.
Test Data Masking and Compliance
Masking is not optional if your application handles personal data. GDPR requires that personal data be used only for its intended purpose -- using real customer emails to seed a staging environment does not qualify. HIPAA sets similar constraints for health information. Even outside regulated industries, a breach of a staging database that contains real user data carries real legal and reputational risk.
Effective masking preserves the usefulness of the data while removing the risk. A masked email address like user_4821@testdomain.com is still a valid email. A masked phone number still passes a phone number validation regex. A masked payment token is still the right length and format. The record still behaves like a real record. It just cannot identify a real person.
The masking techniques that matter most in practice:
Substitution replaces a real value with a fake value of the same type and format. Real name becomes generated name. Real email becomes generated email. The field is still populated, still passes format validation, still looks right in UI tests.
Shuffling redistributes real values across records. If a thousand users have real addresses, shuffle them so no address is attached to the original user. The addresses are still real-world addresses. They just do not belong to the person they were originally associated with.
Tokenization replaces sensitive values with opaque identifiers. Useful for fields like payment tokens or SSNs that need to maintain uniqueness and referential integrity without containing real information.
For teams with complex compliance requirements, the full implementation details live in the data anonymization guide, and GDPR compliance testing covers how to verify that your masking pipeline actually satisfies the regulatory requirement, not just the spirit of it.
Database Branching for Isolated Test Environments
Shared staging databases are the most common source of flaky tests. Two developers run tests simultaneously. One test creates a record. Another test counts all records and gets an unexpected number. A third test deletes a record that the first test was about to query. The tests are fine. The environment is the problem.
Database branching solves this by giving each test run its own isolated copy of the database. The copy is created from a known snapshot, tests run against it in isolation, and it is discarded afterward. No test can affect another. Every run starts from the same baseline.
Modern tools make this more practical than it used to be. Neon, PlanetScale, and similar platforms offer branch-level database isolation as a first-class feature. You create a branch from main, run your tests, delete the branch. The infrastructure handles the copy-on-write mechanics. The cost is low because branches share storage until they diverge.
The database branching guide covers the implementation patterns for the major platforms. The Docker Compose setup guide covers the container-level alternative for teams that prefer local isolation over cloud-based branching.
The right choice depends on your infrastructure. Cloud branching is lower friction for teams already using cloud-managed databases. Docker Compose is better for teams that need deterministic local environments or have complex multi-service dependencies.
AI-Powered Test Data Generation
This is where test data management automation stops being a nice-to-have and becomes essential infrastructure. When AI generates your code, it also needs to generate your test data. Not because that is convenient, but because AI-generated code creates test scenarios faster than any human can write fixtures for.
The traditional approach -- write a factory function, define the fields, export it for use in tests -- does not scale when tests are being generated at the same rate as features. You end up with a factory library that is always three sprints behind the actual schema.
AI-powered test data generation approaches this differently. Rather than maintaining static factories, the generator reads your schema and derives the data dynamically. It understands that a orders table has a foreign key to users. It knows that status has an enum constraint. It generates records that satisfy the schema, not just the fields the developer remembered to include in the factory.
For teams connecting their codebase to Autonoma, this happens as part of the test generation pipeline. When our Planner agent reads your routes and components to derive test scenarios, it also identifies the database state each scenario requires. It generates the API calls needed to put the database into the right state before each test runs -- not by reading fixture files, but by understanding what state the code actually needs. No manual fixtures. No brittle seed scripts that break when a column changes.
This matters most for the edge cases. A checkout test needs a user with items in a cart, a valid payment method, and no pending orders. A refund test needs a completed order, a user with a verified email, and a payment that has cleared. These states are easy to describe but tedious to maintain as factories. When test generation and data generation happen together from the same source of truth (the codebase), the data stays in sync automatically.
For teams implementing their own version of this pattern, the API testing automation guide covers how to use API calls for state setup, which is the more robust alternative to direct database manipulation.
Scaling Test Data Management: From 10 Tests to 10,000
The strategy that works at ten tests fails at a thousand. The strategy that works at a thousand fails at ten thousand. Understanding where each approach breaks is how you avoid rewriting your test data infrastructure from scratch every eighteen months.
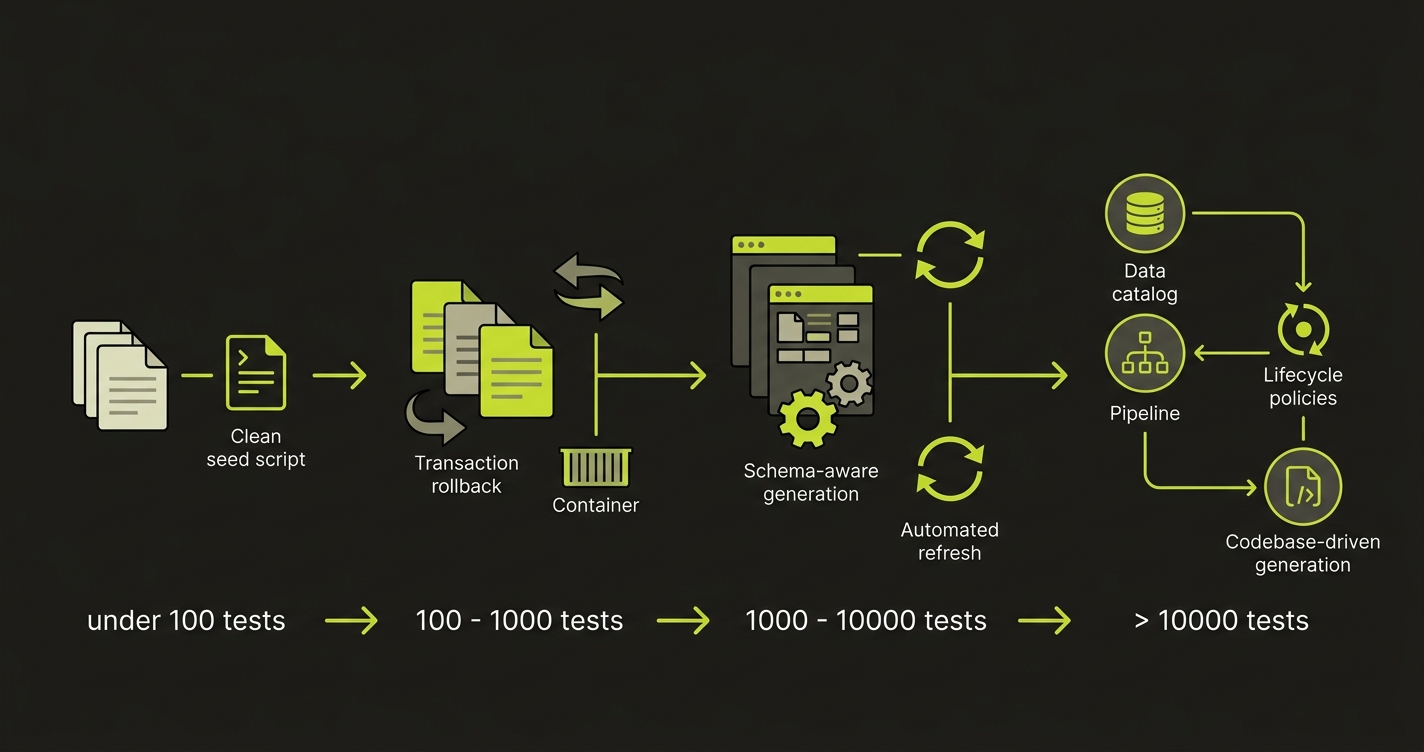
At low scale (under 100 tests), shared fixtures and a manually refreshed staging database are acceptable. The cost of coordination is low because the team is small and the test suite is simple. Invest minimally here. Get something working, not something perfect.
At medium scale (100-1,000 tests), shared state becomes a real problem. Tests start flaking because of environment interference. This is when you need per-test isolation. Database transactions that roll back after each test work well for unit and integration tests. Database branching or Dockerized environments work for E2E tests. Add a masking pipeline if you are using production snapshots. Formalize your factory pattern.
At high scale (1,000+ tests), the bottleneck shifts from isolation to data maintenance. Your schema is changing frequently. Your factory library is a sprawling codebase of its own. Refreshing masked production snapshots is a scheduled job that someone owns. Test data itself has a lifecycle -- datasets created for a feature that was deprecated two years ago are still cluttering your environment.
| Scale | Primary Problem | Right Tool | What to Skip |
|---|---|---|---|
| Under 100 tests | Getting data to exist at all | Faker factories, manual seed scripts | Database branching infrastructure |
| 100-1,000 tests | Test interference / flaky state | Transaction rollbacks, DB branching, Docker | Complex masking pipelines |
| 1,000-10,000 tests | Schema drift / maintenance cost | Schema-aware generation, automated refresh | Hardcoded fixture files |
| 10,000+ tests | Data lifecycle / cleanup debt | Data catalog, lifecycle policies, codebase-driven generation | Any manual intervention in the pipeline |
At ten thousand tests, no one is writing fixtures by hand anymore. The generation is automated, the masking pipeline runs on a schedule, branching is handled by infrastructure, and cleanup is enforced by policy. The teams that reach this scale cleanly are the ones who made these investments incrementally rather than all at once.
The teams that struggle are the ones who skipped medium scale -- who went from "this works fine for now" directly to "nothing works and we do not know why."
Test Data Management Tools
The tools you need depend on which stage of the lifecycle is breaking. Most teams do not need a single platform. They need the right tool at each stage.
Synthetic generation is the most mature category. Faker (JavaScript and Python) handles basic field generation. Mockaroo adds a web UI and schema import. Tonic.ai generates realistic datasets from production schemas with built-in masking. GenRocket offers enterprise-grade synthetic data design for complex relational models.
Data masking and virtualization tools focus on making production data safe. Delphix combines masking with data virtualization, letting teams provision masked copies without duplicating storage. Informatica offers masking as part of a broader data governance suite. K2view provides entity-based masking that preserves cross-table relationships.
Environment provisioning tools handle the isolation layer. Neon and PlanetScale offer database branching natively. Docker Compose handles multi-service isolation for teams running local environments. Testcontainers programmatically spins up containerized databases per test run.
AI-powered generation is the newest category and the one changing fastest. Rather than maintaining a separate data pipeline, tools like Autonoma generate test data as part of the test creation process itself. Our approach reads your codebase to understand both the scenarios to test and the data states those scenarios require, eliminating the gap between test logic and test data.
The key insight: standalone tools solve one stage well. Integrated approaches solve the coordination between stages. As your test suite grows, the coordination cost becomes the dominant problem.
Test Data Management Best Practices
These practices are distilled from teams that have scaled their test suites past the flaky-tests threshold and into reliable, high-velocity CI pipelines.
Generate from schema, not from memory. Static factories encode what a developer remembered to include. Schema-driven generation encodes what the database actually requires. When a migration adds a non-nullable column, schema-aware generators adapt automatically. Manually maintained factories throw errors until someone remembers to update them.
Isolate every test run by default. Shared state is the primary cause of flaky tests. Use transaction rollbacks for unit and integration tests. Use database branches or containerized environments for E2E tests. The cost of isolation is always lower than the cost of debugging shared-state failures.
Mask before you export, not after. Production data should never exist unmasked outside production, even temporarily. Build masking into the export pipeline so that no intermediate step creates an unmasked copy. This is not just a compliance best practice. It is the only way to prevent accidental exposure in staging environments.
Version test data definitions alongside code. When a migration changes the schema, the test data definitions should change in the same pull request. If your factories live in a separate repo or are updated on a different cadence, schema drift is inevitable.
Automate cleanup by policy. Tests that create data must destroy it. Environments should have TTL policies that prevent stale data from accumulating. A staging database that has been running for six months without a reset is not a staging database. It is a museum of every test artifact from the last two quarters.
Measure data health, not just test results. Track the percentage of flaky tests attributable to data issues. Track provisioning time per test run. Track the gap between your factory definitions and your current schema. These metrics tell you whether your test data infrastructure is healthy before your CI pipeline starts turning red.
The Test Data Debt Audit
Before you overhaul anything, spend two hours doing an audit. The goal is to understand exactly where your current strategy is breaking before committing to a solution.
Start with your most flaky tests. Flakiness is almost always a state management problem. Either the test depends on data that another test modified, or the data state it expects does not exist reliably. Group your flaky tests and look for patterns in the data they touch.
Then look at your seed scripts and factory libraries. When were they last updated? Do they cover the full schema, or just the fields that existed when someone wrote them? Are there foreign key relationships that the factories do not handle correctly? Schema drift between your factories and your actual database is one of the most common silent test data failures.
Finally, look at your environments. How many environments share a database? How often is staging refreshed? Does anyone own the health of the test database, or is it everyone's problem and therefore no one's problem?
The answers to these questions tell you where to start. Teams with lots of flaky tests need isolation first. Teams with factories that are always behind the schema need generation automation. Teams with compliance risk in their staging data need masking before anything else.
Test data management is not a one-time project. It is ongoing infrastructure, the same as your CI pipeline or your deployment process. The teams that treat it as infrastructure rather than an afterthought are the ones whose test suites stay reliable as the codebase scales.
Test data management is the practice of creating, provisioning, masking, and maintaining the data your test suite needs to run reliably. It matters because tests that depend on unstable, shared, or poorly structured data produce flaky results, create compliance risk, and become expensive to maintain. As development accelerates, test data management becomes a core piece of engineering infrastructure rather than an afterthought.
Synthetic test data is generated entirely from code using libraries like Faker. It carries no compliance risk and gives you full control over edge cases. Production replicas are masked copies of your actual database, giving you realistic data shapes and edge cases that synthetic generation cannot anticipate. Most mature teams use both: synthetic for standard test scenarios, masked production data for periodic validation against real-world data patterns.
The two main approaches are transaction rollbacks (roll back every database change after each test, effective for unit and integration tests) and database branching (give each test run its own isolated database copy, better for E2E tests). Docker Compose environments with per-run containers work well for teams that need local isolation or have multi-service dependencies.
GDPR compliance means no personal data from real users should exist in lower environments (staging, QA, development) without explicit authorization. In practice, this means running a masking pipeline on any production snapshots before they are used in testing. Masked data should preserve the structure and format of real data (valid email formats, plausible names) without containing information that can be traced back to a real person. Substitution, shuffling, and tokenization are the core masking techniques.
AI code generation accelerates feature delivery, which multiplies the number of test scenarios and data permutations a test suite needs to cover. This makes manual fixture maintenance impractical at scale. AI-powered test generation tools like Autonoma address this by reading the codebase to understand both the test scenarios needed and the database state each scenario requires, generating the data setup as part of the test generation pipeline rather than requiring manually maintained fixtures.
Synthetic test data generation is the automated creation of realistic test data from a schema definition, without using any real user information. Tools like Faker (JavaScript and Python) generate values for each field type: realistic names, valid email formats, plausible addresses, correctly formatted dates. Schema-aware generators go further by understanding foreign key relationships and constraints, ensuring generated records satisfy the full database schema rather than just individual fields.
Test data management automation is the practice of programmatically handling data generation, masking, provisioning, and cleanup rather than relying on manual scripts and ad-hoc processes. Automated pipelines generate data from schema definitions, apply masking rules to production snapshots on a schedule, provision isolated datasets per test run, and tear down test artifacts after execution. Automation becomes essential when AI-accelerated development multiplies the number of test scenarios faster than manual data preparation can keep up.
The core best practices are: generate from schema rather than maintaining static fixtures, isolate every test run to prevent shared-state interference, mask production data before it leaves the production environment, version data definitions alongside application code so they stay in sync with schema changes, enforce cleanup policies to prevent stale data accumulation, and measure data health metrics (flaky test attribution, provisioning time, schema drift gap) alongside test results.
The leading tools by category are: Faker and Mockaroo for synthetic data generation, Tonic.ai and GenRocket for schema-aware generation at scale, Delphix and Informatica for data masking and virtualization, Neon and PlanetScale for database branching, and Testcontainers for containerized test environments. For AI-powered test data generation integrated with test creation, Autonoma reads your codebase to generate both the tests and the data states they require.