
Data anonymization is the process of transforming personally identifiable information (PII) so it can no longer be traced back to a real individual, making it safe to use in non-production environments like development, staging, and testing. There are four main techniques: data masking (replace values with realistic fakes), pseudonymization (replace with a reversible token), generalization (reduce precision, like replacing a birthday with a birth year), and synthetic data generation (create entirely fabricated but structurally realistic records). For most startups, the practical goal is simple: your engineers should be able to run tests against realistic data without ever touching real customer records.
It starts with a reasonable shortcut: an engineer needs realistic data to reproduce a bug, so they pull a snapshot from production. The test passes. The snapshot stays. Six months later, your staging environment has live customer PII and nobody is quite sure how much of it or how long it's been there.
This is the most common data anonymization problem at startups, and it almost never gets fixed proactively. It gets fixed when a GDPR audit question lands in the CEO's inbox, or when an enterprise prospect's security review asks what data sits in your non-production environments.
If you're reading this before that moment, you have a real advantage. GDPR test data compliance is not an overnight project, but the high-risk exposure is usually concentrated in three or four places, and those are fixable in a sprint.
What Data Needs Anonymization for Testing?
Before picking tools or techniques, it helps to be specific about what data you're protecting and where it lives. Most startups have more exposure than they realize, spread across more places than they've audited.
The obvious PII is names, email addresses, phone numbers, physical addresses, and date of birth. These are the fields that get mentioned in every compliance checklist, and they're the easy ones to reason about. Your users table probably has most of them in one place.
The less obvious PII is trickier. IP addresses are PII under GDPR. Device fingerprints can be PII. Behavioral data combined with a user ID is effectively PII even if the individual fields look innocent. Payment card numbers (even partial), social security numbers, tax IDs, government-issued ID numbers, and health data all carry elevated risk under both GDPR and SOC 2. If you're in fintech or healthtech, this category matters more than the obvious one.
Then there are the indirect identifiers: the fields that don't identify someone on their own but can be combined to do so. A job title, an employer name, a zip code, and an approximate age can together identify a specific person. This is the data that causes auditors to ask follow-up questions.
The environments that need anonymized data are your development and local databases (if engineers are using production snapshots to reproduce bugs), your staging and QA environments, any CI/CD test databases, and any analytics environments that aren't your production analytics system. If you're using ephemeral environments for preview deployments or PR-based testing, those need anonymized data too.
Start your audit there. Before you think about tooling, look at your staging and CI databases and ask: where did this data come from? If the answer is "a prod dump," you already have a live compliance issue. The tool conversation comes after you've acknowledged the scope of what needs to change.
See our test data management guide for a broader framework on how anonymization fits into your overall test data strategy.
Data Anonymization Techniques: When to Use Each One
Test data anonymization techniques aren't interchangeable. Each trades something different, and picking the wrong one for a use case creates either a compliance gap or an unnecessary operational burden.
Data Masking: Replacing PII with Realistic Fakes
Masking replaces real values with realistic fake ones. An email address becomes a different valid-looking email address. A name becomes a plausible name. A credit card number becomes a number that passes Luhn validation but isn't real. The key property: the masked value has the same format and type as the original, so your application code doesn't break.
Masking is the right choice when your tests need structurally realistic data, when you want engineers to work in an environment that feels like production, and when you don't need to trace test results back to specific records. It's the most widely used technique for test environments because it's low-friction: you run a masking script against a prod snapshot and get a staging database that looks real without being real.
The limitation is that masking is typically irreversible. Once you replace the original value, you can't recover it. That's usually fine for testing. It's a problem if you need to correlate test results back to production records, which is an uncommon requirement but worth naming.
Pseudonymization: Token-Based Reversible Replacement
Pseudonymization replaces real values with tokens using a consistent mapping. The same email address always maps to the same token, and that token can (in theory, with the right key) be reversed back to the original. Pseudonymization is technically weaker than masking from a privacy standpoint (the data is still re-identifiable if someone has the mapping key), but it's a recognized technique under GDPR Article 4(5) and reduces your compliance exposure compared to using raw production data.
The main use case for pseudonymization in testing is when you need consistency. If your tests depend on the same user always having the same identifier (for FK relationships, for lookup logic, for referential integrity), pseudonymization preserves that consistency where random masking would break it.
It's more complex to implement than simple masking because you need to maintain and protect the mapping table. If the mapping table leaks, you've re-identified your data. Most startups don't need pseudonymization for test environments and should use masking instead. The exception is when you're working with complex relational data where consistency across foreign keys is non-negotiable.
Generalization: Reducing Data Precision
Generalization reduces the precision of data rather than replacing it. A full date of birth becomes a birth year. A specific dollar amount becomes a range. A precise address becomes just a city or zip code. The data is still true, just less specific, making it harder to identify individuals.
Generalization is most useful for analytics and reporting environments, not for functional test environments. If you're testing a feature that shows a user their account balance, you need a specific number, not a range. But if you're building a dashboard that shows aggregate customer demographics, generalized data serves perfectly well and requires no transformation of the functional data at all.
It's also a useful fallback when masking would break application logic. Some fields are hard to fake realistically: certain industry codes, regulatory identifiers, or locale-specific formats. Generalization lets you reduce PII risk without having to build a correct fake-value generator for every edge case.
Synthetic Data Generation: Building Test Data from Scratch
Synthetic data is entirely fabricated from scratch: no real records, no transformations, no real values anywhere in the pipeline. You define the schema and statistical distributions, and a generator produces realistic-looking data that matches your production data's shape without originating from it at all.
This is the gold standard from a compliance perspective. There's no production data in your test environment, period. No masking pipeline to audit, no snapshot to worry about, no partial-transformation edge cases. GDPR's definition of personal data requires that a real person exist behind the data; synthetic records don't have a real person behind them by definition.
The practical limitation is fidelity. Production databases accumulate edge cases, unusual states, and combinations of values that no generator will produce unless you explicitly model them. A bug that only reproduces when a user has a billing address in a specific country with a specific payment method set up in a specific sequence is unlikely to show up in synthetic data unless someone has already seen it in production and explicitly built a test case for it.
For startups, synthetic data works well for green-field test environments where you're building test suites from scratch. It's harder to use as a drop-in replacement for a production snapshot because you'll find gaps: things your application does that your synthetic data doesn't cover.
The pragmatic approach is to combine techniques: use synthetic data as your baseline, pseudonymized or masked production data for known edge-case scenarios, and masking for any production snapshots you do need to pull.
Data Swapping: Shuffling Values Across Records
Data swapping (sometimes called permutation or shuffling) rearranges real values between records rather than replacing them. The actual values in a column stay the same, but they get reassigned to different rows. A user named Alice gets Bob's email, Bob gets Carol's phone number, and so on. The column-level statistics (distribution, uniqueness, format) remain identical to production because the values are real. The row-level combinations become meaningless.
Swapping is useful when you need to preserve statistical distributions for analytics testing but don't want any individual record to match a real person. It pairs well with masking: swap the fields where distribution matters, mask the fields where it doesn't. The limitation is that swapping alone doesn't protect unique values. If only one record has a specific value (say, a rare country code), swapping doesn't help because the value still maps to exactly one person.
Perturbation: Adding Controlled Noise
Perturbation adds small, random modifications to numeric or date values. A salary of $85,000 becomes $83,200 or $87,400. A timestamp shifts by a random number of hours. The data stays close enough to the original to be useful for aggregate analysis, but no individual value matches the real record precisely.
This technique is most relevant for analytics and ML test environments where you need realistic distributions but exact values don't matter. For functional test environments (testing UI rendering, API responses, form validation), perturbation is usually overkill. Masking or synthetic data serves better when your tests check specific behaviors rather than aggregate patterns.
Tokenization: Vault-Based Replacement
Tokenization replaces a sensitive value with a non-sensitive placeholder (the token) while storing the original in a secure, separate vault. It's similar to pseudonymization, but the token has no mathematical relationship to the original value, making it stronger from a security standpoint. The mapping is stored in a dedicated token vault rather than a reversible algorithm.
Tokenization is the standard approach for payment card data (PCI DSS compliance) and is increasingly used for other high-sensitivity fields. For most startup test data scenarios, masking is simpler and sufficient. Tokenization becomes relevant when you need to process the real value in a specific, controlled context (like running a payment) while keeping all other environments token-only.
Comparing Data Anonymization Techniques
| Technique | Reversible? | Data Fidelity | Compliance Strength | Complexity | Best For |
|---|---|---|---|---|---|
| Data Masking | No | High (format preserved) | Strong | Low | Test environments, staging databases |
| Pseudonymization | Yes (with key) | High (consistent mapping) | Moderate (GDPR recognized) | Medium | Relational data with FK constraints |
| Generalization | No | Reduced precision | Moderate | Low | Analytics, reporting environments |
| Synthetic Data | N/A (no real data) | Variable | Strongest | High | Green-field test suites, ML training |
| Data Swapping | No | Statistical distributions preserved | Moderate | Low | Analytics testing, aggregate reports |
| Perturbation | No | Approximate | Moderate | Low | Numeric/date fields in analytics |
| Tokenization | Yes (via vault) | None (opaque token) | Strong (PCI DSS) | High | Payment data, high-sensitivity fields |
Open-Source Data Anonymization Tools for Startups
Most guides in this space jump straight to Informatica or Delphix. Those tools solve real problems at enterprise scale, but they start at tens of thousands of dollars per year and assume a dedicated data team. Here's what's actually available for a startup that needs to solve this with one engineer and a limited budget.
| Tool | Technique | Best For | Limitation | Cost |
|---|---|---|---|---|
| Faker (any language) | Synthetic / masking | Generating test fixtures and replacing specific fields in scripts | Requires you to write the transformation logic yourself | Free |
| Anonymize (Ruby gem) | Masking | Rails apps: mask specific columns in-place on a DB copy | Rails/ActiveRecord only | Free |
| postgresql-anonymizer | Masking + pseudonymization | Postgres: declare masking rules as column comments, run as extension | Postgres only, requires superuser access | Free (Apache 2) |
| Faker.js / @faker-js/faker | Synthetic / masking | Node.js pipelines, seeding test databases with JS scripts | Still requires wrapping in a migration/seeding script | Free |
| Presidio (Microsoft) | Detection + masking | Finding PII in text fields you didn't know were storing PII | NLP-based, slower, better for scanning than bulk transformation | Free (MIT) |
| Gretel.ai | Synthetic data (ML-based) | High-fidelity synthetic data that preserves statistical distributions | Free tier limited; paid plans for production use at scale | Free tier + paid |
| Neosync | Masking + synthetic + sync | Startups wanting an end-to-end anonymization pipeline with a UI | Newer project, smaller community | Open-source + hosted |
| Greenmask | Masking + pseudonymization | Postgres: deterministic transformers, CI/CD integration, S3 storage | Postgres only, newer than postgresql-anonymizer | Free (Apache 2) |
For a Postgres shop, postgresql-anonymizer is the highest-leverage starting point. You define masking rules directly as column comments or in a configuration file, and the extension handles the transformation when you create a masked dump. The rules live in version control alongside your schema, which makes them auditable, a direct SOC 2 requirement.
For Node.js applications without a Postgres dependency, a masking script built on @faker-js/faker gets you most of the way there in a day of work. The script pulls a production snapshot, replaces PII fields with Faker-generated values using the same schema, and writes the output to a new file. It's not elegant, but it's auditable, it's yours, and it costs nothing.
Neosync is worth evaluating if you want something more polished. It offers a pipeline model where you configure what to mask, what to synthesize, and where to sync the result. The open-source version runs self-hosted; there's also a cloud offering. For a startup that wants to move fast and doesn't want to maintain a custom masking script indefinitely, it's a reasonable middle ground.
Here's what a basic postgresql-anonymizer setup looks like in practice. You declare masking rules as SQL comments on your columns, and the extension applies them when you create a masked dump:
-- Define masking rules directly on columns
SECURITY LABEL FOR anon ON COLUMN users.email
IS 'MASKED WITH FUNCTION anon.fake_email()';
SECURITY LABEL FOR anon ON COLUMN users.first_name
IS 'MASKED WITH FUNCTION anon.fake_first_name()';
SECURITY LABEL FOR anon ON COLUMN users.last_name
IS 'MASKED WITH FUNCTION anon.fake_last_name()';
SECURITY LABEL FOR anon ON COLUMN users.phone
IS 'MASKED WITH FUNCTION anon.partial(phone, 2, $$XXX-XXX-X$$, 2)';
-- Generate a masked dump for staging
-- pg_dump_anon outputs a SQL dump with all masked values applied
pg_dump_anon mydb > staging_dump.sqlThese rules live in version control alongside your schema migrations. When your SOC 2 auditor asks "how do you handle test data?", you point them at this file and its commit history.
For a broader look at how masking fits into the test data lifecycle, see our guide on test data generation.
Database Branching as an Alternative Path
One approach that doesn't show up in most anonymization guides: using database branching to avoid the problem in a different way. Instead of masking a production snapshot and distributing it to your whole team, you start from a clean anonymized "golden image" and give every developer and every CI run an isolated branch off that image.
The anonymization work is done once, on the golden image. From there, branches diverge without ever touching production data. Engineers get realistic test data. Tests run in isolation. Nobody is sharing a mutable staging database that might contain production PII. The anonymization surface area shrinks from "every snapshot, for every environment, on every engineer's laptop" to "one image, maintained by one person, audited once."
If you're currently copying production snapshots ad-hoc, moving to a database branching workflow with a properly anonymized golden image is often a faster path to SOC 2 compliance than building a comprehensive per-environment masking pipeline. For a detailed comparison of synthetic, masked, and branch-based approaches from an engineering perspective, see our guide on test data generation.
How to Anonymize Production Data for Testing: A 4-Week Playbook
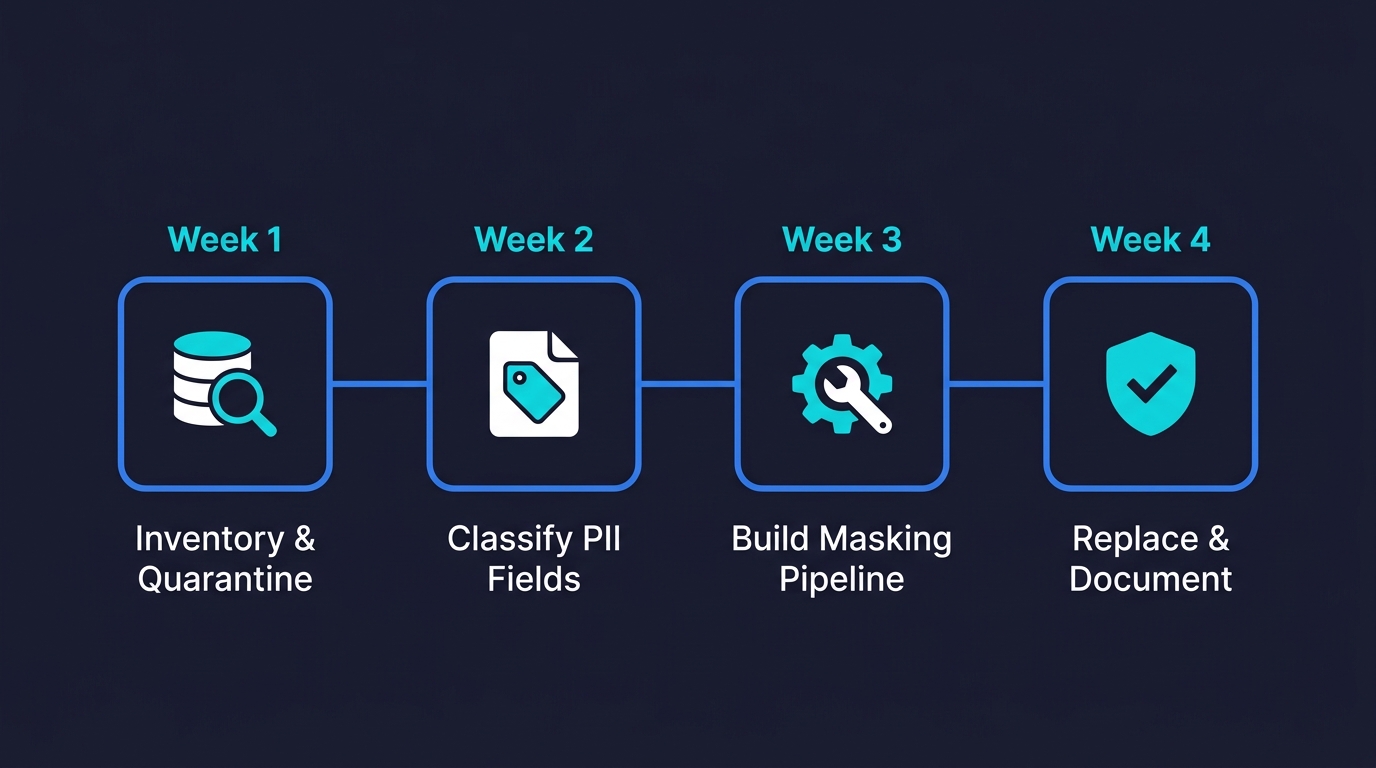
If you have three engineers and SOC 2 is six months away, you don't need a data governance platform for test data anonymization. You need a defensible, auditable process that you can explain to an auditor. Here's the sequence that actually works.
Week one: inventory and quarantine. Audit every non-production environment for production data. This means checking your staging database, your CI database, any data warehouse snapshots, and any local developer databases you know about. Document what you find. If you find production PII in any of these places, quarantine it: restrict access to the smallest number of people necessary and stop the flow of new production data into those environments until you have a masking pipeline in place.
Week two: classify your PII fields. Go through your production schema and tag every column that contains PII. Work from three categories: direct identifiers (name, email, phone, address, SSN, payment details), indirect identifiers (IP, device ID, behavioral sequences), and sensitive-but-not-personal (internal business data that isn't PII but that you'd rather not expose). This classification becomes your masking rule set.
Week three: build the masking pipeline. For most startups, this is a script that takes a production dump, applies masking rules column-by-column using Faker or postgresql-anonymizer, and writes the output. Start with direct identifiers only. Get that working, tested, and committed to your repo before moving to indirect identifiers. The pipeline should be runnable by anyone on your team with a single command. If it requires manual steps, it won't be run consistently.
Week four: replace all existing non-production data. Run the pipeline. Replace every production snapshot in staging and CI with masked data. Delete the originals. Document that you did this. This is the audit trail SOC 2 cares about.
From there, the ongoing practice is simple: never put production data into a non-production environment without running it through the masking pipeline first. Make the pipeline part of your runbook. Reference it in your SOC 2 security documentation. Enforce it in your incident response policy.
SOC 2 and GDPR Test Data Compliance
You don't need to become a compliance lawyer to get this right. The practical interpretation of both frameworks is consistent.
SOC 2 (Trust Services Criteria) doesn't mandate specific technical controls for test data. What it requires is that you demonstrate logical access controls and data handling practices that protect customer data across all environments. An auditor evaluating your test environments will look for evidence that production PII is not accessible to unauthorized parties and that you have a process for handling test data that's documented and followed. A masking pipeline in version control, plus evidence that you use it, satisfies this requirement. Using raw production data in staging with unrestricted developer access does not.
GDPR is more specific. Article 5 requires data minimization: you should only process personal data to the extent necessary for the purpose. Testing is not a purpose that requires real personal data. The legal basis for using production data in testing is weak; the legal basis for using masked or synthetic data is clear. GDPR also requires purpose limitation: data collected for one purpose (serving users) cannot be repurposed without a legal basis (testing is not one). Article 25 (data protection by design and by default) requires you to implement technical measures that limit data processing. Anonymizing test data is exactly that measure.
CCPA/CPRA applies if you have California users (which, if you're a US-based SaaS, you almost certainly do). The California Consumer Privacy Act gives users the right to know what data you collect and how it's used. Using real customer data in test environments is a processing activity that you'd need to disclose, and it's hard to justify under the "business purpose" exception. Anonymized data falls outside CCPA's scope entirely because it's no longer "personal information" under the statute. For most startups, the simplest CCPA strategy is the same as the GDPR one: don't put real data in test environments.
HIPAA matters if you handle protected health information (PHI), which includes any health data tied to an identifiable individual. If you're building in healthtech, telehealth, or any product that touches patient records, HIPAA's Security Rule requires you to implement safeguards for PHI in all environments, not just production. Using real patient data in staging or CI without proper access controls and audit logging is a direct HIPAA violation. The safe path is the same: anonymize or synthesize test data so PHI never enters non-production environments. HIPAA also has a "Safe Harbor" de-identification standard that specifies exactly which 18 identifiers must be removed for data to be considered de-identified.
The intersection of all these frameworks points to the same answer: anonymize your test data, document that you do it, and don't use production PII where you don't need to.
Where Autonoma Fits
One question that comes up when teams start building proper anonymization practices: what happens to testing when you switch from production snapshots to synthetic or masked data? Sometimes tests break because they were implicitly depending on real production edge cases that the anonymized data doesn't replicate.
This is actually one of the problems Autonoma is built to solve. Rather than writing tests that depend on specific data states, our Planner agent reads your codebase directly and generates test cases from your routes and user flows. It also handles database state setup automatically, generating the endpoint calls needed to put your database in the right state for each test. Your tests aren't fragile against data changes because they don't depend on pre-existing data snapshots; they build the state they need.
If you're anonymizing your test data as part of a SOC 2 push and finding that your existing test suite breaks against masked data, that's a signal that your tests are too tightly coupled to specific production records. It's a good problem to solve alongside the anonymization work.
Data anonymization in testing is the practice of transforming or replacing personally identifiable information (PII) in test databases and environments so that engineers and automated tests can work with realistic data without exposing real customer records. The best open-source tools for test data anonymization include postgresql-anonymizer, Neosync, Faker.js, Greenmask, and Microsoft Presidio.
Data masking replaces real values with realistic fake values (irreversible). Pseudonymization replaces real values with tokens using a consistent mapping that can theoretically be reversed with the right key. Masking is simpler and more commonly used for test environments. Pseudonymization is useful when you need consistent identifiers across related records (e.g., foreign key relationships) but is technically weaker from a privacy standpoint because the mapping can re-identify the data.
GDPR doesn't explicitly mandate test data anonymization, but it requires data minimization (Article 5), purpose limitation, and data protection by design (Article 25). Using real production PII in test environments without a legal basis is non-compliant. Anonymized or synthetic test data satisfies all three requirements and is the standard practice for GDPR-compliant engineering teams.
The best open-source data anonymization tools for startups are postgresql-anonymizer (for Postgres with declarative masking rules), Neosync (for an end-to-end anonymization pipeline), Greenmask (for Postgres with deterministic transformers and CI/CD integration), Faker.js or Faker (for scripted field-level masking), and Microsoft Presidio (for detecting PII in text fields). Most of these are free to self-host.
At minimum, anonymize all direct identifiers: names, email addresses, phone numbers, physical addresses, date of birth, payment card numbers, SSNs, government IDs, and health data. Also anonymize indirect identifiers: IP addresses, device fingerprints, and behavioral sequences tied to user IDs. For SOC 2 and GDPR compliance, any field that could identify a real individual, alone or in combination with other fields, should be masked or replaced with synthetic data in test environments.
SOC 2 (Trust Services Criteria) doesn't prescribe specific technical controls for test data, but it requires evidence of logical access controls and data handling practices that protect customer data across all environments. Auditors will look for a documented, enforced process that prevents production PII from being accessible to unauthorized parties in staging and CI. A masking pipeline in version control with an audit trail satisfies this requirement; using raw production data in staging with unrestricted access does not.
Data anonymization is the broader practice of making data non-identifiable through any technique. Data masking is one specific anonymization technique that replaces real values with realistic fakes while preserving the original format and data type. Other anonymization techniques include pseudonymization (reversible token replacement), generalization (reducing precision), synthetic data generation (fabricating new records), data swapping (shuffling values between records), perturbation (adding random noise), and tokenization (vault-based replacement).
Most startups can implement a basic test data anonymization pipeline in 3-4 weeks. Week one covers auditing existing environments for production PII. Week two classifies PII fields into direct identifiers, indirect identifiers, and sensitive business data. Week three builds the masking pipeline using tools like postgresql-anonymizer or Faker.js. Week four replaces all existing non-production data with masked versions and documents the process for SOC 2 audit readiness.



