
Flaky tests in 30 seconds. Flaky tests fail intermittently without code changes, usually caused by race conditions, hardcoded waits, shared state between tests, or DOM rendering delays. The manual fix is whack-a-mole: hunt down each flaky test, diagnose the root cause, patch it, and repeat when the next one surfaces. The structural fix is to remove humans from the loop entirely. Agentic testing platforms like Autonoma read your codebase, understand application state, and autonomously handle the timing and isolation problems that cause flakiness in the first place.
When developers start clicking "re-run" as a reflex instead of investigating failures, you've already lost the signal that automated testing is supposed to provide. That 5% failure rate is enough to make your entire CI pipeline worthless — and the root causes are both predictable and fixable.
What Are Flaky Tests?
A flaky test is an automated test that produces inconsistent results, sometimes passing and sometimes failing, without any change to the code under test. The same test, the same commit, the same branch, different outcome. According to research from Microsoft, roughly 25% of test failures in large-scale CI systems are caused by flaky tests rather than actual code defects. Slack's engineering team reported that flaky tests accounted for 56.76% of their CI failures before they invested in a dedicated remediation effort, which brought that number down to 3.85%.
Flaky tests are not random failures. Every flaky test has a deterministic root cause. The failure appears intermittent because the triggering condition (a timing window, a resource contention, an ordering dependency) does not occur on every execution. Understanding those root causes is the first step toward eliminating them.
Flaky failures generally fall into three categories: random flakiness caused by race conditions, shared mutable state, or non-deterministic data; environmental flakiness triggered by differences in CI runners, resource limits, network latency, or timezone settings; and order-dependent flakiness where tests pass in isolation but fail when run after other tests that leave behind dirty state.
The Frustration Is Real, and It Is Expensive
If you are reading this, your team probably has a CI pipeline that nobody trusts. Builds go red. Somebody re-runs the pipeline. It goes green. The PR gets merged. Nobody investigates why the test failed the first time because everybody knows the answer: it was flaky.
This is not a minor inconvenience. According to a Google engineering study, approximately 16% of their tests exhibited flaky behavior, and flaky tests accounted for 1.5% of all test executions failing incorrectly. At Google's scale, that translates to millions of wasted compute hours. At your scale, it translates to something more damaging: your developers no longer believe the tests.
The cost shows up in three places:
Wasted CI minutes. Every re-run burns compute. A team running 500 tests with a 5% flake rate will see roughly 25 false failures per run. If each failure triggers a re-run, and runs take 15 minutes, that is hours of CI time wasted per day across the team.
Wasted developer time. Engineers stop investigating test failures. They develop the "re-run and hope" habit. When a real regression hides behind a flaky test, nobody catches it until it reaches production.
Eroded confidence. This is the most expensive cost, and the hardest to measure. Microsoft's empirical analysis of flaky tests found that developers who encounter flaky tests are significantly less likely to investigate subsequent test failures. Once a team stops trusting their test suite, they stop writing tests. They stop requiring green builds before merging. The entire investment in automation becomes sunk cost.
Our State of QA 2025 report found that test maintenance, including fighting flakiness, consumes roughly 40% of QA team time. That is not time spent finding bugs. That is time spent fighting the testing infrastructure itself. For teams building a quality engineering practice, flaky test remediation is the single highest-impact place to start.
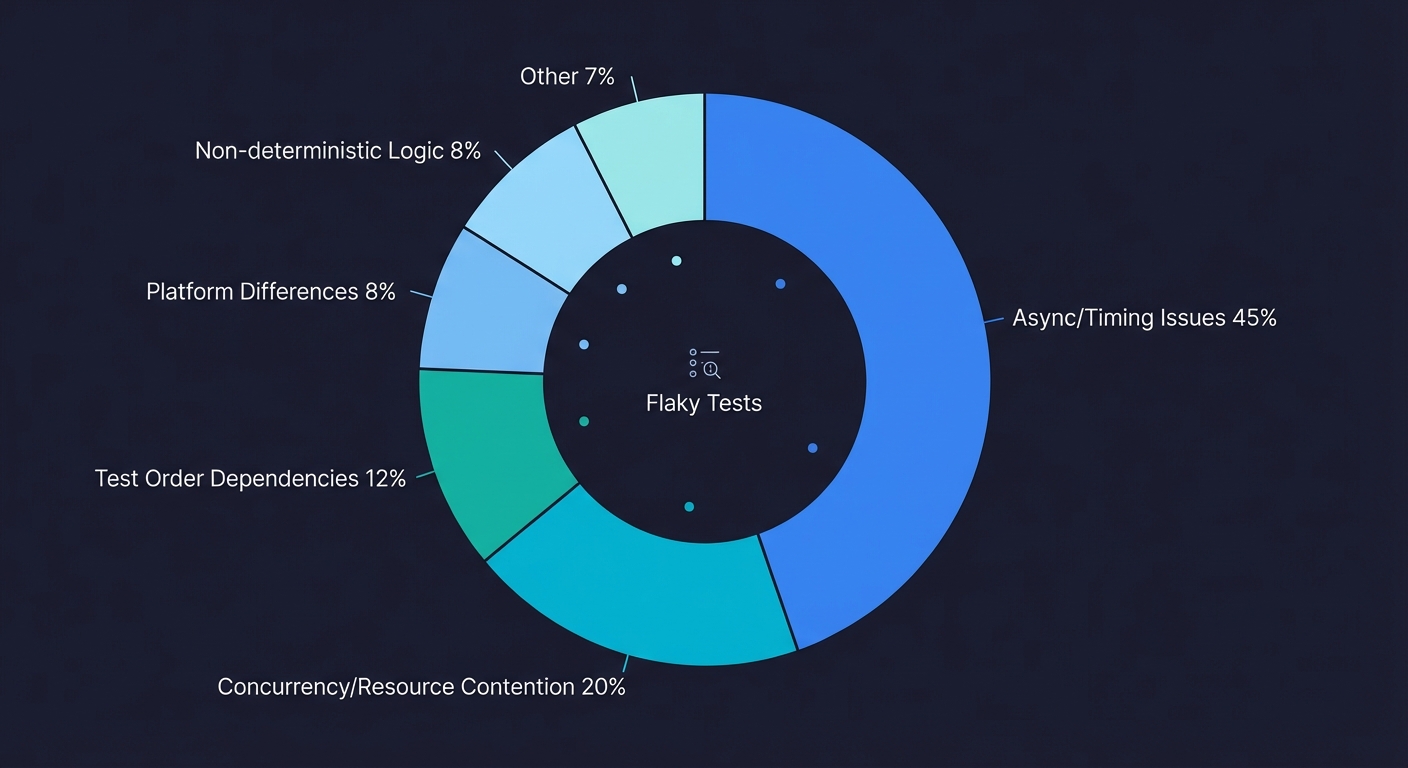
The Five Root Causes of Flaky Tests
Flaky tests are not random. They feel random because the failures are intermittent, but every flaky test has a deterministic root cause. The test is racing against something, depending on something it should not depend on, or assuming something that is not always true. Research on large-scale test suites consistently shows the same distribution: async wait and timing issues account for roughly 45% of flaky tests, concurrency and resource contention cause about 20%, test order dependencies contribute 12%, and the remaining cases split between platform/environment differences and non-deterministic logic. Here are the five structural causes, ordered by how frequently we see them in production test suites.
Race Conditions and Timing Issues
This is the most common cause of flaky tests by a wide margin. The test performs an action and immediately asserts on the result before the application has finished processing.
Here is a concrete example. Your test clicks a "Submit" button that triggers an API call. The API returns a success response, and the UI renders a "Success" banner. The test asserts that the banner is visible. On a fast machine, the API responds in 50ms and the banner renders before the assertion runs. On a slower CI worker, the API takes 300ms, and the assertion fires before the banner exists in the DOM.
// This test will flake
await page.click('#submit-button');
expect(await page.isVisible('.success-banner')).toBe(true);The test is not wrong. The logic is correct. The timing assumption is wrong. The test assumes synchronous execution in a fundamentally asynchronous environment.
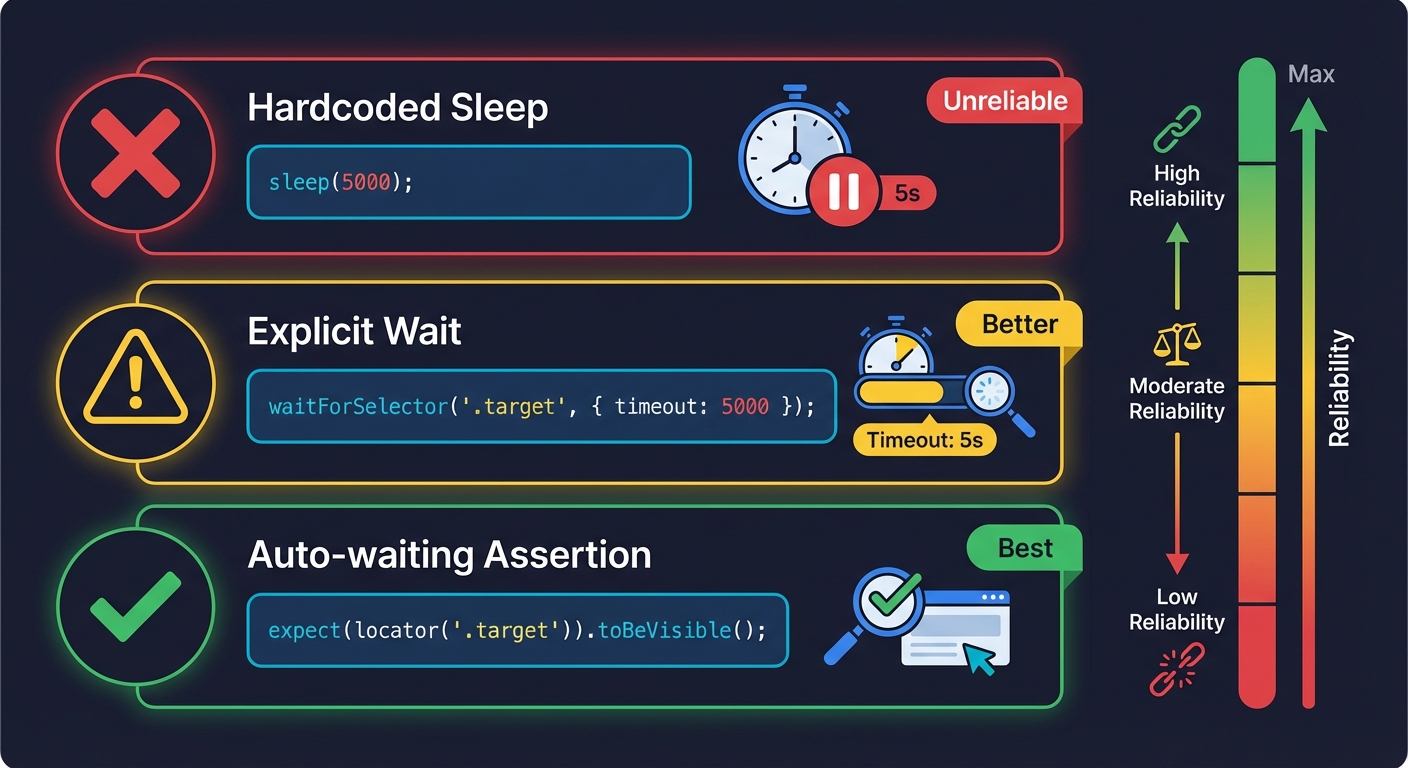
The manual fix is to add explicit waits:
// Better, but still fragile
await page.click('#submit-button');
await page.waitForSelector('.success-banner', { timeout: 5000 });
expect(await page.isVisible('.success-banner')).toBe(true);This fixes the immediate problem but introduces a new one: the hardcoded 5-second timeout. Too short, and the test still flakes on slow CI. Too long, and your suite takes forever when something genuinely breaks. You are trading one form of fragility for another.
The structurally correct approach is to wait for the actual application state change, not a time interval:
// Structurally sound
await page.click('#submit-button');
await expect(page.locator('.success-banner')).toBeVisible();Playwright's auto-waiting and assertion retries handle this well (which is one reason Playwright wins reliability comparisons against Cypress). But this pattern needs to be applied consistently across every test in the suite. One developer writing page.isVisible() instead of expect().toBeVisible() reintroduces flakiness. Maintaining this discipline across a team of engineers is the real challenge.
Hardcoded Waits and Sleeps
Hardcoded waits are the most visible symptom of a team fighting flakiness without understanding the root cause. When a test flakes, the quickest patch is to throw a sleep() before the assertion:
// Cypress: the classic band-aid
cy.get('#submit-button').click();
cy.wait(3000); // "just to be safe"
cy.get('.success-banner').should('be.visible');# Selenium: same pattern, different language
driver.find_element(By.ID, "submit-button").click()
time.sleep(3)
assert driver.find_element(By.CLASS_NAME, "success-banner").is_displayed()This "works" in the sense that it reduces flake rate. But it does not eliminate it. If the CI worker is under heavy load, 3 seconds might not be enough. And even when 3 seconds is enough, you are burning 3 seconds of wall-clock time on every test that uses this pattern. Across a suite of 200 tests, those sleeps compound into minutes of wasted pipeline time.
The deeper problem is that sleep() obscures the actual dependency. The test does not need 3 seconds. It needs the API response to arrive and the DOM to re-render. Those are specific, observable events. Sleeping is a confession that you do not know when those events will complete, so you are guessing.
Shared State Between Tests
Shared state is the second most common cause of flaky tests, and it is the hardest to diagnose because the failure often appears in a test that is completely correct. The problem is in a different test that ran earlier and left behind corrupted state.
Consider this scenario: Test A creates a user account with the email test@example.com. Test B searches for users and asserts that the results page shows "No users found." When Test B runs after Test A, it fails because Test A's user is still in the database.
If your tests run sequentially, this might work because Test A's cleanup step deletes the user. But when you parallelize your tests (which you should, for CI speed), Test A and Test B run simultaneously on different workers. Test A creates the user while Test B is searching. The search returns the user. Test B fails.
The structural patterns that cause shared state flakiness:
Shared database. Multiple tests read from and write to the same database without isolation. One test's writes become another test's unexpected preconditions.
Shared browser state. Tests that rely on cookies, localStorage, or session data from previous tests. If test execution order changes (as it does with parallelization or random ordering), the state assumptions break.
Shared external services. Tests that interact with a real third-party API or a shared staging environment. One test's side effects become another test's flaky assertion.
Environment differences. A test that passes on a developer's macOS laptop but flakes on a Linux CI worker with 2 CPU cores and 4GB RAM. Different operating systems, CPU counts, available memory, network latency, and even filesystem case sensitivity can produce different test outcomes. This is a subtle form of shared state: the test implicitly depends on the execution environment being identical to where it was written.
The manual fix is test isolation: each test creates its own data, runs in its own browser context, and cleans up after itself. In Playwright, browser contexts make this straightforward:
test('search returns empty results', async ({ browser }) => {
const context = await browser.newContext();
const page = await context.newPage();
// This test has a clean browser with no cookies, no localStorage
await page.goto('/admin/users');
await expect(page.locator('.no-results')).toBeVisible();
await context.close();
});But database isolation is harder. You need per-test data seeding, transaction rollbacks, or dedicated test databases. Each approach has tradeoffs in complexity and execution speed. For a deeper look at managing test data, our guide on data seeding for E2E testing covers the practical patterns.
DOM Rendering Delays and Framework-Specific Timing
Modern frontend frameworks (React, Vue, Angular, Next.js) render asynchronously. A click event might trigger a state update that cascades through multiple component re-renders before the final UI state is visible. The gap between "the action was performed" and "the UI reflects the result" is where flaky tests live.
This is especially problematic with:
Client-side routing. Navigating between pages in a single-page application does not cause a full page load. The browser URL changes, React re-renders the new route, but the DOM might be in a transitional state for several render cycles.
Lazy-loaded components. A component that loads via React.lazy() or dynamic import() introduces a network request into the render cycle. The test might assert on an element that has not been fetched yet.
Animation and transition states. CSS transitions and JavaScript animations create intermediate DOM states. A button might be "visible" during a fade-in animation but not yet "clickable" because it has pointer-events: none during the transition.
// This test flakes because the modal animation hasn't finished
await page.click('#open-settings');
await page.click('#delete-account'); // The button exists but is mid-animation
// Structurally better: wait for the element to be actionable
await page.click('#open-settings');
await page.locator('#delete-account').click(); // Playwright waits for actionabilityFramework-specific rendering quirks make this worse. React 18's concurrent rendering can batch state updates unpredictably. Next.js App Router server components hydrate asynchronously. Vue's nextTick behavior differs between the Options API and Composition API. Each framework introduces its own timing characteristics that test authors need to understand. Our guides on testing with React, Next.js, and Django cover framework-specific strategies for each of these patterns.
Unstable Selectors
The fifth cause is less about timing and more about fragility. Tests that locate elements by CSS class names, XPath expressions, or DOM position break whenever the markup changes, even if the application behavior is identical.
// Fragile: breaks if any parent element is added/removed
cy.get('div > div:nth-child(2) > button.btn-primary').click();
// Fragile: breaks if the class name changes during a CSS refactor
cy.get('.MuiButton-containedPrimary').click();
// Stable: survives UI redesigns as long as the element's purpose is the same
cy.get('[data-testid="submit-order"]').click();This is not technically "flakiness" in the probabilistic sense. The test does not sometimes pass and sometimes fail on the same codebase. It breaks deterministically when someone changes the markup. But the symptom feels the same to the team: tests go red, nobody knows why, and the "re-run" reflex kicks in before anyone checks whether the failure is a real regression or a broken selector.
The manual fix is to use stable selectors: data-testid attributes, ARIA roles, or text content. Playwright's locator API pushes you in this direction with getByRole, getByText, and getByTestId. But this requires every developer on the team to add data-testid attributes to components consistently, which is another maintenance burden that grows with your codebase.
How to Detect and Track Flaky Tests
Before you can fix flaky tests, you need to find them. The most dangerous flaky tests are the ones your team has not yet identified, the tests that fail just often enough to trigger occasional re-runs but not often enough to draw investigation.
CI-level detection. Most modern CI systems (GitHub Actions, GitLab CI, CircleCI, Jenkins) can be configured to track test pass/fail rates across runs. A test that fails on 3 out of 100 runs on the same branch is flaky by definition. Tools like Trunk Flaky Tests, Datadog CI Visibility, and BuildPulse specialize in surfacing this data. If you use Playwright, the built-in --retries flag combined with the HTML reporter will highlight tests that needed retries to pass.
Repeat-run detection. The simplest detection method is to run your suite multiple times against the same commit. If any test produces different results across runs, it is flaky. Playwright supports this natively with --repeat-each=5, which runs every test five times. Any test that fails on at least one of those five runs gets flagged.
Quarantine and track. Once identified, flaky tests should be quarantined into a separate, non-blocking suite and tagged with the suspected root cause (timing, state, selector). This restores CI trust immediately while you work through the backlog. The critical discipline is treating quarantine as temporary: set a one-sprint SLA for investigation and resolution.
The detection step is where most teams stall. Without visibility into which tests are flaky, the problem feels unsolvable. With visibility, it becomes a prioritized engineering task. The data also reveals patterns: if 80% of your flaky tests involve API waits, you know where to focus your remediation effort.
Why the Manual Approach Does Not Scale
Each of the five root causes has a known fix. Race conditions need proper waits. Hardcoded sleeps need to be replaced with event-based waits. Shared state needs test isolation. DOM rendering needs framework-aware assertions. Selectors need stability.
The problem is not that these fixes are unknown. The problem is that they need to be applied by a human, consistently, across every test, for the lifetime of the product. And when a new developer joins the team, they need to internalize all five patterns before writing their first test. That does not happen. What happens instead is the whack-a-mole cycle:
A test flakes. Someone investigates. They find a hardcoded sleep or a missing wait. They fix it. They move on. Three weeks later, a different test starts flaking because a new feature introduced a lazy-loaded component that the existing tests did not account for. The cycle repeats.
This is the structural problem. Flaky tests are not a bug to fix. They are an emergent property of the gap between how applications actually work (asynchronously, with complex state dependencies) and how test scripts are written (sequentially, with implicit assumptions about timing and state). Closing that gap manually requires constant vigilance from experienced test engineers. Most teams, especially lean ones, simply do not have that bandwidth.
For a broader look at how these patterns compound in real test suites, our guide on reducing test flakiness walks through the tactical fixes in more detail.

The Structural Fix: Remove the Human from the Timing Loop
The manual approach to fixing flaky tests treats each flaky test as an individual problem. Diagnose the root cause. Apply the fix. Move on. This is like treating each pothole on a road individually instead of repaving the surface.
The structural fix is to remove the human from the timing and state management loop entirely. This is what agentic testing does, and it is fundamentally different from adding smarter retries or more sophisticated wait strategies.
Here is the distinction that matters. A retry strategy says: "This test failed. Run it again and hope the timing works out." A self-healing agent says: "This test failed because the DOM element was not yet actionable after a client-side navigation. The application uses React 18 concurrent rendering, which batches state updates. I will wait for the specific render cycle to complete before asserting."
The difference is understanding versus hoping. For a complete guide to how self-healing test automation works in practice, including concrete before-and-after scenarios, see our self-healing test automation guide.
How Agentic Testing Eliminates Flakiness Structurally
Autonoma is not a testing framework. It is not a record-and-replay tool. It is an autonomous agent that has full access to your codebase and uses that access to understand how your application works at the code level.
The agent reads your source code. It understands that your checkout page uses React.lazy() to load the payment form. It knows that your API calls go through a Redux middleware that dispatches loading states. It understands that your Next.js App Router pages hydrate asynchronously after server-side rendering.
The agent uses that understanding to write timing-aware tests. Instead of guessing how long an API call takes or whether a component has rendered, the agent knows what the application is doing internally. It waits for the specific state transitions that indicate readiness, not arbitrary time intervals.
The agent isolates state automatically. Because it reads your data models and API routes, it understands what state each test creates and how to prevent cross-test contamination. It does not need a human to manually seed data or configure browser contexts. It handles isolation as a first-class concern.
The agent adapts when the code changes. When a developer refactors a component, changes a selector, or modifies an API response shape, the agent detects the change and updates the affected tests autonomously. There is no ticket filed. No manual investigation. No "broken test" sitting in the backlog for three sprints.
This is fundamentally different from "smart retries" or "auto-healing selectors" offered by some testing tools. Those approaches treat symptoms. They re-run failed tests or try alternate selectors when the primary one breaks. They do not understand why the test failed, and they cannot prevent the same class of failure from recurring in a different test.
Autonoma prevents flakiness by understanding the application. That is the structural difference.
The Conventional Fixes, and Where They Break Down
To be fair to the conventional approach, here is a complete picture of the manual fixes for flaky tests, along with their limitations:
| Root Cause | Manual Fix | Limitation |
|---|---|---|
| Race conditions | Replace implicit waits with explicit waits for specific conditions | Requires deep understanding of application internals per test. New features introduce new timing patterns that existing tests do not account for. |
| Hardcoded sleeps | Replace sleep() with event-based waits (waitForSelector, waitForResponse) | Correct event varies by context. A waitForResponse that works for one API endpoint is wrong for another that returns cached data. |
| Shared state | Isolate tests with per-test browser contexts, database transactions, and data factories | Infrastructure complexity scales with test count. Maintaining data factories requires ongoing effort as schemas evolve. |
| DOM rendering delays | Use framework-aware assertions and wait for hydration/render completion | Framework behavior changes between versions. React 17 rendering differs from React 18. Next.js Pages Router differs from App Router. |
| Unstable selectors | Use data-testid, ARIA roles, or text-based selectors | Requires all developers to add data-testid attributes consistently. Discipline degrades over time as team membership changes. |
| Environment differences | Standardize CI environments with Docker containers and pinned dependency versions | Adds infrastructure complexity. Does not address timing differences between environments with different CPU/memory profiles. |
Every one of these fixes is correct. And every one of them requires a skilled human to implement, maintain, and extend as the application evolves. The question is not whether manual fixes work. They do. The question is whether your team has the bandwidth to apply them consistently, across every test, indefinitely.
For most teams, the honest answer is no. And that is not a failure of the team. It is a failure of the model. Scripted tests with human-maintained timing logic are structurally brittle. Making them less brittle requires more human effort, which scales linearly with your test suite size. At some point, the maintenance cost exceeds the value the tests provide, and the suite begins to decay.
When Manual Fixes Are Enough vs. When You Need a Structural Change
Manual flaky test fixes are sufficient when:
Your team has dedicated test engineers. If you have SDETs whose primary job is maintaining test health, the whack-a-mole cycle is manageable. They have the context and the time to diagnose root causes properly.
Your test suite is small. Under 50 tests, the probability of encountering multiple flaky tests simultaneously is low. One person can keep the suite healthy with occasional attention.
Your application changes slowly. If you ship a major UI change once a quarter, the burst of broken tests is manageable. The suite stabilizes between changes.
Manual fixes are not enough when:
Your team ships fast. If you deploy multiple times per day, every deployment risks introducing new timing characteristics that existing tests do not expect. The flake rate increases with deployment frequency.
You do not have dedicated test engineers. If your developers write tests as a secondary responsibility (a common scenario we cover in our QA automation guide for teams without QA), the depth of diagnosis that flaky tests require simply does not happen. Developers add retries, add sleeps, and move on.
Your test suite is growing. A 200-test suite with a 3% flake rate means six false failures per run. That is enough to make every run untrustworthy. The testing pyramid debate becomes irrelevant if none of your tests are reliable.
You are losing the trust battle. Once developers start ignoring test failures, reversing that cultural damage is extremely difficult. Re-establishing trust requires not just fixing the flaky tests, but maintaining zero-flake runs long enough for the team to believe the suite again. This is how regression testing suites die: flakiness erodes trust, trust erosion leads to skipped tests, and skipped tests lead to production bugs.
For teams in the second category, the structural fix is not "better manual processes." The structural fix is removing the human from the parts of the loop that humans are bad at: timing logic, state management, and continuous adaptation to code changes. That is what autonomous testing provides.
A Decision Framework for Your Team
If your CI pipeline is currently untrustworthy due to flaky tests, here is how to decide on your path forward:
Path 1: Manual remediation. Audit your test suite. Identify the top 10 flakiest tests (most CI systems can surface this data). Diagnose root causes using the five categories above. Fix them systematically. Commit to a zero-flake policy: any test that flakes gets immediately quarantined and investigated. This works if you have the engineering hours to invest and maintain.
Path 2: Hybrid approach. Fix the most critical flaky tests manually, but adopt agentic testing for new test creation. Autonoma generates timing-aware, isolated tests from your codebase, so new tests are structurally resistant to flakiness. Over time, the agent-maintained tests replace the manually-maintained ones. This works if you want to stop the bleeding without a full migration.
Path 3: Full agentic migration. Let Autonoma read your codebase and generate comprehensive test coverage from scratch. The agent handles timing, state isolation, and selector stability as first-class concerns. Your developers write product code. The agent writes and maintains test code. This works if your team has zero bandwidth for test maintenance and needs reliable coverage immediately.
Each path is valid. The choice depends on your team size, your deployment frequency, and honestly, how much patience you have left for debugging tests that should be finding bugs in your product instead of creating false alarms.
Getting Started
If you want to pursue the manual path, start with our comprehensive guide to reducing test flakiness. It covers every tactical fix in detail with code examples for Playwright, Cypress, and Selenium.
If you want to try the agentic path, Autonoma connects to your repository, reads your source code, and generates structurally sound tests that do not flake. No scripts to write. No timing logic to maintain. No sleeps to debug.
The best testing strategy is the one your team can sustain. For teams with dedicated testing bandwidth, that might be well-maintained scripts with disciplined wait patterns. For everyone else, the structural fix is to stop writing timing-sensitive test code altogether and let an agent that understands your application handle it.
Frequently Asked Questions
Flaky tests are caused by five root issues: race conditions between test actions and application responses, hardcoded waits (sleep statements) that guess at timing instead of waiting for specific events, shared state between tests (databases, cookies, browser storage), DOM rendering delays from async frameworks like React and Next.js, and unstable selectors that break when markup changes. Every flaky test has a deterministic cause. It only appears random because the triggering condition is intermittent.
Start by identifying your top 10 flakiest tests using CI analytics. For each one, diagnose the root cause: replace hardcoded sleeps with event-based waits, add test isolation for shared state issues, use framework-aware assertions for rendering delays, and switch to stable selectors (data-testid, ARIA roles). For a structural fix that scales, agentic testing platforms like Autonoma generate timing-aware, isolated tests directly from your codebase.
Retries reduce the visible impact of flakiness but do not fix the underlying cause. A test that needs retries to pass is still a flaky test. Retries mask real regressions (the test might fail for a legitimate reason but pass on retry), waste CI compute, and give teams a false sense of reliability. Use retries only as a temporary measure while you diagnose and fix root causes.
Agentic testing platforms like Autonoma read your source code to understand how your application works internally: which components render asynchronously, which API calls trigger state changes, and how data flows through the system. The agent uses this understanding to write tests with correct timing logic and state isolation built in. When the code changes, the agent adapts the tests automatically, preventing the selector breakage and timing drift that cause manual test scripts to flake.
Flaky tests fail intermittently on the same codebase due to timing, state, or environment issues. Brittle tests fail deterministically when the application changes, usually due to tightly-coupled selectors or hardcoded assertions. Both erode team trust, but the fix is different. Flaky tests need timing and isolation improvements. Brittle tests need better abstraction and stable selectors. In practice, most teams suffer from both simultaneously.
Test flakiness costs teams in three ways: wasted CI compute (re-runs from false failures), wasted developer time (investigating non-bugs and developing the re-run-and-hope habit), and eroded confidence (teams stop trusting and eventually stop writing tests). Google found that 16% of their tests exhibited flaky behavior. For most engineering teams, flakiness-related maintenance consumes roughly 40% of QA team time.
Quarantining flaky tests (moving them to a non-blocking suite) is a valid short-term strategy to restore CI trust. But quarantine without investigation is dangerous. Quarantined tests are tests you have decided not to run, which means they are not protecting you from regressions. Treat quarantine as a temporary state with a strict SLA: every quarantined test gets investigated and fixed (or deleted) within one sprint.



