
Agentic testing is a software testing approach where AI agents autonomously plan, execute, and adapt tests based on goals rather than fixed scripts. Instead of writing step-by-step test code, you connect your codebase and AI agents plan, execute, and maintain your tests autonomously, including self-healing when your code changes.
Key Takeaways: Agentic testing uses AI agents that understand intent, not just scripts. Tests self-heal when your UI changes, with no maintenance required. Agents read your code and generate tests automatically -- no recording, no scripting, no maintenance. It is best suited for startups shipping fast without a dedicated QA function.
Your Test Suite Is a Second Job You Didn't Sign Up For
It's 11pm on a Thursday. Your designer pushed a UI refresh three days ago -- rounded corners, a new button style, a refactored checkout form. You're now staring at a wall of red in CI. Fourteen tests failing. Not because the feature is broken. Because a CSS class changed from btn-primary to button-cta and Playwright has no idea what to do with that.
You spend two hours fixing selectors. You push. Green. You go to bed.
Next week, the designer updates the form labels. Seven more tests fail. Someone on the team quietly stops running the suite before deploying because it's faster to just check manually. The test suite that was supposed to give you confidence is now a source of dread.
No one tells you this when you set up your first Playwright suite: you didn't just write tests. You created maintenance debt that compounds every time your product improves. For a three-person team shipping fast, that debt becomes the most expensive thing in your stack.
This is the exact problem agentic testing was built to solve.
What "Agentic" Actually Means
The word gets thrown around, so let's be precise.
An agent is an AI system that perceives its environment, makes decisions, takes actions, and observes the outcome. It operates in a loop: plan, act, observe, adapt. It doesn't need a human to specify every step. It receives a goal and figures out how to reach it.
This is meaningfully different from a script, which executes a fixed sequence of steps, or a language model, which responds to prompts. An agent pursues.
When you apply this to software testing, the shift is concrete. A traditional Playwright test says: "Click the element with id #checkout-btn, then assert the URL is /confirmation." An agentic test says: "Verify that a user can successfully complete a purchase." The agent decides what to click, observes whether checkout worked, and handles whatever the application throws at it.
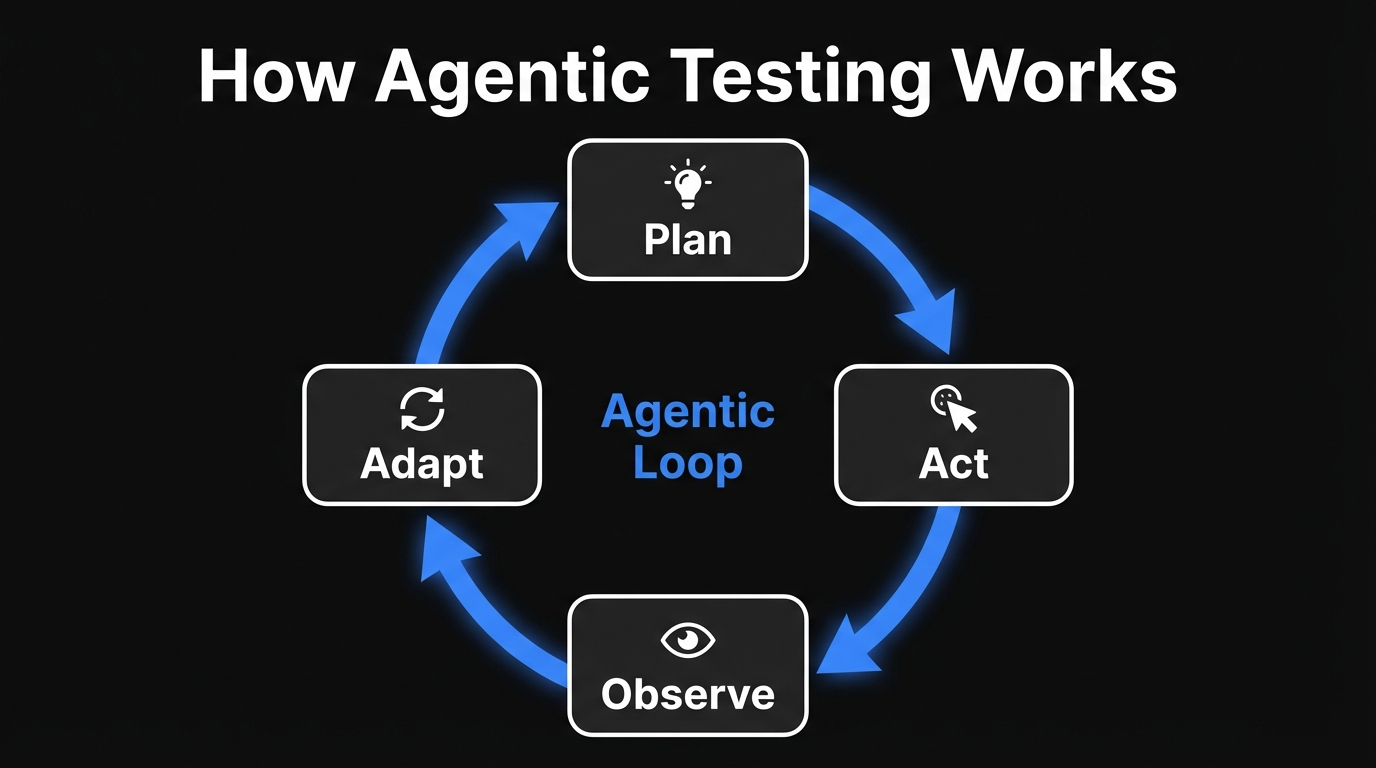
That shift from steps to intent is everything. It's what makes self-healing possible. It's what makes zero-maintenance testing possible. It's the entire premise of what we've built at Autonoma.
Three Generations of Testing (and Why Two of Them Failed Startups)
Manual testing was the original. A human clicks through the app and tries to break things. Flexible, catches visual issues. Impossible to scale when you're shipping daily and there's no dedicated tester on the team.
Scripted automation was supposed to be the answer. Playwright, Cypress, Selenium, and their counterparts. Write the test once, run it forever. Except the "forever" part was always a lie. A script is frozen at the moment you wrote it. When your app changes, the script doesn't know. It just fails. And someone has to fix it.
For a large QA team, that maintenance burden is manageable. For a five-person startup, it's fatal. You don't have a QA engineer to babysit the suite. Every hour spent fixing selectors is an hour not spent on the product. We've talked to founders who spent a full sprint week firefighting a broken test suite after a UI redesign. That's a feature they didn't ship.
Agentic testing is the third generation. The difference isn't speed or coverage (scripted automation handled both). The difference is adaptability. An agentic system understands intent. When your UI changes, it doesn't fail blindly. It reasons about what it was trying to accomplish and finds a new path.

For startups shipping fast and iterating constantly, this isn't a nice-to-have. It's the only model that actually works.
How Agentic Testing Works in Practice
Autonoma uses three specialized agents working in sequence. When you connect your codebase, here's what happens:
The Planner agent reads your codebase -- routes, components, user flows -- and generates test cases automatically. It understands what your application does from the code itself. No one needs to describe tests or click through anything.
The Automator agent takes each test case and executes it against your running application. It combines a vision model (to see the screen), a reasoning model (to decide what to do), and a memory layer (to track context). It navigates your app the way a real user would, adapting to whatever the application throws at it.
The Maintainer agent watches for code changes and keeps tests passing. When your UI evolves, it re-evaluates and heals tests automatically.
This is why self-healing works -- and why it's different from "AI-assisted selector fixing." If a button's CSS class changed from btn-primary to button-cta, a Playwright test fails. Our agent looks at the page, sees a button in the expected position with the expected label, and clicks it. The underlying implementation is invisible to the agent's goal.
Our agents understand intent, not technical selectors. When the Automator encounters an "Add to Cart" button, it understands the action's purpose. When you rename that button to "Add to Bag" next sprint, the test still passes. The Maintainer sees the code change and the agent adapts. No one has to fix anything.

What Makes It Different from "AI-Assisted" Testing
There's a spectrum here, and the distinctions matter if you're evaluating tools.
At one end: AI-assisted testing, where AI helps you write Playwright or Selenium scripts. Copilot, Cursor, Claude Code. You still own the script. When it breaks, you fix it. The AI was a coding assistant, not a testing system. We know this approach well -- we've benchmarked it directly. Claude Code needed three attempts to generate a working test. Cursor needed six. And the tests they produced were brittle: hard-coded timeouts, text-based selectors that break the moment someone renames a button. If you want a deeper look at how AI fits into the broader testing picture, our complete guide to AI for QA covers the full spectrum.
In the middle: AI-enhanced testing, where an AI layer sits on top of a traditional framework and handles element location. Self-healing selectors in tools like Testim or mabl. The structure is still scripted; the AI handles the brittle parts. It's a meaningful improvement, but you still need a human to define every step of every test. A PM can't write a test case. A designer can't add coverage. It's still an engineer's job.
At the far end: agentic testing, where the system receives a goal and owns the entire lifecycle. It creates the test, executes it, interprets results, and adapts when things change. You define what to verify, not how to verify it.
Most tools marketed as "agentic" today sit somewhere in the middle. At Autonoma, you connect your codebase and our agents handle everything downstream -- planning tests from your code, running them, healing when your UI changes, and surfacing real failures with clear explanations.

The Startup Case for Agentic Testing
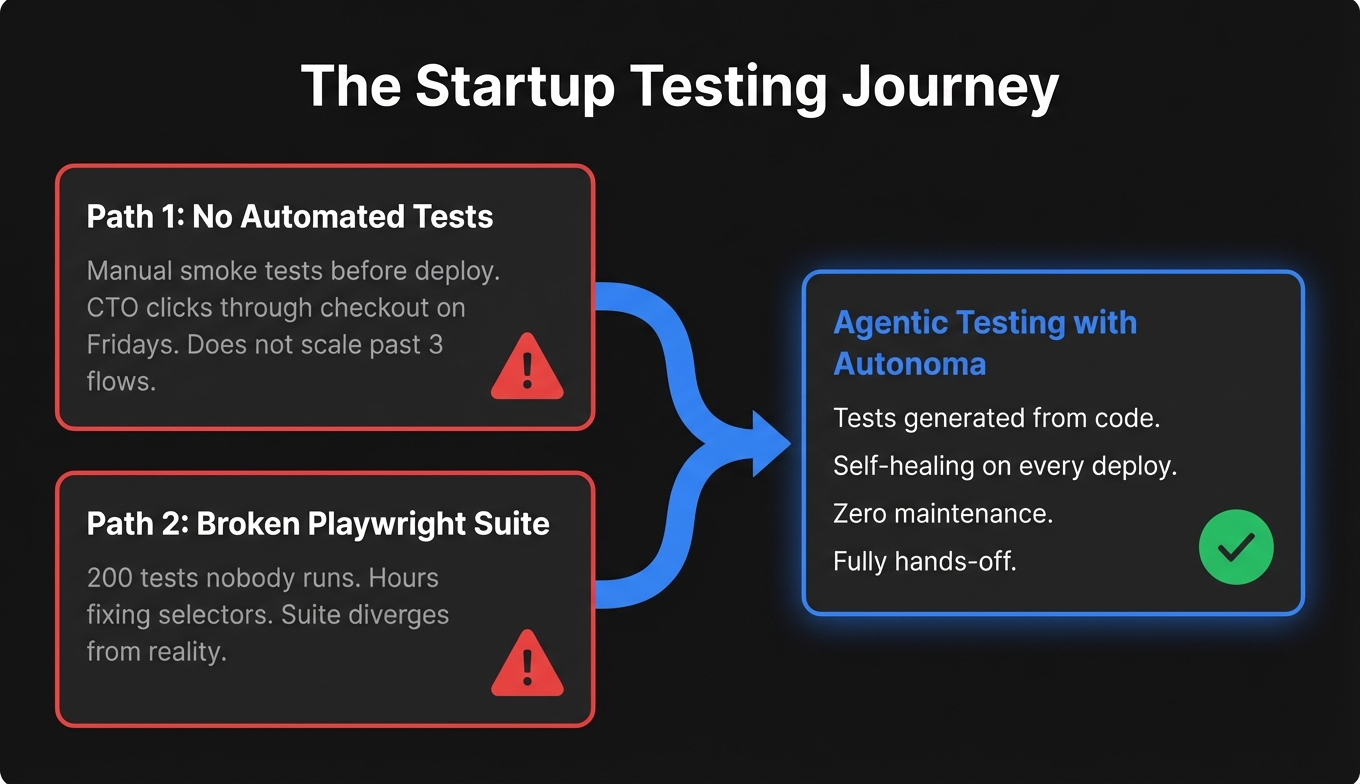
The typical Autonoma customer when they come to us looks something like this: Series A or earlier, engineering team of two to eight people, no dedicated QA, shipping multiple times per week. They've tried one of two paths.
The first path: manual smoke tests before deploys. It works until the team grows and "just click through it" takes forty minutes and still misses edge cases.
The second path: a Playwright suite that worked great for the first three months, then quietly became a burden. Developers start skipping the tests or hardcoding workarounds. One team told us their suite was 200 tests that nobody ran anymore because fixing failures felt like a project unto itself.
Both paths arrive at the same place: testing doesn't scale with shipping velocity. (Larger teams face a different version of this problem -- if you're curious how enterprises deal with it at scale, see how autonomous testing is reshaping QA at the enterprise level.)
The reason agentic testing solves this specifically for startups isn't just the self-healing. It's the zero setup. Connect your codebase and agents generate tests from your code automatically. No one on the team needs to create tests manually -- not the CTO, not the PM, not anyone. The agents derive test cases from what you've already built.
The onboarding pattern is consistent: first tests are generated within minutes of connecting a codebase, critical flows covered within a week, test maintenance forgotten within a month. One founder told us the moment they knew it was working: their designer pushed a full component library update, CI ran, everything passed, and nobody panicked.
What Agentic Testing Won't Do (Being Honest About the Limits)
Our agents include verification layers at each step to ensure they stay on track and produce consistent results. If a test fails, the failure report tells you exactly what the agent verified, what it tried, and where it got stuck.
Complex flows that require API coordination or database state setup are handled by the Planner agent. It designs test scenarios and generates the endpoints needed to set your database in the right state for each test. No manual configuration required.
And there's a small category of tests where absolute precision matters -- pixel-perfect layout checks, strict ordering, exact string matching -- where a deterministic test gives you more control.
Our recommendation: use Autonoma for user flows, feature verification, and regression coverage. Use deterministic tests for narrow cases requiring exact behavioral contracts. Most of our customers run Autonoma for E2E flows and keep a small set of unit tests for critical business logic.

Getting Started with Autonoma
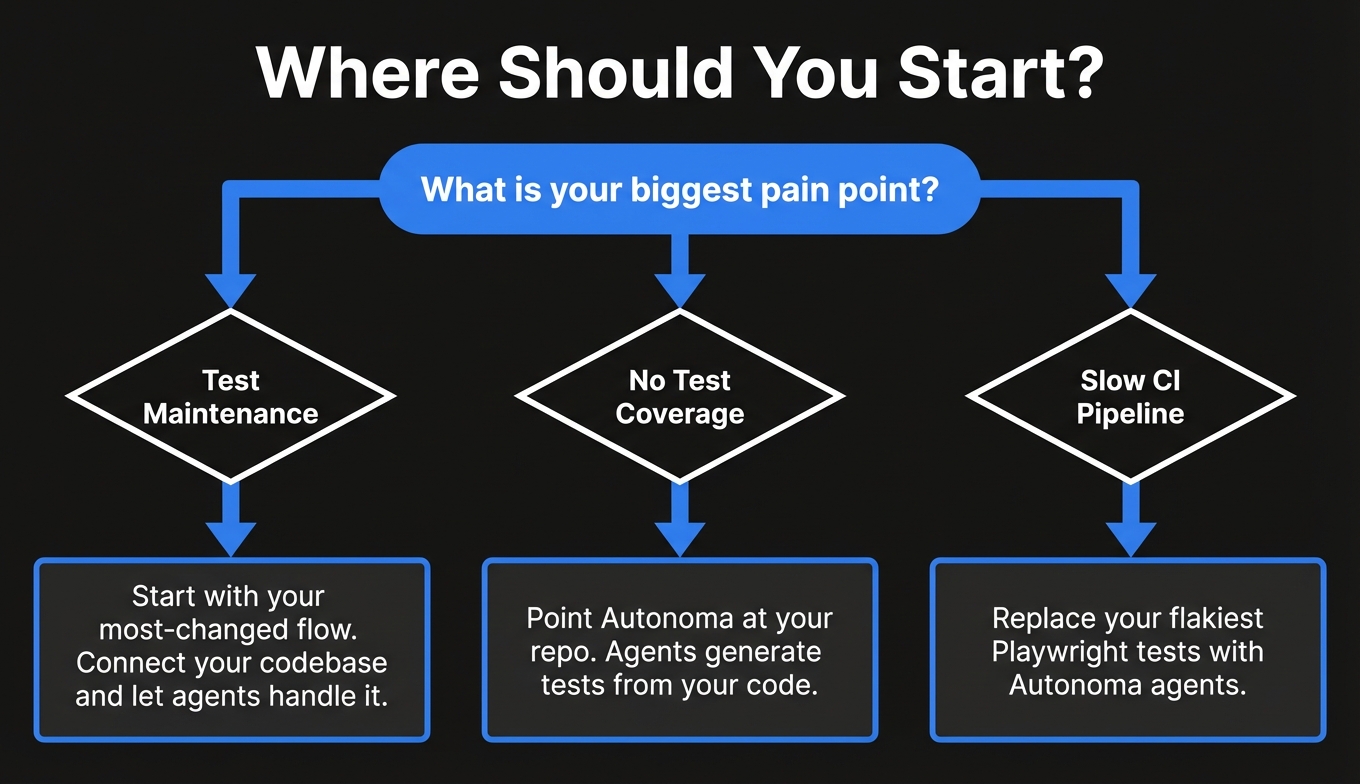
If your checkout flow or core feature path is currently tested by someone clicking through the app before every deploy, you're the customer we built this for.
The fastest way to start is to connect your codebase. Point Autonoma at your repo and our agents take it from there: planning tests from your code, running them, self-healing when things change, and sending you clear failure reports when something actually breaks.
No script to write. No selectors to maintain. No Playwright configuration. (If you're still evaluating scripted frameworks, our Playwright alternatives comparison covers what's out there.)
Book a demo to see it on your specific application, or check our documentation to understand how our agents work under the hood.
Frequently Asked Questions
Agentic testing uses AI agents that plan, execute, and adapt tests toward a goal without requiring a human to specify every step. Rather than following a fixed script, an agentic system observes the application, reasons about what to do next, takes an action, and adjusts based on the result. This loop (plan, act, observe, adapt) is what makes it 'agentic', and it's what makes self-healing possible.
Playwright and Cypress are scripted automation frameworks. They execute a fixed sequence of steps that a human wrote. When the application changes, the script breaks and a human must fix it. Agentic testing understands intent: it knows what it's trying to verify, not just the exact steps. When the UI changes, the agent finds a new path rather than failing. The practical result is dramatically less maintenance, which matters enormously for small teams.
No, and that's largely the point. Because Autonoma generates tests directly from your codebase, there's no manual test creation step at all. No one needs to write scripts, record flows, or define test cases. You connect your code and agents handle the rest. You don't need a dedicated QA function to maintain strong test coverage.
Our agents understand intent, not technical selectors. When the agent encounters an 'Add to Cart' button, it understands the purpose of that action -- adding an item to the cart. When you rename that button 'Add to Bag' next sprint, the agent looks at the page, recognizes the button that performs that action, and clicks it. The implementation detail changed; the intent didn't. Self-healing is a consequence of goal-directed reasoning, not a feature bolted on afterward.
Yes. Our agents include verification layers at each step to ensure consistent, reliable results. For the vast majority of testing (user flows, feature verification, regression coverage), agentic testing works out of the box. For narrow cases requiring absolute precision (exact string matching, pixel-perfect layout checks), deterministic tests give more control. We recommend using both: Autonoma for user flows and regression coverage, deterministic tests for strict behavioral contracts.
Your first tests are generated within minutes of connecting your codebase. Point Autonoma at your repo and agents plan and run tests automatically. There's no Playwright configuration, no selector writing, no framework to learn. Most teams have their critical flows covered within a week of onboarding.
AI-assisted testing means AI helps you write scripts (tools like Copilot or Cursor generating Playwright code). You still own the script, and when it breaks, you fix it. Agentic testing means the AI owns the entire test lifecycle: creating the test, executing it, healing when things change, and interpreting results. The human defines what to verify; the agent handles everything else.



