
Self-healing test automation is an AI-driven approach where tests automatically adapt when the application changes, without human intervention. Instead of failing when a selector changes or a flow is reordered, the system detects the change, understands the intent of the test, and updates itself. The critical distinction: self-healing knows the difference between a broken test (selector changed during a refactor) and a broken app (the button actually doesn't work). It fixes the former, reports the latter. Teams using self-healing test automation report eliminating 80-90% of their flaky test backlog without a single debugging session.
Every engineering team that has lived through a flaky test crisis describes the same arc. First frustration, then workarounds, then a quiet erosion of trust where nobody actually believes the CI signal anymore. The debugging hours show up on a calendar. The velocity drag and the merge-over-flakes habit are harder to quantify, and more expensive.
The standard response is to fight test flakiness test by test. Improve selectors. Add retries. Quarantine the worst offenders. These tactics work, until the codebase moves faster than your team can maintain the fixes. Self-healing test automation is the structural answer: tests that adapt when the application changes, without requiring a human in the loop.
This article breaks down how self-healing tests work, where they apply, and where they don't.
The Flaky Test Tax Is Bigger Than You Think
Flaky tests are not a minor inconvenience sitting at the bottom of your backlog. They're a compounding tax on every engineering workflow that depends on CI. Test flakiness is pervasive even at the most disciplined engineering organizations: Google's own research found that approximately 16% of their tests exhibit some level of flakiness, and industry surveys consistently report that test maintenance consumes 30-40% of QA team capacity.
The most visible cost is CI time. A team with 400 tests and a 5% flake rate sees roughly 20 false failures per run. Each failure triggers a rerun. If a full run takes 20 minutes, that's 6-7 hours of CI capacity consumed daily by false positives, before a single real failure is investigated. At AI development velocity, where teams push 30-40 PRs a day, this math gets catastrophic fast.
The less visible cost is the trust collapse. It starts quietly. Developers see a failing test, glance at the name, and think "that one always flakes." They rerun. It passes. They merge. Nobody investigates whether the failure was real. This pattern takes roughly three weeks to become automatic, and once it does, your test suite has functionally stopped providing signal. A real regression can hide behind a known-flaky test for days before anyone notices.
The engineering cost is concrete: 5-10 hours per week across a mid-sized team spent on false failure triage. That's not a rough estimate. It's the number we hear consistently from engineering leads who track it. For deeper context on root causes and why they cluster the way they do, see our full breakdown of why tests flake.
Why Traditional Fixes Don't Scale
The standard playbook for how to fix flaky tests involves three tactics: retries, quarantine, and manual debugging. Each one has a legitimate use case and a predictable failure mode.
Retries reduce visible flake rate without fixing anything. A test that passes on the third attempt still has a race condition. Worse, retries mask real regressions: a genuine failure that flaps on retry gets classified as "just flaky" and merged over.
Quarantine is the right call for a test with a known root cause that hasn't been fixed yet. It restores CI trust immediately. But quarantine without a deadline becomes a graveyard. Once a test is quarantined, the urgency to fix it drops to zero. Months later, you have a suite of quarantined tests that haven't run in a sprint, and your actual coverage has silently shrunk.
Manual debugging is where teams spend most of their time, and it's the one that doesn't scale. Diagnosing a flaky test properly requires reproducing the failure (often difficult given intermittent timing), reading framework internals, understanding async state transitions, and updating both the test and any related fixtures. For a team shipping 40 PRs a day, this investigation cycle can't keep up. By the time you've fixed this sprint's flaky tests, next sprint's have already appeared. See traditional best practices for reducing test flakiness for the full tactical breakdown. This article starts where those leave off.
The Paradigm Shift: Tests That Adapt, Not Tests That Retry
Self-healing test automation is a fundamentally different framing. The conventional approach treats every test failure as a debugging task. Someone must investigate, diagnose, patch, and re-verify. The human is always in the loop.
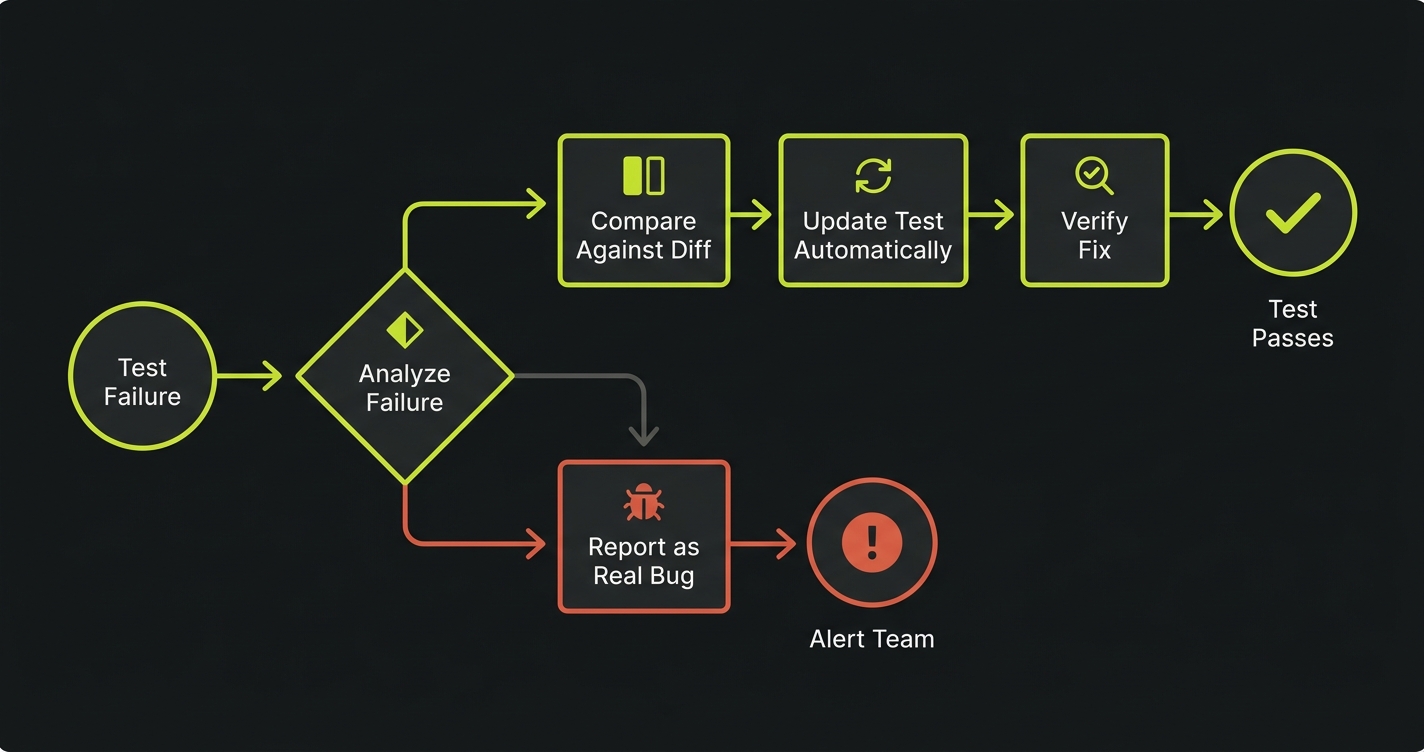
Self-healing flips that assumption. When a test fails, the system doesn't just rerun it. It asks: "Did the app change in a way that explains this failure? If so, adapt the test. If not, this is a real bug. Report it."
This distinction matters enormously. A retry strategy is probabilistic: run enough times and hopefully timing works out. A self-healing strategy is causal: understand what changed and respond appropriately. The difference is the same as the gap between agentic testing and traditional script-based automation. One understands intent. The other executes instructions.
The key property of self-healing test automation: it knows the difference between a broken test and a broken app. A broken test is caused by a change in the application's implementation that doesn't affect its behavior (a renamed CSS class, a reordered form, a new modal that wasn't there before). A broken app is caused by a change that does affect behavior (a button that no longer submits, an API that returns the wrong data). Self-healing fixes the former automatically. It reports the latter loudly.
How Self-Healing Test Automation Works Under the Hood
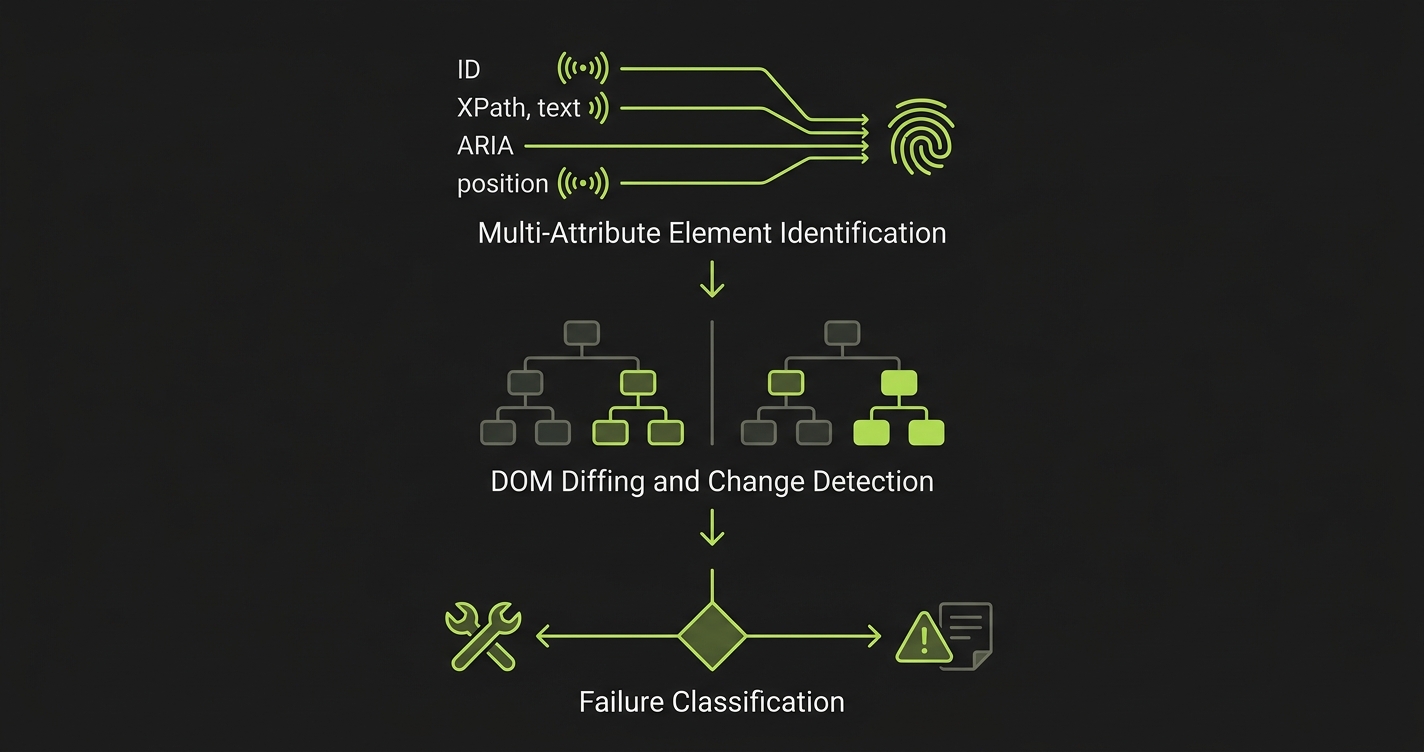
The mechanism behind self-healing tests has three layers.
Multi-attribute element identification. Instead of relying on a single CSS selector, the system builds a fingerprint for each element using multiple signals: element ID, XPath, text content, ARIA labels, visual position, and surrounding DOM context. When one attribute changes during a refactor, the remaining attributes still identify the correct element.
DOM diffing and change detection. When a test fails, the system compares the current page state against the last successful run. This diff reveals what changed: a renamed class, a reordered layout, a new overlay, or a missing element. The nature of the change determines the response.
Failure classification. This is the critical layer. The system evaluates whether the change is implementation drift (the UI changed but behavior is intact) or a behavioral regression (something is actually broken). Drift gets healed. Regression gets reported.
What Self-Healing Can Fix
Research on automated test repair shows that test failures distribute across a predictable spectrum:
- Timing failures (~30%): Async operations, network latency, rendering delays
- Selector drift (~28%): CSS class renames, ID changes, XPath breaks
- Test data issues (~14%): Expired tokens, missing seed data, shared-state pollution
- Visual assertion failures (~10%): Dynamic layouts, responsive breakpoints
- Interaction changes (~10%): Relocated buttons, redesigned flows, reordered steps
- Runtime errors (~8%): Third-party script crashes, analytics failures during test execution

Different self-healing test automation tools address different subsets of this spectrum. Some handle only selector drift. Others, like Autonoma, take a codebase-aware approach that covers the full range by reading your source code to understand what changed and why. The four scenarios below show how that plays out in practice.
Self-Healing Test Automation in Practice: How Autonoma Works
We built Autonoma around a core insight: tests break for known reasons, and an agent that understands your codebase can classify and respond to those reasons without a human in the loop. Here's how that plays out across the four failure types we see most frequently.
Scenario 1: Selector Change After a CSS Refactor
Your frontend engineer refactors the checkout component. The btn-checkout-primary class becomes checkout-cta. Your existing Playwright test fails immediately:
Error: Locator .btn-checkout-primary not found
In a traditional setup, this failure lands in your CI dashboard as a red build. Someone files a ticket. The ticket sits until an engineer picks it up, traces the failure to the CSS rename, updates the selector, and commits the fix. That cycle takes anywhere from 2 hours to 2 sprints depending on priority queue depth.
With Autonoma, the Maintainer agent sees the failure and cross-references it against the recent diff. It finds the rename in the component file, identifies every test that references the old class, and updates the selectors. The fix happens before the next CI run. No ticket. No human triage. The test was never broken from the user's perspective because the checkout behavior didn't change.
Scenario 2: Checkout Flow Reorder
Product ships a redesigned checkout experience. Billing information now comes before shipping, reversing the step order that all your flow tests assumed. Half a dozen tests fail because they look for the shipping form first.
The traditional response is a debugging session: run the tests in headed mode, watch what happens, manually update step order across each affected test, re-verify. An experienced engineer might finish this in a few hours. A junior engineer might spend a day on it.
Autonoma's Planner agent reads the updated component tree and identifies that the step sequence changed. It understands the intent of the checkout flow tests (verify that a user can complete a purchase) independently from the implementation (which form appears in which order). It resequences the affected tests to match the new flow, then runs verification to confirm the tests pass against the updated UI before committing the change.
The intent stayed the same. The implementation changed. The tests adapt to reflect the new implementation, not the old one.
Scenario 3: New Modal Interrupts a Flow
Marketing ships a cookie consent banner. Legal adds an upgrade prompt that appears mid-flow for users on the free tier. Both of these affect tests that were written before those modals existed. The tests now fail because they try to interact with elements that are obscured by an unexpected overlay.
This is one of the most common "mystery failures" teams deal with. The test is correct. The app changed. The failure is real but not a bug.
Autonoma detects the modal by recognizing the pattern: an overlay element with a dismiss action that appears in front of the test's target element. It classifies the modal as an environmental interruption rather than a structural test failure, dismisses it, and continues the test flow. If the modal cannot be dismissed (for example, a blocking upgrade prompt that requires action), it reports that the test preconditions need to be updated, specifically that the test account may need a different subscription tier.
Scenario 4: A Real Bug (What Self-Healing Does Not Fix)
This is the most important scenario. The "Place Order" button exists. The selector is correct. The test clicks it. Nothing happens. The order is never created. The test fails.
Autonoma does not self-heal this. The Maintainer agent checks the diff, finds no UI changes that would explain the failure, and escalates it as a genuine regression. The failure report includes the step where the flow broke, the expected vs. actual application state, and the diff context that's most likely related.
This is the property that makes self-healing trustworthy. A system that heals everything, including real bugs, is worse than useless. It's deceptive. The value of self-healing comes entirely from its ability to distinguish implementation drift (heal it) from behavioral regression (report it). Without that distinction, you'd be automating the "just rerun it" habit rather than eliminating it.
Measuring Self-Healing Test Automation Impact
Teams adopting self-healing test automation consistently see changes in three metrics. Two are immediately measurable. One takes a month to fully materialize.
Flaky test rate. Automated flaky test detection and healing drops this metric sharply within the first few CI cycles. The selector changes, flow reorders, and new modal interruptions that previously generated false failures are now handled before they hit the CI dashboard. Teams typically see 80-90% reduction in false failure rate within the first two weeks. For a direct comparison of testing costs and ROI, see our analysis on manual vs. automated testing in the AI era.
Test maintenance hours. The engineering time previously spent on debugging and patching flaky tests drops toward zero for the categories self-healing handles. The hours shift to feature work. If your team was spending 6 hours per week on test maintenance, expect that number to drop to under 1 hour for the automated cases. See also how automated regression testing fits into the overall picture of reduced maintenance burden.
CI trust recovery. This is the metric that takes the longest but matters most. After enough consecutive runs where every failure is a real failure, developers stop reflexively re-running. They start investigating. The test suite becomes a reliable signal again. This cultural shift takes 3-4 weeks of clean CI runs to solidify, but once it does, it's durable.
| Metric | Traditional Approach | With Self-Healing |
|---|---|---|
| False failure rate | 5-15% per run | Under 1% |
| Weekly maintenance hours | 5-10 hrs/team | Under 1 hr/team |
| Time to fix a broken selector | 2 hrs to 2 sprints | Before next CI run |
| CI time lost to reruns | 15-30% of capacity | Under 3% |
| Developer trust in CI | Eroded (rerun reflex) | Restored (investigate reflex) |
When Self-Healing Isn't the Answer
Self-healing test automation is the right solution for a specific class of problems: tests that break because the application's implementation changed but its behavior didn't. It is not the right solution for everything.
True application bugs. If the button doesn't work, self-healing reports it. It doesn't paper over it. This is intentional and correct.
Performance regressions. If your API response time doubled, that's a behavioral change that no amount of selector healing will address. Performance testing requires dedicated infrastructure and monitoring, not self-healing E2E tests.
Data-dependent failures. If a test fails because the expected seed data wasn't seeded, or because the database is in an unexpected state, self-healing won't resolve the underlying data management problem. It can detect that the test preconditions aren't met and report it clearly, but the data pipeline itself needs attention.
Logic errors in the tests themselves. If a test was written with a wrong assertion from day one (asserting the wrong value, checking the wrong element), self-healing will faithfully maintain that wrong assertion. Garbage in, garbage out. Test correctness is still a human responsibility.
The mental model: self-healing closes the gap between the application's current implementation and the tests that describe it. That gap is the source of most flaky tests. The gaps self-healing can't close are the ones involving behavioral correctness, which is where human judgment belongs.
Frequently Asked Questions
Self-healing test automation is an AI-driven approach where tests automatically adapt when the application changes, without requiring manual debugging or human intervention. When a selector changes, a flow is reordered, or a new modal appears, the system detects the change, classifies it as an implementation drift rather than a real bug, and updates the test accordingly. The critical property: it distinguishes between a broken test (implementation change with no behavioral impact) and a broken app (behavioral regression). It heals the former and reports the latter.
Retries are probabilistic: run the test again and hope the timing works out. Self-healing is causal: understand why the test failed and respond appropriately. A retry strategy doesn't fix the underlying race condition or broken selector. It just reduces the visible failure rate while the root cause persists. Self-healing addresses the root cause by detecting what changed in the application and updating the test to reflect the new implementation. Retries mask problems. Self-healing resolves them.
No, and this is the most important property of a well-built self-healing system. Self-healing should only adapt tests when the application's implementation changed but its behavior didn't (a renamed CSS class, a reordered form, a new modal). When the behavior itself changes (a button that no longer works, an API that returns wrong data), the system reports it as a genuine failure. Autonoma's Maintainer agent cross-references failures against code diffs to make this classification. If no implementation change explains the failure, it's escalated as a real bug.
Self-healing handles four main categories: selector changes (a CSS class or element ID is renamed during a refactor), flow reorders (steps in a multi-step form are rearranged), environmental interruptions (a new modal, banner, or overlay appears mid-flow), and minor UI restructuring (an element moves within the DOM hierarchy without changing its purpose). It does not handle true application bugs, performance regressions, data pipeline failures, or logic errors in the tests themselves.
Autonoma has three specialized agents. The Planner agent reads your codebase to understand routes, components, and user flows, then generates test cases. The Automator agent executes those tests against your running application. The Maintainer agent is responsible for self-healing: it monitors test failures, cross-references them against recent code diffs, classifies failures as implementation drift or genuine regression, and updates tests autonomously for the former. Each agent has verification layers at every step to ensure consistent behavior, so the system doesn't take random healing paths.
The reduction in false failure rate is visible within the first few CI cycles, typically within 24-48 hours of setup. Selector changes and flow reorders that previously triggered debugging sessions are resolved before the next run. The larger cultural shift, developers rebuilding trust in CI and stopping the rerun reflex, takes 3-4 weeks of clean runs to solidify. Maintenance hours drop immediately for the categories self-healing handles.
Self-healing is most impactful for E2E and integration tests because they're the tests most affected by UI changes, flow reorders, and selector drift. Unit tests tend to be more stable because they're isolated from the UI layer. That said, the underlying principle (adapting tests to implementation changes without human intervention) applies across test levels. Autonoma focuses on E2E tests because that's where maintenance burden is highest and the ROI of self-healing is clearest.
Self-healing test automation tools fall into three categories: selector-only healers that patch locators when they break (like Healenium), multi-signal healers that use DOM analysis plus visual recognition to identify elements (like Testim and mabl), and codebase-aware healers that read your source code to understand what changed and why (like Autonoma). The key evaluation criteria: Does the tool heal only selectors or the full failure spectrum? Can it distinguish broken tests from broken apps? Does it integrate with your CI pipeline? Can you audit what it healed and why? Autonoma takes the codebase-aware approach, which means it understands the intent behind your tests rather than just re-identifying elements.
Automated flaky test detection works by analyzing test results across multiple runs to identify patterns of inconsistent behavior. The simplest approach is tracking pass/fail rates per test over time: any test below a 95% pass rate is likely flaky. More advanced systems like Autonoma classify failures in real time by cross-referencing test results against recent code changes. If a test fails and the failure correlates with an implementation change (not a behavioral one), the system identifies it as a flaky failure caused by test drift rather than a real bug, and heals it automatically.



