
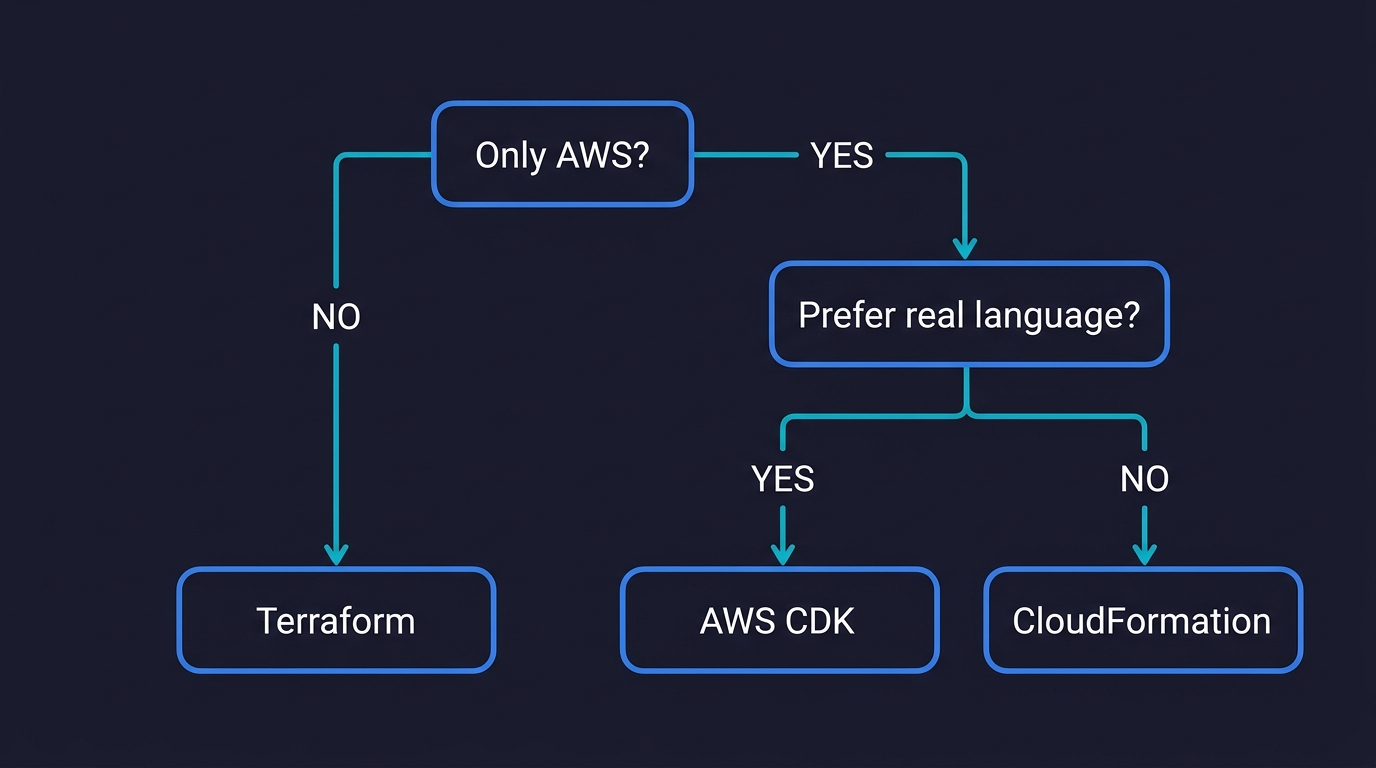
Infrastructure as code (IaC) is the practice of managing cloud infrastructure through version-controlled configuration files rather than manual console clicks or one-off scripts. Instead of logging into AWS and clicking through the UI to create a VPC, provision a database, or configure a load balancer, you write a Terraform or CloudFormation file that describes the desired state of your infrastructure. The tool reads that file, compares it to what already exists, and makes the necessary API calls to close the gap. Infrastructure as code is the foundation of modern infrastructure automation: repeatable, reviewable, and auditable by default. The three dominant infrastructure as code tools are Terraform (cloud-agnostic, HCL syntax, large ecosystem), CloudFormation (AWS-native, YAML/JSON, no state file to manage), and AWS CDK (TypeScript/Python that compiles to CloudFormation). Most startups should reach for Terraform unless they are strictly AWS-only with no external services.
The best argument for infrastructure as code is not compliance, not security, and not disaster recovery. It is speed. Teams with mature IaC practices ship infrastructure changes faster than teams without them, because every change goes through the same pull request workflow, gets reviewed, and is reversible in minutes if something goes wrong.
That changes the risk calculus for your engineers. When reverting a change is a one-line diff instead of a manual console walkthrough, people stop being afraid to make changes. Provisioning a new environment stops being a two-day project and becomes a 20-minute apply. Onboarding stops being a tribal knowledge transfer and becomes a git clone followed by a script.
This guide covers the practical path to infrastructure as code for startups, specifically for teams at the pre-seed to Series A stage where infrastructure decisions made today will either accelerate or constrain you for the next three years. It is based on what we have seen work across dozens of early-stage teams and the infrastructure as code best practices that actually matter at this scale.
The Evolution of Infrastructure Management: From Console to Infrastructure as Code
Understanding where infrastructure as code fits requires understanding the stages most teams go through on the way to full infrastructure automation.
Stage 1: The Console. One person, one environment, everything done through the AWS web interface. Fast to start, zero learning curve. The problem is that nothing is reproducible. If you need to recreate the environment, you are working from memory and screenshots. If someone else needs to make a change, they need walk-through documentation that is already out of date.
Stage 2: CLI scripts (imperative). Someone writes a bash script that wraps AWS CLI commands. It feels like progress, and it is. The steps are now captured in code. The problem is that scripts are imperative: they describe a sequence of commands to execute, not the desired end state. They do not know what already exists. Run the script twice and you might create duplicate resources or get an error because something already exists. Delete a resource manually and the script has no way to know. Imperative infrastructure code tells you what to do, not what should exist.
Stage 3: CloudFormation or Terraform (declarative). This is the declarative shift, and it is the core distinction that makes infrastructure as code powerful. Instead of writing steps, you describe what your infrastructure should look like, and the tool figures out the sequence of operations to get there. Create the same resource twice and it does nothing. Delete a resource manually and the next run recreates it. The tool compares desired state to actual state and reconciles the difference. Declarative infrastructure as code is idempotent by design: you can run it ten times and the result is the same as running it once.
Stage 4: CDK or Pulumi. Some teams go one level further: writing infrastructure in a general-purpose programming language (TypeScript, Python, Go) with real abstractions, loops, and type safety. AWS CDK compiles your TypeScript down to CloudFormation. Pulumi takes a similar approach but is cloud-agnostic. Our detailed AWS CDK vs CloudFormation comparison covers the practical differences with real code examples. For most startups, getting to Stage 3 confidently is the right priority.
The Real Cost of Not Adopting IaC
Most conversations about infrastructure as code focus on what you gain. Not enough focus goes on the cost of not using infrastructure as code, what you are paying right now by not having it. Let me be concrete.
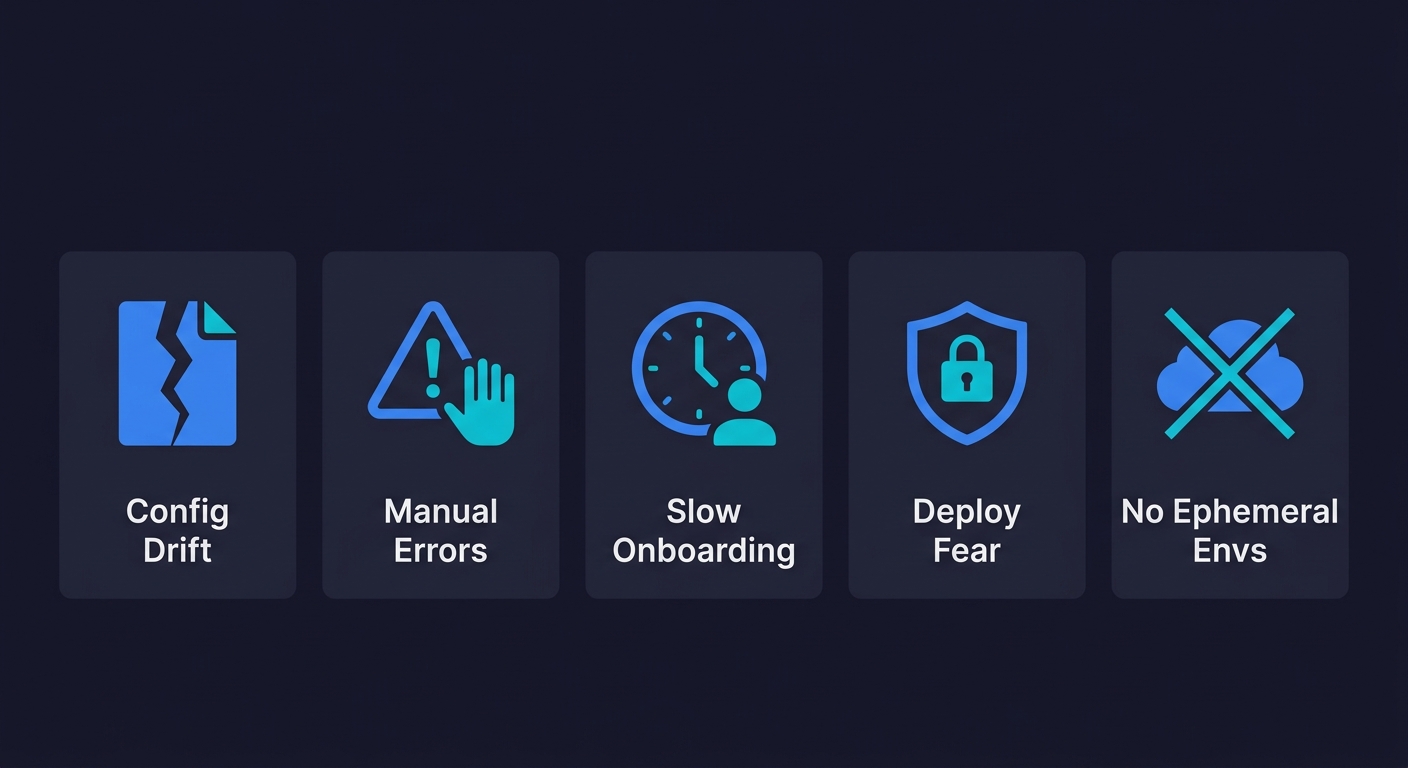
Configuration drift is silent and compounding. Drift happens gradually. An engineer makes a quick change in the AWS console during an incident. A new security group gets added manually. A database parameter gets adjusted without a ticket. None of these changes get documented anywhere. Within a few months, the actual state of your production environment no longer matches what anyone believes it to be. Staging drifts from production. You cannot reproduce bugs because the environments are not identical. Every change carries hidden risk because no one knows the full current state.
With IaC, every change goes through a file, a pull request, and a plan/apply cycle. If someone makes a console change, the next terraform plan shows the discrepancy immediately.
Manual errors at the worst possible time. Infrastructure changes tend to cluster around high-stress moments: launches, incidents, scaling events. That is exactly when manual, console-based workflows are most dangerous. The probability of a typo, a missed step, or a wrong region selection scales with pressure and fatigue. IaC removes the human execution step. You apply a reviewed configuration file, not a sequence of remembered steps under pressure.
Onboarding takes weeks instead of days. When infrastructure is console-managed, new engineers have no way to understand it without a guided tour from the one person who built it. With IaC, the configuration files are the documentation. A new hire clones the repo, reads the Terraform files, and understands the full topology before they run a single command. Onboarding time for infrastructure-related work drops from weeks to hours.
Deployment fear accumulates. Teams without IaC often develop a kind of deployment fear: a reluctance to make infrastructure changes because the blast radius is unknown and the process is manual. Changes that should take an hour get deferred for weeks because nobody wants to be the person who breaks production during manual execution. IaC, especially with a plan-in-PR workflow, makes the blast radius explicit before you apply anything. You can see exactly what will change. That visibility reduces fear.
Ephemeral environments become impossible. One of the highest-leverage things a growing startup can do is give every pull request its own isolated environment for testing. With manually-managed infrastructure, this is prohibitively expensive in human time: someone would need to manually provision a full stack per PR, then tear it down when the PR closes. With IaC, ephemeral environments are automatable. The CI pipeline runs terraform apply with a PR number as a variable, a full isolated stack spins up, tests run, and terraform destroy tears it down when the PR closes. No human involvement required.
Team Readiness Signals: When Your Startup Actually Needs IaC
I have been asked "when should we adopt IaC?" more times than I can count. The honest answer is: earlier than you think you need it, but there are concrete signals that tell you the window is closing.
Signal 1: More than one person makes infrastructure changes. The moment a second engineer has AWS console access and starts making changes, you have coordination risk. Who made what change, when, and why? Without IaC, you are relying on Slack messages and memory. With it, every change is a pull request with a plan diff that the team reviews.
Signal 2: You need a second environment. The moment you need staging, a QA environment, or per-PR preview environments, you need some mechanism to reproducibly create a matching infrastructure stack. Doing this manually once is painful. Doing it repeatedly is unsustainable. IaC makes environment parity a property of the configuration file, not a heroic one-time effort.
Signal 3: You have experienced a production incident caused by manual configuration. This one is unfortunately common. A security group change accidentally blocks traffic. A database parameter gets set incorrectly. A load balancer rule gets misconfigured. Most teams adopt IaC after their first incident of this kind. Adopting it before is clearly better.
Signal 4: Your team is approaching 4-5 engineers. At this team size, infrastructure knowledge can no longer live in one person's head. Knowledge transfer through console walkthroughs does not scale. IaC creates a shared, readable, version-controlled representation of your infrastructure that the whole team can contribute to and reason about.
If none of these signals apply yet, you are probably still in the "console is fine" stage. Enjoy it, but know that you will not stay there long.
Infrastructure as Code Tools Compared: Terraform vs CloudFormation vs CDK
Most IaC guides spend the comparison section either cheerleading for one tool or hedging so much that the comparison is useless. Here is the honest version.
Terraform is where most startups land, and for good reason. HCL is concise and readable. The Terraform Registry has community-maintained modules for almost every common pattern. The terraform plan output gives you a clear diff of exactly what will change before you apply it. The provider ecosystem covers hundreds of services beyond AWS: Cloudflare, Datadog, GitHub, PagerDuty, MongoDB Atlas, Vercel. Once your infrastructure includes even one non-AWS service (which almost every startup's does), Terraform lets you manage all of it from one tool.
The honest downsides: you need to manage state yourself. Setting up a remote backend correctly (S3 bucket for state, DynamoDB for locking) is a real configuration step, and getting it wrong early causes painful problems. A failed terraform apply can leave infrastructure in a partially-applied state that requires manual reconciliation. New AWS services can have a lag of weeks to months before a Terraform provider update covers them.
One thing worth knowing: in 2023, HashiCorp changed Terraform's license from open-source (MPLv2) to the Business Source License (BSL). The community forked it as OpenTofu under the Linux Foundation. For most startup use cases, the two are functionally equivalent. OpenTofu is the safer long-term bet if open-source licensing matters to your organization; Terraform has the larger existing ecosystem and documentation base. Either way, the HCL syntax, the provider model, and the plan/apply workflow are identical.
The learning curve for Terraform (or OpenTofu) is real but not steep. Most engineers are productive within 1-2 weeks. The hard concepts are not the syntax but the operational ones: understanding what the state file represents, what happens when it drifts from reality, and how to recover from partial applies. These are learnable.
For a detailed side-by-side breakdown of these two tools specifically, see our CloudFormation vs Terraform comparison.
CloudFormation is the right choice if your infrastructure is strictly and permanently AWS-only. No Cloudflare DNS. No Datadog. No GitHub repository configuration. No external monitoring. If that is genuinely your situation (uncommon but real), CloudFormation is elegant: AWS manages the state, automatic rollback happens when a stack update fails, and you get day-one support for every new AWS service. You pay for the AWS resources it creates, nothing for the tool itself.
The honest downsides: YAML templates are verbose. A moderately complex stack gets very long, very fast. The intrinsic function syntax (!Ref, !Sub, !GetAtt) is quirky. The feedback loop during stack updates is slower than Terraform's plan output. And the moment you reach for one service outside AWS, you need a second IaC tool.
AWS CDK is a strong option if your team is more comfortable writing TypeScript or Python than learning HCL or YAML. You write infrastructure in a real programming language with real abstractions, and CDK compiles it to a CloudFormation template. The developer experience is genuinely better for complex logic: you can use loops, conditionals, and typed constructs without CloudFormation's intrinsic function workarounds.
The honest downside: CDK compiles to CloudFormation, so it inherits all of CloudFormation's limitations. AWS-only scope. CloudFormation's state model. CloudFormation's feedback loop. If your infrastructure ever touches a non-AWS service, CDK does not help you there. Our AWS CDK vs CloudFormation comparison covers the practical differences in depth.
| Dimension | Terraform / OpenTofu | CloudFormation | AWS CDK |
|---|---|---|---|
| Cloud scope | AWS + 300+ providers | AWS only | AWS only (compiles to CloudFormation) |
| Syntax | HCL (concise) | YAML / JSON (verbose) | TypeScript, Python, Go, Java |
| State management | You manage (S3 + DynamoDB) | AWS manages it | AWS manages it (via CloudFormation) |
| Rollback on failure | Manual recovery | Automatic (AWS-managed) | Automatic (via CloudFormation) |
| New AWS service lag | Weeks to months | Day one | Day one |
| Learning curve | 1-2 weeks (HCL + state) | 1-2 weeks (YAML + AWS docs) | 1-2 weeks (familiar language, new constructs) |
| Module/reuse ecosystem | Large (Terraform Registry) | Smaller (CloudFormation Registry) | Construct Hub (growing) |
| Non-AWS services | Yes (Cloudflare, Datadog, etc.) | No | No |
| License | BSL (Terraform) / MPLv2 (OpenTofu) | Proprietary (AWS service) | Apache 2.0 |
| Cost | Free | Free | Free |
What the Code Actually Looks Like
Comparisons are easier to evaluate when you can see the syntax. Here is the same resource, an S3 bucket, in Terraform and CloudFormation:
# Terraform / OpenTofu
resource "aws_s3_bucket" "app_assets" {
bucket = "myapp-assets-${var.environment}"
tags = {
Environment = var.environment
ManagedBy = "terraform"
}
}# CloudFormation
Resources:
AppAssets:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub "myapp-assets-${Environment}"
Tags:
- Key: Environment
Value: !Ref Environment
- Key: ManagedBy
Value: cloudformationThe Terraform version is more concise. The CloudFormation version is more verbose but requires no external tooling or state management. Both are declarative: they describe what should exist, and the tool figures out how to get there.
Infrastructure as Code Adoption Roadmap for Startups
The common mistake is treating IaC adoption as a big-bang migration: freeze all infrastructure changes, spend two weeks writing configuration files, then cut over. This approach fails because it delays value, accumulates risk, and requires a heroic one-time effort from an already-busy team.
The better approach is incremental.
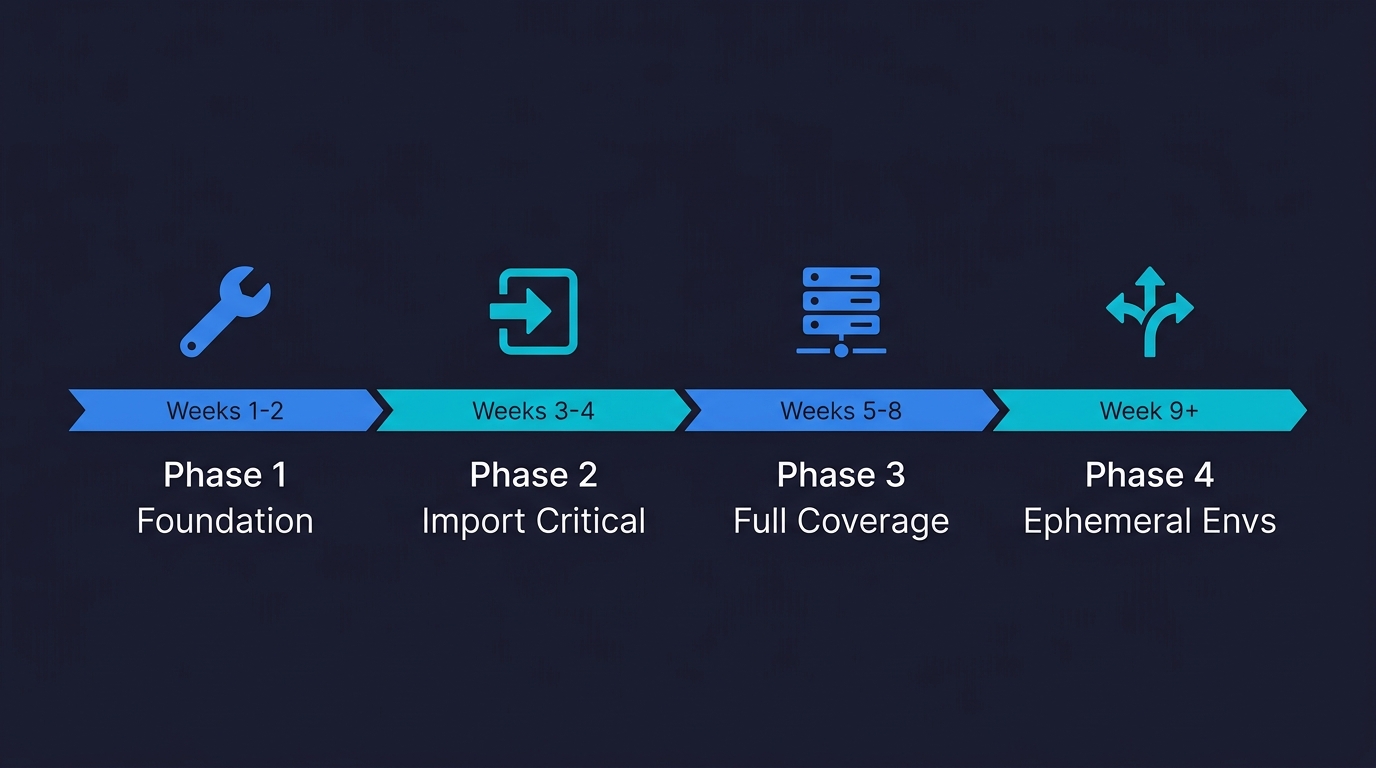
Week 1-2: Establish the foundation without migrating anything. Set up your Terraform (or CloudFormation) project structure, configure the remote state backend, and write your first resource: something new, not something that already exists. Maybe a new S3 bucket. Maybe a new IAM role. The goal is to get the toolchain working and the team familiar with the plan/apply cycle before you touch anything in production.
This is also when you configure the CI integration: running terraform plan on pull requests and posting the diff as a comment. Engineers should see plan output in PRs before they see it anywhere else.
Week 3-4: Import your most critical existing resources. Use terraform import to bring your most important existing resources into Terraform's state without recreating them. Start with the resources that change most often and therefore carry the most risk when changed manually. The database. The VPC. The load balancer configuration.
The first import is the hardest because you need to write the HCL that matches the existing resource's current configuration exactly. Run terraform plan after import and iterate until the plan shows no changes. That zero-diff plan is your signal that the HCL correctly represents reality.
Week 5-8: Cover the rest of production, then replicate to staging. Continue importing remaining production resources. Once production is fully covered, use the same configuration files to stand up staging by changing a few variable values. If staging requires a smaller footprint (smaller instance types, no read replicas), Terraform variables make that straightforward.
This is the moment where IaC's value becomes concrete: you can describe your entire production topology in a few hundred lines of HCL and spin up a complete replica with a single command.
Week 9+: Enable ephemeral environments. With production and staging covered, add a CI pipeline job that uses Terraform workspaces (or parameterized stacks) to provision a complete environment per pull request. The PR number becomes a variable. The environment is destroyed when the PR closes. This is where the compounding returns on IaC start to show up: your team ships faster because reviewers have a real, isolated environment to test against, not a shared staging environment where multiple PRs contend for the same database.
For a detailed look at how ephemeral environments work in practice and how to architect the database layer specifically, see our ephemeral environments guide.
Infrastructure as Code Best Practices: Common Mistakes to Avoid
Most adoption failures follow predictable patterns. Here are the ones I have seen most often.
Storing state locally. Terraform's default is to write the state file to the local filesystem. This works for one engineer on one machine. The moment a second engineer runs terraform apply, you have two state files that diverge. Set up the remote backend before anyone but you runs any Terraform command. This is not optional.
Putting everything in one file. Large flat Terraform configurations become hard to reason about quickly. The right structure separates by environment (production, staging, shared) and by service domain (networking, compute, database). Modules help share patterns without duplicating configuration. Getting the structure right early costs an afternoon. Refactoring a 2,000-line main.tf under time pressure costs much more.
Skipping the plan review. terraform plan exists for a reason. The discipline of reading the plan output before every apply, and requiring a second set of eyes on plan diffs in pull requests, catches most mistakes before they reach production. Teams that skip this step tend to have their first significant incident when an apply deletes or replaces a resource they thought was being updated in place.
Hardcoding secrets. Credentials, API keys, and database passwords should never appear in a Terraform configuration file, even in a private repository. Use environment variables for provider credentials. Reference secrets from AWS Secrets Manager or Parameter Store for application-level secrets. Keep the configuration files readable in code review without exposing sensitive values.
The split-state trap. This is the most insidious one. A team adopts Terraform for new resources but leaves all existing manually-managed resources untouched. Over time, half the infrastructure is in Terraform and half is still managed through the console. Nobody has a clear picture of the full topology. New engineers cannot understand the system by reading the Terraform files because the files only tell half the story. Commit to full coverage of your production environment within a defined timeline. Partial coverage is better than nothing, but it has its own kind of ambiguity cost.
What Infrastructure as Code Unlocks Beyond Provisioning
This is the part that surprises teams the most.
Security, compliance, and policy-as-code. Once your infrastructure is code, every change has an author, a reviewer, a timestamp, and a reason. That audit trail is exactly what SOC 2, ISO 27001, and investor due diligence reviews ask for. Tools like Checkov scan your Terraform files for misconfigurations before deployment: public S3 buckets, unencrypted databases, overly permissive security groups. OPA (Open Policy Agent) and HashiCorp Sentinel let you enforce organizational policies as code, so violations are caught in the PR, not in a quarterly audit. For startups approaching Series A, this compliance evidence comes essentially for free when your infrastructure is already managed through version-controlled files.
Reviewable, testable infrastructure. A junior engineer can propose an infrastructure change through a pull request and a senior engineer reviews the plan diff, just like they review a code diff. You can enforce policies (no public S3 buckets, all resources must be tagged, no instances larger than a certain type without explicit approval) and write integration tests that spin up a real environment, run assertions against it, and destroy it.
Ephemeral and preview environments. The unlock most relevant to engineering velocity is ephemeral environments. Once you can describe your full infrastructure in code and apply it repeatably, spinning up per-PR environments becomes a CI job, not a manual effort. Every pull request gets its own isolated stack. For teams using platforms like Vercel or Netlify, preview environments provide a simpler path for frontend deploys, but IaC-based ephemeral environments give you full-stack isolation including databases and backend services. The feedback loop between writing code and validating it against a production-like environment collapses from days to minutes.
Disaster recovery as a side effect. Once your infrastructure is fully described in code, recreating it in a different region becomes a terraform apply with a different region variable. This is not the primary reason to adopt infrastructure as code, but it is a powerful side effect. Your IaC files plus your data backups equal the simplest disaster recovery plan a startup can have.
Once those ephemeral environments exist, the logical next step is automated testing against each one. That is where Autonoma comes in: connect your codebase, and the Planner agent reads your routes and components to generate tests automatically. The Automator runs them against the ephemeral environment URL on every PR. No test scripts to write or maintain. The codebase is the spec.
The Honest Verdict on Infrastructure as Code for Startups
Infrastructure as code is one of the highest-leverage investments a growing engineering team can make. Not because the tools are elegant (some are, some are not) but because the alternative, a manually managed infrastructure that exists primarily in one engineer's memory and the AWS console, compounds in the wrong direction every month you leave it in place.
The question CTOs ask me most is not "should we adopt IaC" but "are we too early?" The answer is almost always no. The cost of adopting IaC before you need it is a few weeks of setup and learning. The cost of waiting until after your first significant manual configuration incident, or until you have three engineers stepping on each other in the console, or until you have spent six months trying to replicate a production bug in a staging environment that no longer matches production, is much higher.
Start with Terraform. Set up the remote backend on day one. Import your most important existing resources in the first month. Get a staging environment standing up from the same configuration files within 60 days. By day 90, you will have the foundation to enable ephemeral environments per PR, and the compounding returns on that investment continue for as long as the team is shipping.
Infrastructure as code (IaC) is the practice of managing and provisioning cloud infrastructure through machine-readable configuration files rather than through manual console clicks or ad-hoc scripts. Instead of logging into AWS and clicking through the UI to create a database or configure a VPC, you write a Terraform or CloudFormation file that describes the desired state of your infrastructure. The tool reads that file and makes the necessary API calls to reach that state. This makes your infrastructure reproducible, version-controlled, and auditable.
The practical signal is when one of three things happens: your team grows past 3-4 engineers and more than one person is making infrastructure changes, you need a second environment (staging, preview) that should mirror production, or you experience your first production incident caused by a manual configuration mistake. Any of these indicates that the informal approach of clicking through the console has outgrown your team size. Earlier adoption is better, but these are the moments where the cost of not having IaC becomes concrete.
Most engineers are productive with Terraform within 1-2 weeks. The core concepts (providers, resources, variables, outputs, state) are learnable in a day. The harder parts are state management (setting up a remote backend correctly, understanding what happens when state drifts from reality) and module structure for larger codebases. The practical blocker is usually the first time something goes wrong during an apply and the team needs to recover from partial state. Terraform's documentation is good and the community is large, so most problems have well-documented solutions.
Configuration drift is when the actual state of your cloud infrastructure no longer matches what your team believes it to be. It happens gradually: an engineer makes a quick change in the AWS console during an incident, a security rule gets added manually, a database parameter gets adjusted without a ticket. Over time, no one knows the authoritative state of the system. IaC eliminates drift because every change goes through a file, a pull request, and a plan/apply cycle. If someone makes a console change, the next terraform plan will show the discrepancy.
Terraform is the default choice for most startups because it handles non-AWS services (Cloudflare, Datadog, GitHub, etc.) alongside AWS resources from a single tool. CloudFormation is the right choice if you are 100% AWS with no external services and want zero state management overhead. AWS CDK is a strong option if your team is more comfortable with TypeScript or Python than with HCL or YAML, but it compiles to CloudFormation so it remains AWS-only. For a detailed comparison of CloudFormation and Terraform specifically, see our CloudFormation vs Terraform guide.
The most common mistakes are: storing state locally instead of in a remote backend (which breaks as soon as a second engineer runs apply), putting everything in one giant file instead of separating by environment and service, skipping the plan review and running apply blindly, hardcoding secrets and credentials in configuration files instead of using environment variables or a secrets manager, and adopting IaC for new resources while leaving existing manually-managed resources unimported, creating a split state that confuses everyone.
Imperative IaC (like bash scripts wrapping CLI commands) describes a sequence of steps to execute: create this VPC, then create this subnet, then attach this security group. Declarative IaC (like Terraform and CloudFormation) describes the desired end state: this VPC should exist with these subnets and these security groups. The tool compares the desired state to the actual state and figures out the steps to reconcile them. Declarative IaC is idempotent, meaning you can run it multiple times and the result is the same as running it once.
OpenTofu is a community fork of Terraform created in 2023 after HashiCorp changed Terraform's license from open-source (MPLv2) to the Business Source License (BSL). OpenTofu is maintained under the Linux Foundation and remains fully open-source. For most practical purposes, the two are functionally equivalent: same HCL syntax, same provider ecosystem, same plan/apply workflow. OpenTofu is the safer choice if open-source licensing is important to your organization.



