
API testing strategy for startups means prioritizing coverage on the three endpoint categories enterprise clients actually scrutinize during due diligence: authentication/authorization, payment and billing flows, and core business logic. Contract testing protects your API consumers from breaking changes. Integration testing verifies your dependencies behave. With a small team and hundreds of endpoints, you need a prioritization framework, not exhaustive coverage. AI-generated tests that self-heal as your API evolves are how lean teams achieve enterprise-grade reliability without a dedicated QA function.
The enterprise due diligence call comes earlier than you expect. Before the signed contract, before procurement gets involved, someone on their engineering team will ask: "How do you test your API?" What they're really asking is whether you'll break their integration at 2am, and whether you'll know about it before their users do.
Most startups stumble here. Not because the API is bad, but because the testing story is whatever made sense last sprint: some Postman collections, a few integration tests that haven't been touched in months, and a mental model of which endpoints "should" be reliable. That's not a story enterprise clients can take back to their own security teams.
Getting from "ad hoc" to "credible" doesn't require a QA hire or a quarter-long project. It requires knowing exactly which endpoints to prioritize and which testing approaches actually move the needle.
What Enterprise Clients Are Actually Evaluating
Before we talk about test types and tooling, it's worth understanding what enterprise technical due diligence actually looks at. Their engineers aren't running your tests. They're asking about your process.
The questions that come up consistently: Do you have automated API tests in CI? What happens when a breaking change is introduced? How do you handle versioning? What's your SLA on API uptime and how do you monitor it? Have you had a SOC 2 audit or are you pursuing one?
These questions map directly to capabilities you either have or don't. An enterprise client integrating your API into their workflow is taking on operational risk. They need evidence that you take it seriously, and documentation goes only so far. Working automated tests that run on every deploy are evidence. A Notion page with test cases is not.
The Three Endpoint Categories That Matter Most
You have 200 endpoints. You have three engineers. The math doesn't work if you try to test everything equally. The good news is you don't need to.
Authentication and Authorization
Auth is where enterprise clients focus first, and for good reason. A bug in your auth layer doesn't just cause a bad user experience. It's a potential breach. And a breach is a deal-killer.
What needs to be covered: token issuance, token expiry, refresh flows, permission boundaries between user roles, and revocation. The permission boundary tests are the ones most teams skip. You need to verify that a standard user cannot call an endpoint that requires admin access, and that service-to-service tokens are scoped correctly. These tests are simple to write and catastrophic to be missing.
Rate limiting sits here too. Enterprise clients want to know that one misbehaving integration can't take down your service for everyone else. Test that your rate limiting actually kicks in at the thresholds you document.
Payment and Billing Flows
If money moves through your API, this is your highest-risk surface area. Payment bugs have a unique property: they're often silent. A failed charge might not throw an error the user sees. A double-charge might go unnoticed until the customer service tickets arrive.
Test the happy path, but don't stop there. Test declined cards. Test webhook delivery from your payment provider and what happens when webhooks arrive out of order. Test what happens when a subscription renewal fails mid-cycle. Test refund flows. The edge cases here are exactly what trips up API integrations at scale.
If you're preparing for enterprise sales, you should also be able to demonstrate that payment-related endpoints are covered in your test suite. It comes up in SOC 2 readiness assessments.
Core Business Logic
This is the category that's specific to your product. Whatever your API does that no one else's does, those endpoints are your differentiation, and they're what enterprise clients are integrating. They need to work reliably at their scale, not just yours.
The practical question is: if this endpoint returned wrong data, what's the blast radius? Start there. Rank your business logic endpoints by the severity of incorrect output, and build coverage from the top down. Test data management matters here, because business logic tests need realistic data states to surface real bugs.
For teams looking to complement their API testing with end-to-end user flow validation, Autonoma adds AI agents that test your full application on real browsers — catching the integration issues that API tests alone can't surface.
API Security Testing Beyond Authentication
Auth testing covers who can access what. Security testing covers whether your API can be exploited. Enterprise security questionnaires and penetration test reports probe both, and they're not the same conversation.
The OWASP API Security Top 10 is the framework most enterprise security teams reference. For a startup, the highest-priority items are: Broken Object Level Authorization (BOLA), where a user can access another user's resources by manipulating IDs in requests; mass assignment, where an API accepts fields it shouldn't (like a role or permissions field on a user update endpoint); and injection vulnerabilities in any endpoint that passes user input to a database query or command.
Testing for these doesn't require a dedicated security team. A permission boundary test that verifies user A cannot read user B's data by swapping resource IDs covers BOLA. A test that sends unexpected fields in a request body and verifies they're ignored covers mass assignment. Input validation tests that send SQL injection patterns and verify they're rejected cover the injection surface.
// Permission boundary test: verify BOLA protection
const userAToken = await getAuthToken("user-a@example.com");
const userBResourceId = "resource-belonging-to-user-b";
const response = await request(app)
.get(`/api/v1/resources/${userBResourceId}`)
.set("Authorization", `Bearer ${userAToken}`);
// User A should NOT be able to access User B's resource
expect(response.status).toBe(403);These tests are fast to write and show up directly in enterprise security reviews. If your API handles personal data, they also intersect with GDPR compliance testing requirements around data access controls.
Contract Testing vs Integration Testing: When to Use Which
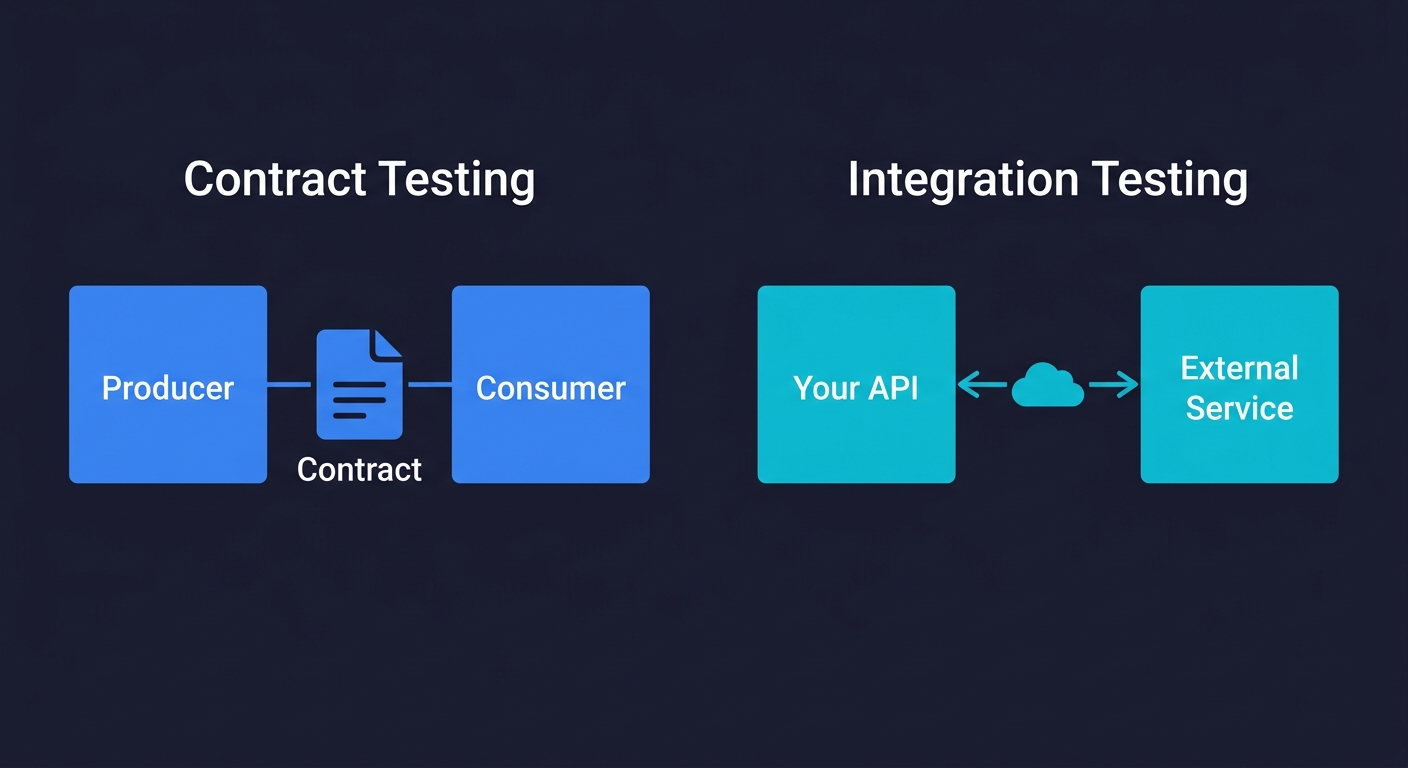
This is one of the most misunderstood distinctions in API testing, and it has real consequences for how you structure your test suite.
Integration testing answers: "Does my system correctly talk to this dependency right now?" You're running tests against a real or simulated version of an external service and verifying the interaction works. Integration tests are good at catching "the third-party API changed their response format" bugs. They're slow because they hit real network boundaries, and they're flaky when external services have reliability issues.
Contract testing answers: "Have either side of this API relationship changed in a way that would break the other?" Rather than running the full integration at test time, contract testing captures the expected request/response shape (the "contract") and verifies both the producer and consumer independently adhere to it. Tests run faster, pass more reliably, and give you earlier warning of breaking changes.
For a startup building toward enterprise sales, the practical division is this: use contract testing to protect against breaking changes in your own API (your consumers need this guarantee), and use integration testing to catch regressions in how your system handles third-party dependencies.
| Dimension | Contract Testing | Integration Testing |
|---|---|---|
| Primary question | Will this change break consumers? | Does my system work with this dependency? |
| Speed | Fast (no live services) | Slow (real network calls) |
| Flakiness | Low | Higher (external dependencies) |
| Best for | API versioning, consumer protection | Third-party service changes, real-world behavior |
| When to prioritize | Before enterprise clients integrate | Throughout development |
The tooling landscape for contract testing is anchored by Pact, which handles both the consumer-driven contract side and the producer verification. If you're using OpenAPI or Swagger specs, schema validation tools can verify that your API responses match the documented contract automatically. For integration testing, the approach depends on your stack. The important thing is that both live in CI so they run on every pull request, not just before a release.
Here's what a minimal Pact consumer test looks like:
// Consumer-side contract test with Pact
const { PactV4 } = require("@pact-foundation/pact");
const pact = new PactV4({ consumer: "WebApp", provider: "PaymentAPI" });
pact.addInteraction()
.uponReceiving("a request for payment status")
.withRequest("GET", "/api/v1/payments/pay_123")
.willRespondWith(200, {
body: { id: "pay_123", status: "completed", amount: 4999 }
});
// If PaymentAPI changes this response shape, the contract breaks
// BEFORE it reaches productionHow to Prioritize When You Have 3 Engineers and 200 Endpoints
The prioritization framework that works in practice is based on two axes: the business impact of a failure and the likelihood of change. Endpoints that are high-impact and frequently changing need continuous test coverage. Endpoints that are low-impact and stable can be covered with lighter-weight contract snapshots, or skipped in the first pass.
High-impact means: revenue is directly affected, the endpoint is in the critical path of a customer integration, or failure would trigger an SLA breach. Frequently changing means: the endpoint is actively being developed, it depends on third-party services that are also evolving, or it has historical bugs.
When you plot your 200 endpoints on this grid, you'll usually find that 15-20% of them fall in the top-right quadrant. Those are your priority. Everything else can wait.
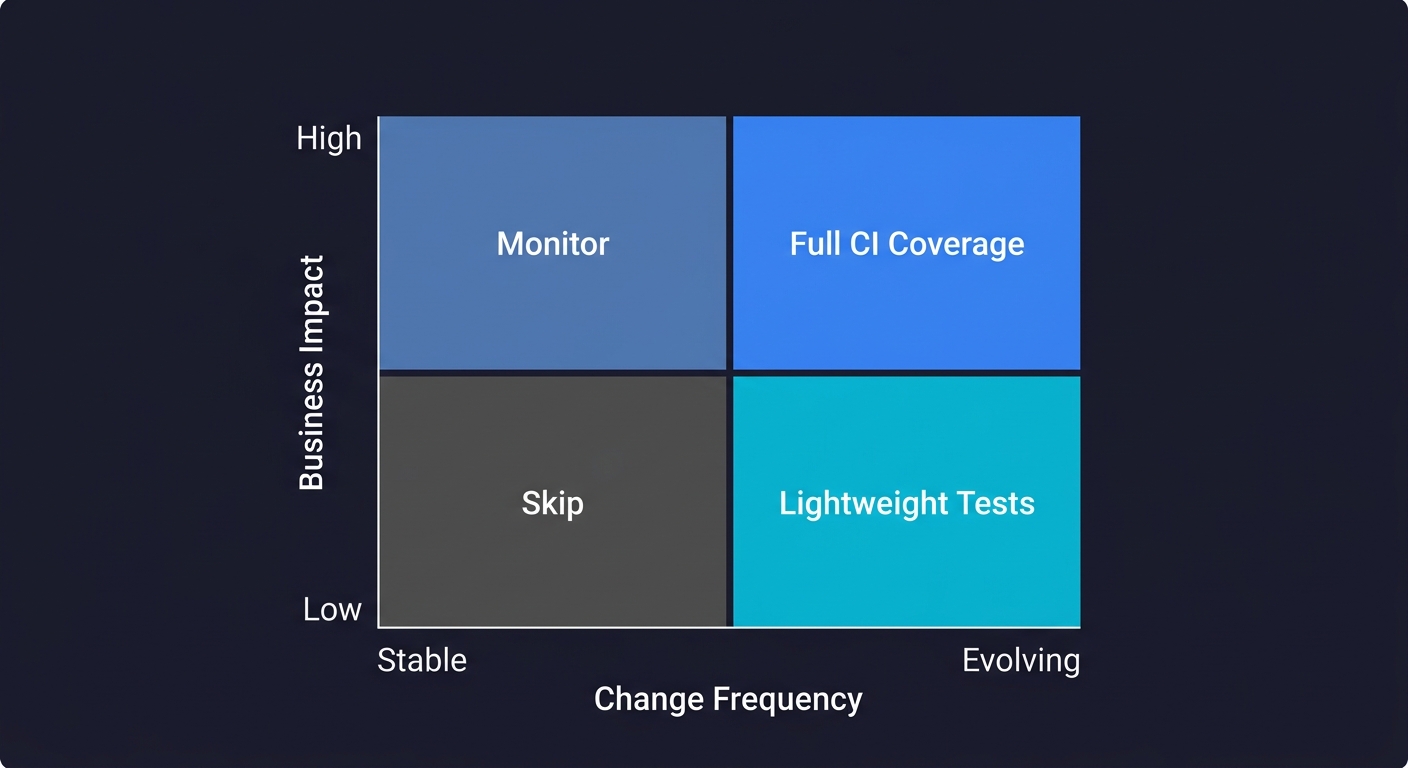
| Stable (low change frequency) | Actively Evolving (high change frequency) | |
|---|---|---|
| High business impact | Contract snapshots, monitor in production | Full CI coverage, contract tests, monitoring (your top priority) |
| Low business impact | Skip in first pass | Lightweight integration tests |
The other piece of prioritization that teams miss: test the seams, not the internals. Enterprise clients don't care that your internal service-to-service calls are perfectly tested. They care that the API surface they're integrating with is stable. Start there, then work inward.
For teams running containerized environments, this prioritization is especially powerful because you can stand up isolated test environments quickly, run the critical-path tests on every PR, and catch regressions before they reach any client integration.
API Versioning Strategy Basics
Enterprise clients have long integration timelines. Once they've built against your v1 API, breaking changes in v2 are expensive for them, which means they're expensive for you. Version your API before your first enterprise client integrates, not after.
The minimum viable versioning approach: version in the URL path (/v1/resources), maintain previous versions for at least two major release cycles, and communicate deprecations in writing with at least 90 days notice. This isn't complex to implement, but it is complex to retrofit after you've already made breaking changes.
The testing implication: your contract tests should be version-scoped. A change that's valid in v2 should not silently break v1 consumers. If you're using Pact or a similar contract testing tool, this scoping is straightforward. If you're not, it's a risk.
API versioning also shows up in the due diligence conversation. Being able to say "we version our API and have a documented deprecation policy" is a meaningful signal that you've thought about enterprise integration at more than a surface level.
Monitoring and Alerting on API Health
Tests that run in CI are necessary but not sufficient. They tell you the API worked at build time, in your test environment, with test data. Production is different.
The monitoring layer that matters for enterprise readiness covers three things: uptime, latency percentiles, and error rate by endpoint. Uptime is the obvious one, but p95 latency is what enterprise clients negotiate into SLAs. If your API is returning 200s in 4 seconds at p95, a client with a synchronous integration will notice before you do.
Error rate by endpoint is where you catch the silent failures. A 2% error rate on your webhook delivery endpoint might not show up as a support ticket immediately. In a monitoring dashboard, it's obvious.
For the due diligence conversation, being able to show historical uptime data and describe your alerting setup is meaningful. You don't need a 99.99% SLA on day one. You need to demonstrate that you know when something goes wrong and have a process for addressing it.
Ephemeral environments make it easier to verify that monitoring is correctly configured per PR, rather than discovering in production that a new endpoint has no alerting attached.
Performance and Load Testing
Monitoring tells you how the API performs in production. Performance testing tells you how it will perform before your largest client goes live. Enterprise SLAs include response time guarantees, and you need evidence that your API can deliver them under load.
You don't need a dedicated performance engineering team. You need a load test script that runs against your staging environment and proves your critical endpoints handle 3-5x your expected peak traffic. k6 is the most developer-friendly option for this: tests are written in JavaScript and can run in CI.
// k6 load test: verify /api/v1/payments handles enterprise load
import http from "k6/http";
import { check } from "k6";
export const options = {
stages: [
{ duration: "1m", target: 100 }, // ramp to 100 concurrent users
{ duration: "3m", target: 100 }, // hold steady
{ duration: "1m", target: 0 }, // ramp down
],
thresholds: {
http_req_duration: ["p(95)<500"], // p95 latency under 500ms
http_req_failed: ["rate<0.01"], // less than 1% error rate
},
};
export default function () {
const res = http.get("https://staging.yourapi.com/api/v1/payments");
check(res, { "status is 200": (r) => r.status === 200 });
}Run this before any enterprise onboarding. The output gives you concrete numbers to put in SLA negotiations: "Our payments endpoint handles 100 concurrent users with p95 latency under 500ms." That's the kind of evidence enterprise buyers want.
The Enterprise Readiness Checklist

This is what a thorough enterprise technical review will probe. Not every client will ask all of this, but being able to answer confidently positions you as an engineering organization that has thought past MVP.
API security
- Authentication tokens expire and are scoped correctly
- Permission boundaries are tested (BOLA, role escalation)
- Rate limiting exists and is tested at documented thresholds
- No PII in API logs or error responses
Reliability evidence
- Automated API tests run in CI on every deploy
- Historical uptime metrics available for the past 90+ days
- Runbooks exist for common failure modes
- Incidents are post-mortemed and post-mortems are accessible
Integration stability
- API is versioned with a documented deprecation policy
- Contract tests exist for consumer-facing endpoints
- Breaking changes require a version bump and consumer notification
- Changelog or release notes published for API changes
Compliance groundwork
- GDPR compliance testing for APIs handling personal data
- Data retention and deletion flows are tested
- You can answer "where does our customers' data live?" without hesitation
Observability
- Distributed tracing in place or a clear plan for it
- Error rates monitored per endpoint with alerting thresholds
- p95 latency tracked, not just uptime
Getting all of this in place before a single enterprise call is unrealistic. But being able to check the boxes on the first four items, with a credible plan for the rest, is usually enough to move forward.
How AI-Generated Tests Change the Equation for Lean Teams
The traditional blocker for startups building serious API test coverage is maintenance. You write tests for your 15 critical endpoints. Then the API evolves, the tests break, and no one has time to fix them. Six months later the test suite is commented out and you're back to manual spot checks before releases.
This is the problem that AI-generated testing addresses directly. Tools like Autonoma connect to your codebase, and a Planner agent reads your routes and API contracts to generate test cases automatically. When your API changes, a Maintainer agent updates the tests to match. You don't carry the maintenance burden.
The practical difference: your three engineers can focus on features and architecture while your API test coverage stays current. When the enterprise due diligence call comes, the test suite is real and up to date, not something you scaffolded the week before.
The Planner agent also handles database state setup for each test scenario. Testing an endpoint that requires a specific account tier, a specific resource state, or a specific permission configuration normally means writing a lot of brittle setup code. The agent generates the endpoints needed to put your system in the right state, then runs the test, then cleans up. What used to be the tedious part of API testing becomes handled.
Choosing the Right API Testing Tools
The API testing tools landscape is broad, but for a startup with limited engineering capacity, you need tools that are low-overhead to adopt and maintain. Here's how the options break down by use case:
| Use Case | Tool | Why It Fits Startups |
|---|---|---|
| Contract testing | Pact | Open-source, widely adopted, CI-friendly |
| Integration testing (Node.js) | Supertest | Lightweight, familiar syntax, fast setup |
| Integration testing (Python) | pytest + httpx | Pythonic, async support, minimal boilerplate |
| Integration testing (Java) | Rest Assured | Mature, well-documented, BDD-style assertions |
| Performance/load testing | k6 | Developer-friendly, scriptable in JS, runs in CI |
| API monitoring | Datadog / Grafana | Endpoint-level dashboards enterprise clients expect |
| AI-assisted testing | Autonoma | Generates and maintains tests from your codebase |
The key question isn't which tool is "best." It's whether your team will maintain the tests six months from now. If the answer is uncertain, that's the strongest argument for AI-assisted testing that handles maintenance automatically.
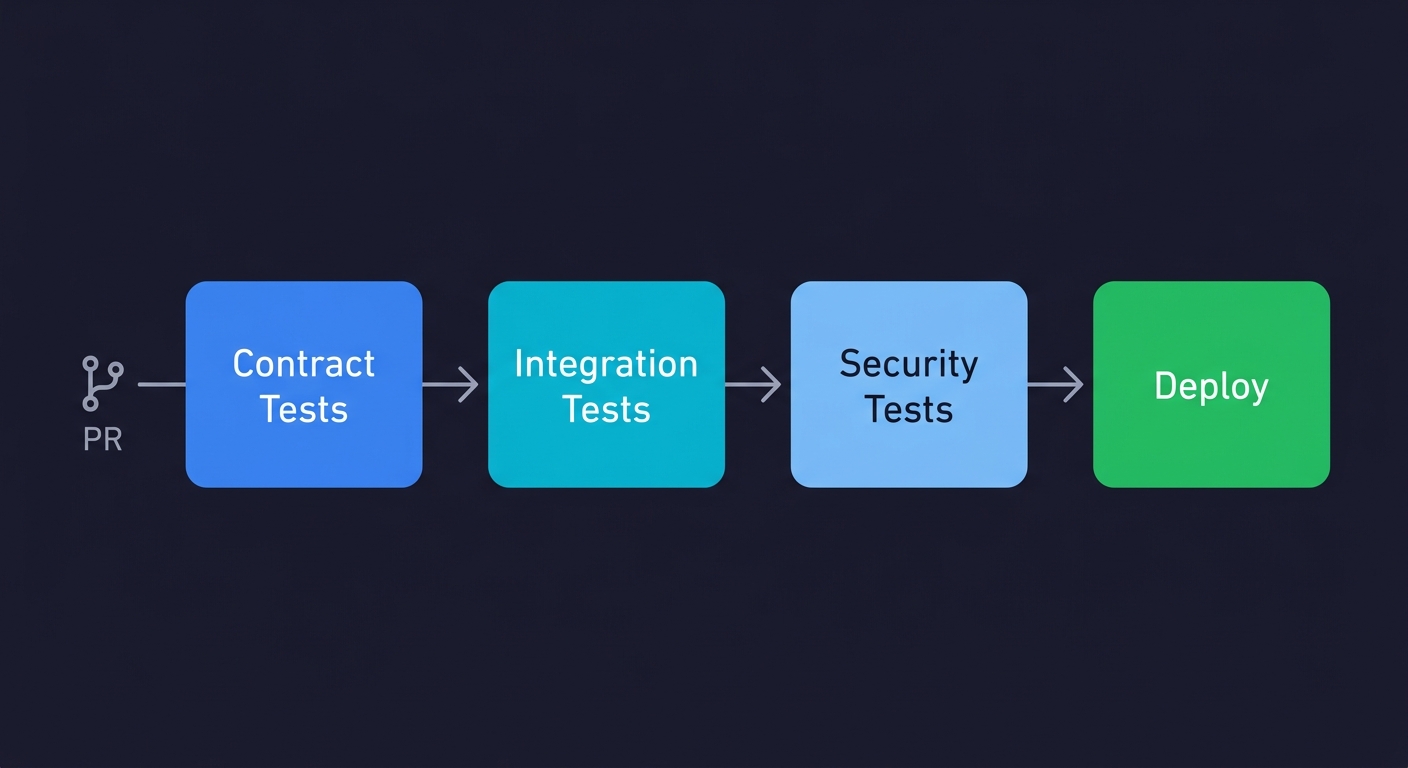
A minimal CI configuration that ties it all together looks like this:
# .github/workflows/api-tests.yml
name: API Tests
on: [pull_request]
jobs:
api-tests:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- run: npm ci
- run: docker compose up -d # start dependencies
- run: npm run test:contract # contract tests first (fast)
- run: npm run test:integration # integration tests
- run: npm run test:security # permission + input validationAPI Testing Best Practices: Where to Start Tomorrow
If you're three months from your first enterprise prospect and your API test coverage is sparse, here is the order of operations that gets you to "ready" fastest.
Start with auth. Write tests for your token flows, permission boundaries, and rate limiting this week. These are high-impact, relatively fast to write, and show up first in security reviews.
Add contract tests for your top five consumer-facing endpoints. If you're not using a contract testing tool yet, Pact is the most widely adopted option. Getting this in place before external integrations lock you into a particular shape is much easier than retrofitting it.
Set up endpoint-level error rate monitoring. Pick a tool, pick your five highest-risk endpoints, and make sure you'll know within 15 minutes if one starts returning 5xx responses. This doesn't require a major investment.
Then expand from there. The goal isn't 100% coverage before your first enterprise call. The goal is being able to say "our critical paths are covered in CI, we version our API, we have monitoring on key endpoints, and we have a plan for expanding coverage as we grow." That answer closes deals.
Frequently Asked Questions
An API testing strategy is a plan for which endpoints to test, what types of tests to run (contract, integration, end-to-end), how tests are organized in CI, and how coverage expands over time. For startups, a good API testing strategy prioritizes high-impact endpoints (auth, payments, core business logic) and builds from there. Tools like Autonoma can generate and maintain API tests automatically from your codebase, so the strategy doesn't require a dedicated QA function to execute.
Contract testing verifies that both sides of an API relationship (producer and consumer) adhere to an agreed-upon interface shape, without running a live integration. It catches breaking changes early and runs fast. Integration testing verifies that your system works with a real or simulated version of a dependency right now. Use contract testing to protect consumers of your API from breaking changes. Use integration testing to catch regressions in how your system handles external dependencies.
Prioritize three categories: authentication and authorization (token flows, permission boundaries, rate limiting), payment and billing flows (including edge cases like failed charges and webhooks), and core business logic endpoints that enterprise clients will integrate with. These are the areas enterprise technical due diligence focuses on and the areas where failures have the highest business impact.
The best API testing tools for startups include Autonoma for AI-generated and self-maintaining API tests, Pact for contract testing, and Supertest or pytest-httpx for integration tests depending on your stack. k6 handles performance and load testing with developer-friendly JavaScript scripts. For monitoring, Datadog and Grafana provide the endpoint-level observability enterprise clients expect. The best choice depends on your stack and whether you have engineering capacity to maintain test code.
Use a two-axis framework: business impact of failure vs likelihood of change. Endpoints that are high-impact and frequently changing need continuous automated coverage. Endpoints that are low-impact and stable can be covered lightly or skipped in the first pass. In practice, 15-20% of your endpoints will fall in the high-priority quadrant. Start there and work outward. Also prioritize the consumer-facing API surface over internal service-to-service calls, because that's what enterprise clients care about.
Yes. SOC 2 auditors look at your change management processes, which includes evidence that code changes (including API changes) go through automated testing before deployment. Payment endpoint testing and access control testing are specifically relevant to SOC 2 security and availability criteria. Having API tests in CI is not sufficient on its own for SOC 2, but it is a meaningful part of the evidence package your auditor will review.



