
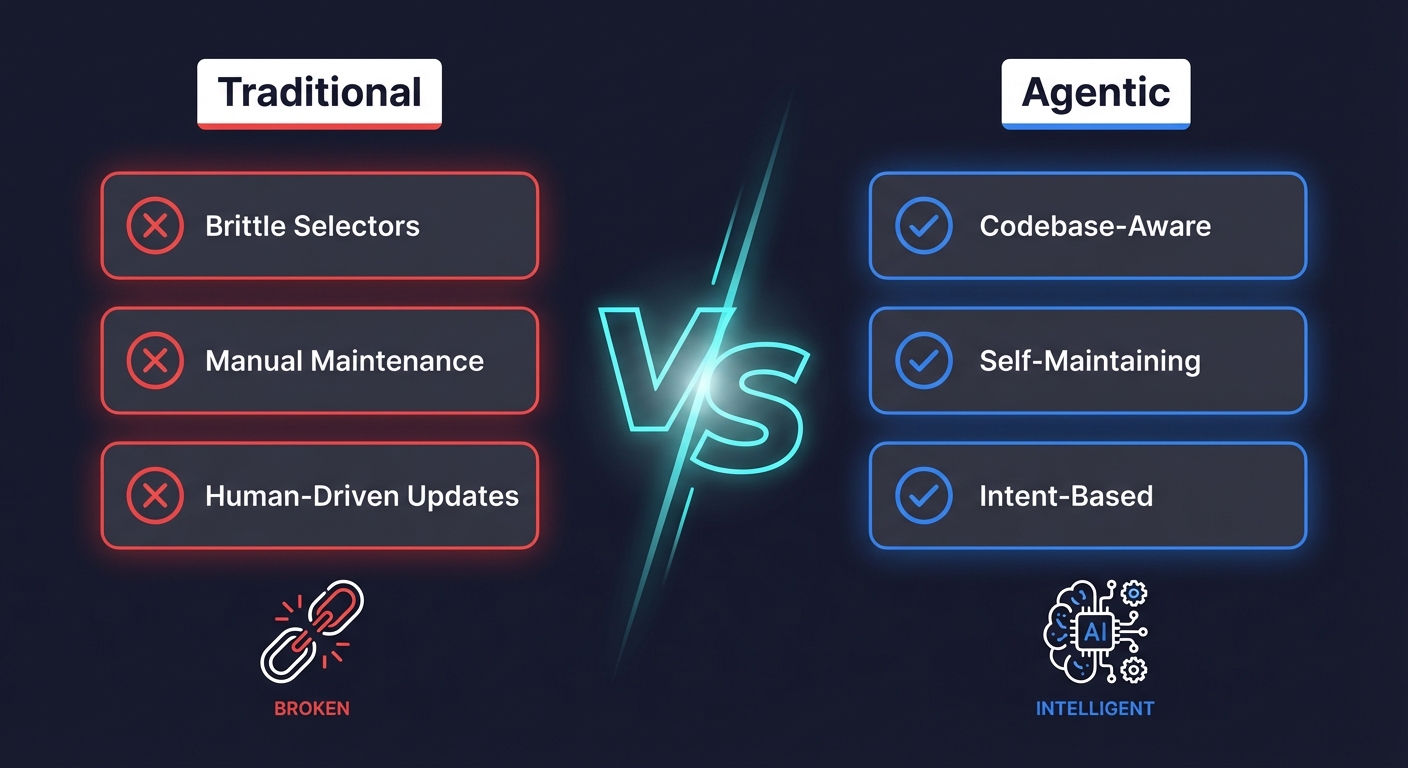
Regression testing is universally necessary but universally painful to maintain. The real cost isn't writing tests. It's the ongoing maintenance: updating selectors, fixing flaky assertions, rewriting flows after every UI change. For lean teams, this maintenance burden makes traditional automated regression testing unsustainable. Agentic testing platforms like Autonoma eliminate this burden by accessing your codebase, understanding what changed, and autonomously updating regression tests so they never go stale. The result: full regression coverage with near-zero maintenance cost.
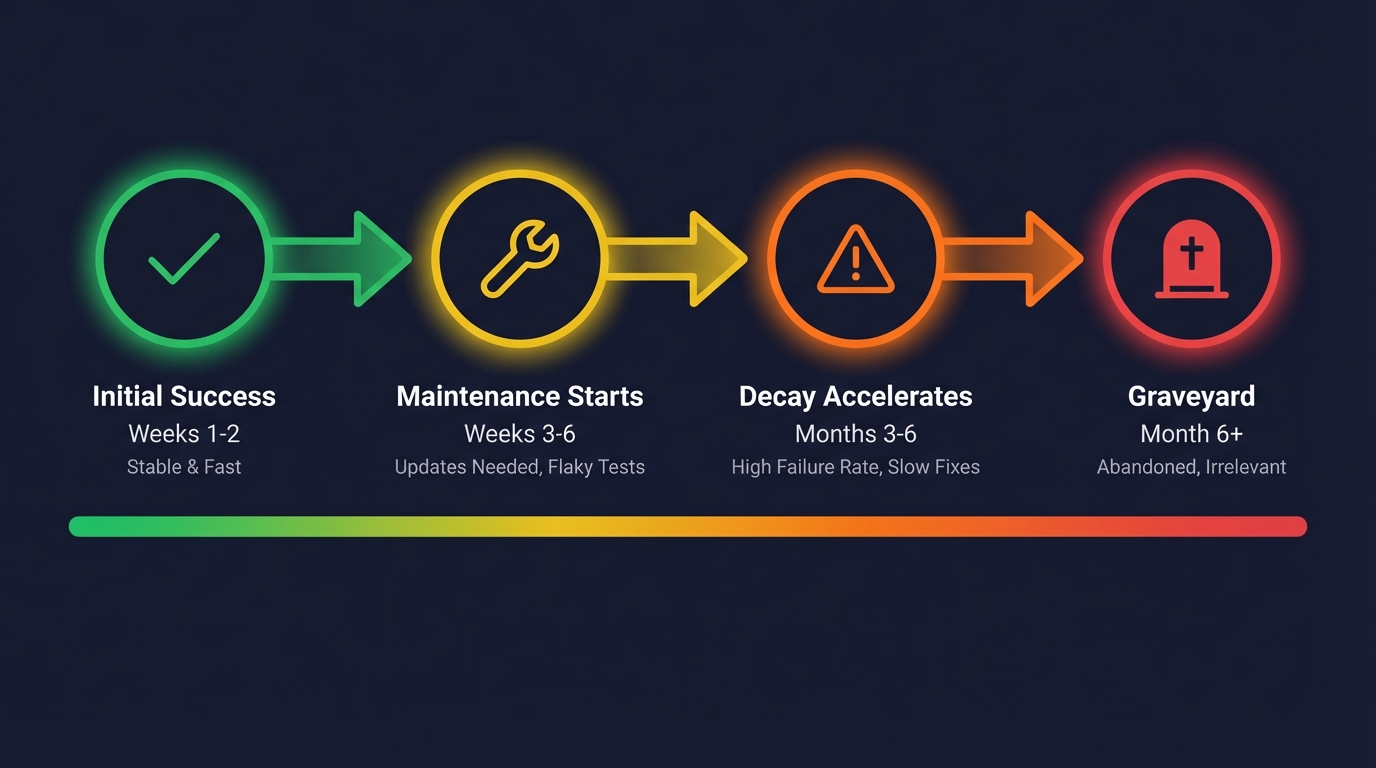
You write the tests, they work for two weeks, then someone renames a component and 40 tests turn red overnight. None of them found a real bug. All of them need your attention. This is the regression testing trap — and it's the reason most teams either abandon automated regression testing entirely or accept a permanent tax on their engineering velocity.
What Is Regression Testing?
Regression testing is the process of re-running existing tests after code changes to confirm that previously working functionality hasn't broken. It targets unintended side effects — the kind that slip in when a new feature, bug fix, or refactor interacts with existing code in unexpected ways. Every team that ships to production needs regression testing; the only question is how to do it without the maintenance cost becoming unsustainable.
Regression Testing vs Retesting
Regression testing and retesting sound similar but answer different questions. Retesting asks "did the fix work?" Regression testing asks "did the fix break anything else?"
| Aspect | Regression Testing | Retesting |
|---|---|---|
| Purpose | Catch unintended side effects of code changes | Confirm a specific defect has been fixed |
| Scope | Broad — covers existing functionality beyond the change | Narrow — targets only the originally failed test case |
| When performed | After any code change (feature, fix, refactor, dependency update) | After a specific bug fix is applied |
| Test cases used | Existing suite of previously passing tests | The specific test case that originally failed |
| Automation potential | High — ideal for automation and CI/CD integration | Lower — often done manually as a one-time verification |
When to Run Regression Testing
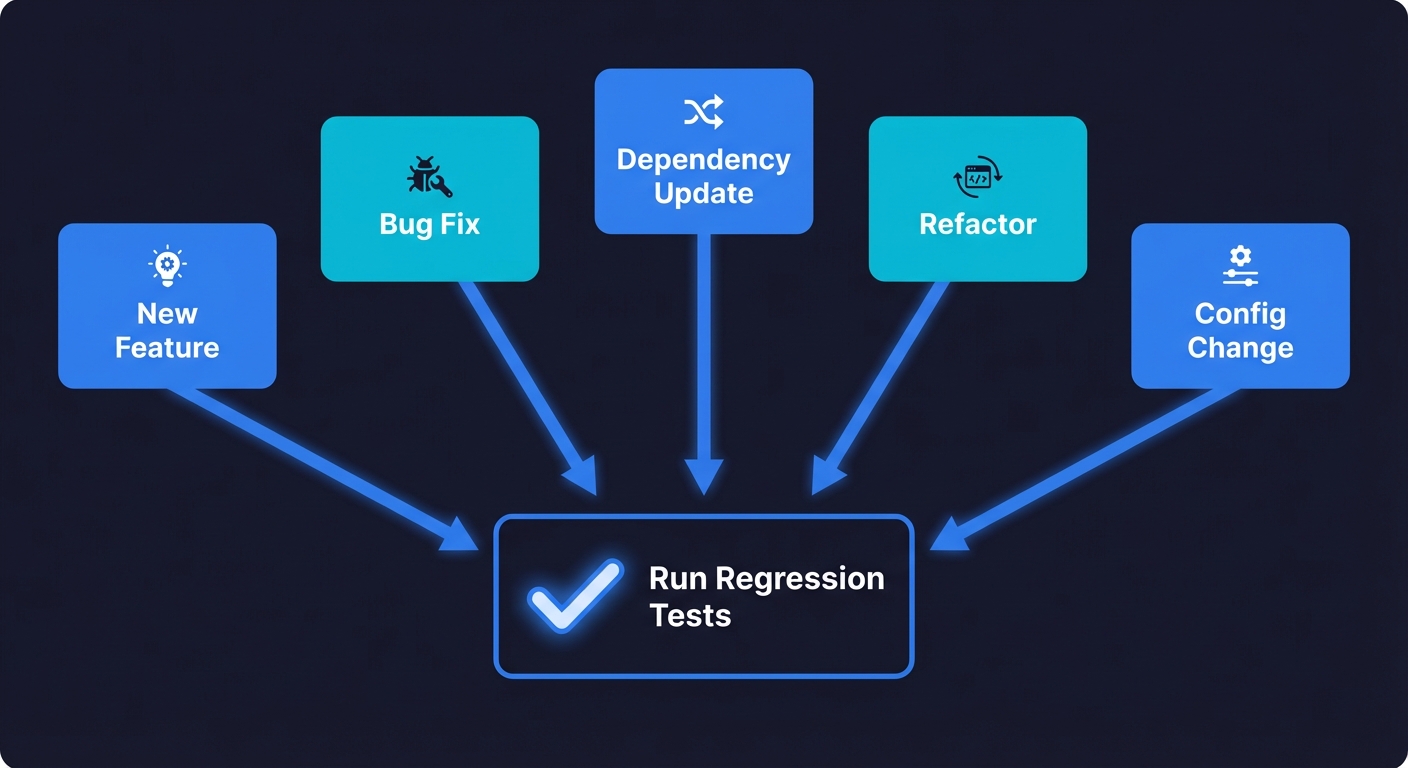
Regression testing verifies that previously working functionality still works after code changes. You need it every time you:
- Ship a new feature. New code interacts with existing code in ways you didn't anticipate. A new payment method breaks the existing checkout flow. A new dashboard widget breaks the navigation.
- Fix a bug. The fix itself can introduce side effects. You patch a date parsing bug and break the reporting module that depends on the old (incorrect) format.
- Update a dependency. A library upgrade changes behavior under the hood. Your date picker works differently after the update. Your form validation throws new error types.
- Refactor code. You restructure a module for clarity. The logic is identical. But a renamed export breaks three downstream components.
- Change configuration. A feature flag toggle, an environment variable change, or a database migration can silently break flows that aren't directly related.
The trigger is any change that could affect existing behavior. For teams practicing shift-left testing, regression tests ideally run as early as the pull request stage, not after deployment.
Types of Regression Testing (and Their Maintenance Cost)
The textbook lists seven types of regression testing. What the textbook doesn't tell you is that each type carries a different maintenance burden, and that burden is what determines whether the approach is sustainable for your team.
Selective regression testing runs only the tests affected by the recent change. This is the most practical approach for lean teams. It keeps cycles fast and maintenance focused. The challenge is knowing which tests are affected, something an agentic testing platform handles automatically by mapping code changes to test coverage.
Complete regression testing runs the entire suite after every change. It's thorough but expensive. For a team with 200 tests, complete regression on every PR means 200 tests to maintain, 200 tests that can break on any UI change, and 200 tests worth of flakiness to manage. Reserve this for pre-release gates, not daily development.
Progressive regression testing adds new tests for new features to the existing suite. The suite grows every sprint. This is where maintenance compounds most aggressively. Every new test is a future maintenance obligation. Without a strategy for test retirement or automated maintenance, progressive regression leads directly to the graveyard suite.
Corrective regression testing re-runs existing tests without modification after minor code changes. This is the lowest-maintenance type because the tests don't need updating. It only works when the change is truly minor and doesn't affect test assumptions.
Partial regression testing covers the changed area plus closely related functionality. It's a pragmatic middle ground between selective and complete. The risk is misjudging what's "closely related" and missing a regression in an unrelated module.
The type that matters most for your team is whichever one you can sustain. A selective regression strategy you actually maintain beats a complete regression strategy that degrades into a graveyard within six months.
The Regression Testing Maintenance Problem
The question is not which type of regression testing to use. The question is how to execute any of them without the maintenance cost consuming your team.
There are two common approaches, and both of them fail for lean teams.
Manual regression cycles. A QA engineer (or worse, a developer wearing a QA hat) clicks through the same flows every sprint. Login. Checkout. Search. Settings. Account management. The list grows every time you ship a feature. It never shrinks. By the time your application has 30 distinct user flows, manual regression takes days. I've seen teams where 40% of every sprint goes to manual regression testing. That's not a testing strategy. That's a tax on shipping.
Scripted automated regression testing. You write Playwright or Cypress scripts, or Selenium tests. The suite runs in CI. For a few weeks, it works beautifully. Then the UI changes. A designer moves a button. A developer renames a CSS class. Someone restructures the checkout form from three steps to two.
Suddenly, 30 tests fail. You investigate. None of them found a real bug. The application works perfectly. Your tests are broken because they're coupled to implementation details that changed.
You spend a day fixing broken tests. The next sprint, the same thing happens. And the sprint after that. Within three months, your team is spending more time maintaining regression tests than writing new features. Within six months, someone suggests disabling the flaky ones "just for now." Within a year, the suite is a graveyard of skipped tests and everyone is back to manual smoke testing before deploys.
This trajectory is not an edge case. It is the default outcome for teams that adopt traditional automated regression testing without accounting for the maintenance cost.
Why Automated Regression Testing Breaks Down
Understanding why regression tests break is the key to understanding why the traditional approach is fundamentally flawed for lean teams.
Selector coupling. Most automated regression tests locate elements on the page using CSS selectors, XPath expressions, or test IDs. When the DOM structure changes, even if the functionality is identical, the selectors stop matching and the test fails. A regression test that clicks .checkout-btn breaks when the class becomes .ds-button-primary, even though the button still does the same thing.
Flow coupling. Regression tests encode a specific sequence of steps. When the UX changes (a three-step checkout becomes a two-step checkout, a modal becomes an inline form), the test's step sequence no longer matches reality. The test fails even though the feature works better than before.
Data coupling. Tests that depend on specific database state, API responses, or seed data break when that data changes. A test that verifies "Order #12345 appears in the order history" breaks when the test database is reseeded.
Timing coupling. Tests that rely on specific load times, animation durations, or API response speeds break intermittently. These are flaky tests that pass locally, fail in CI, pass on retry, and slowly erode your team's trust in the entire suite. For a deeper treatment of this problem, see our guide on how to reduce test flakiness.
Every one of these failure modes produces the same outcome: a test that fails without finding a real bug. And every one of them requires human attention to diagnose and fix. That human attention is the maintenance cost, and it compounds with every test you add to the suite.
The Maintenance Tax on Lean Teams
Let me make the cost concrete.
Say you're a team of eight engineers. You've built 150 automated regression tests over six months. You're proud of your coverage. Your CI pipeline runs the full suite on every PR.
Here's what the maintenance actually looks like:
Week 1 after a UI redesign: 35 tests fail. An engineer spends two days updating selectors and flow sequences. No bugs were found. Two days of engineering time consumed.
Week 3: A dependency update changes the behavior of a date picker component. 12 tests that interact with date selection break. Half a day to fix.
Week 5: The product team ships a new onboarding flow. 20 tests that cover onboarding need to be rewritten from scratch. One engineer spends three days.
Week 7: Flaky tests are accumulating. Eight tests fail intermittently. The team adds retry logic. Two tests get marked as test.skip() because nobody can figure out why they're flaky. CI still takes 25 minutes.
Month 3: The team is spending 15 to 20% of their engineering capacity on test maintenance. That's effectively one full-time engineer doing nothing but keeping existing tests alive. For an eight-person team, this is the equivalent of losing one engineer to the regression suite.
Month 6: Someone proposes a feature that requires restructuring the settings page. The team's first reaction is not "how should we design this?" but "how many tests will this break?" The regression suite is now actively discouraging refactoring. The tool meant to enable confident shipping has become the reason the team ships slowly.
This is not hypothetical. I've watched this exact pattern at multiple companies. The regression suite starts as a safety net and becomes a ball and chain.
What Good Regression Testing Actually Requires
Before getting to the solution, it's worth being precise about what a well-functioning regression testing strategy looks like. The problem is not the concept. The problem is the execution model.
Good regression testing requires test selection. Not every test needs to run on every change. If you modified a billing module, you need regression coverage on billing flows. You probably don't need to re-run tests for the user profile page. Intelligent test selection, running only the tests affected by the changeset, is how you keep regression cycles fast.
Good regression testing requires test maintenance that scales. When your codebase changes, affected tests need to update. In a traditional model, a human does this. In a sustainable model, this happens automatically or with minimal human oversight.
Good regression testing requires stability. Tests that fail intermittently without finding real bugs are worse than no tests at all. They train your team to ignore failures, which means real bugs get ignored too. A regression suite must be trustworthy, or it's worthless.
Good regression testing requires speed. If the full regression suite takes four hours, it won't run on every PR. It might run nightly. Bugs discovered the next morning are dramatically more expensive to fix than bugs discovered in the PR review. Regression tests need to run fast enough to gate deployments without slowing them down.
Every one of these requirements is achievable with traditional scripted testing if you have the engineering resources to invest. The question for lean teams is whether that investment is the best use of your limited bandwidth. For most teams under 20 engineers, the answer is no.
Regression Testing Tools
Choosing the right tool depends on your team's language preferences, CI setup, and how much maintenance you're willing to absorb. Here's how the most common regression testing tools compare:
| Tool | Language Support | Best For | CI Integration | Learning Curve |
|---|---|---|---|---|
| Selenium | Java, Python, C#, JS, Ruby | Cross-browser testing at scale | All major CI platforms | Steep |
| Playwright | JS/TS, Python, Java, .NET | Modern web apps with auto-waiting and tracing | Native GitHub Actions, all major CI | Moderate |
| Cypress | JavaScript/TypeScript | Frontend-heavy apps with fast feedback loops | Cypress Cloud, all major CI | Low |
| Katalon | Groovy (built-in), Java | Teams wanting a low-code test authoring GUI | Built-in CI integration, Jenkins, Azure DevOps | Low |
| Autonoma | Language-agnostic (reads your codebase) | Lean teams that need regression coverage without maintenance | All major CI platforms, PR-triggered | Minimal |
For a deeper comparison of the two most popular open-source options, see our Playwright vs Cypress analysis. The key differentiator for lean teams is not feature set but maintenance cost: traditional tools require you to maintain every test manually, while an agentic platform like Autonoma maintains tests autonomously as your codebase changes.
Regression Testing in Agile and CI/CD
In agile environments, regression testing fits naturally into sprint cadences. Most teams run a targeted subset of regression tests — covering recently changed areas and critical paths — during each sprint. The full regression suite runs before release candidates or production deployments. This tiered approach balances speed with thoroughness: fast feedback during development, comprehensive verification before shipping.
CI/CD pipelines are where regression testing delivers the most value. Configure your pipeline to trigger relevant regression tests on every pull request and gate merges on passing results. This means regressions are caught before code reaches the main branch, not after. Teams using platforms like GitHub Actions, GitLab CI, or Jenkins can run regression suites in parallel across sharded browser instances to keep feedback times under five minutes even for large suites.
The hardest part is deciding which tests to run and when. Risk-based prioritization is the most practical approach: tests covering revenue-critical flows (checkout, billing, signup) run on every PR. Tests covering recently changed modules run next. Tests for stable, low-risk features run nightly or pre-release. This prioritization keeps CI fast while ensuring the highest-impact flows are always verified.
The Shift: From Writing Tests to Describing Intent
The fundamental problem with traditional automated regression testing is that tests encode implementation details instead of user intent.
When you write await page.click('[data-testid="checkout-submit"]'), you're not saying "the user completes checkout." You're saying "the user clicks the element with this specific test ID." The intent is the same, but the encoding is brittle. Change the test ID, and the test breaks. Change the flow from a button click to a keyboard shortcut, and the test breaks. The intent hasn't changed, but the implementation has.
This is why agentic testing represents a fundamentally different approach to regression testing. An agentic testing platform doesn't record selectors or hard-code step sequences. It accesses your codebase, reads your components, routes, and API endpoints, understands the user flows at the intent level, and generates tests that verify outcomes rather than implementation steps.
When your code changes, the agent doesn't break. It re-reads the codebase, identifies what changed, evaluates whether the change affects any existing test's intent, and updates the test accordingly. The human never gets paged to fix a broken selector. The human never spends a day rewriting tests after a UI refresh.
This is not "self-healing" in the limited sense of retrying a different selector when the first one fails. That's a bandaid. This is an agent that understands your application and maintains your regression suite the way a senior engineer would, except it does it automatically, on every code change, without burning engineering hours.
How Agentic Regression Testing Works in Practice
Let me walk through what this looks like concretely with Autonoma.
Initial setup. Autonoma connects to your repository. It reads your codebase: routes, components, API handlers, database models. From this, it builds a model of your application's user flows. It identifies the critical paths (signup, core workflow, billing, settings) and generates end-to-end regression tests for them.
Ongoing regression. When you push code, Autonoma detects the changeset. If you modified the checkout component, it knows which regression tests cover checkout. It re-reads the updated component, evaluates whether the test's intent is still valid, and updates the test if the implementation changed. If the change introduced a genuine regression (the checkout flow is actually broken), the test fails for the right reason.
Test selection. Because the agent understands which code maps to which tests, it runs only the relevant subset of your regression suite on each change. A change to the billing module runs billing tests. A change to the onboarding flow runs onboarding tests. A change to a shared utility runs everything that depends on it. This keeps regression cycles fast without sacrificing coverage.
No selector maintenance. There are no brittle selectors to fix because the agent doesn't rely on static selectors. It understands the application structure and locates elements through that understanding. When a CSS class changes, the agent doesn't notice, because it was never dependent on the CSS class.
No flow rewriting. When a three-step checkout becomes a two-step checkout, the agent reads the new flow, recognizes the intent is the same (user completes a purchase), and generates the updated test. No human intervention.
Compare this to the traditional model where an engineer spends days after every UI change manually updating test scripts. The engineering hours saved compound with every sprint.
Regression Testing Strategy for Lean Teams
Here is the strategy I recommend for teams of 3 to 20 engineers who need regression coverage without the maintenance burden.
Identify your critical flows. List every user-facing flow in your application. Rank them by business impact: what breaks if this flow fails? Revenue-critical flows (checkout, billing, signup) come first. Core activation flows come second. Everything else comes third. For a detailed framework, see our E2E testing playbook for startups.
Get automated regression coverage on the top tier. Your 3 to 5 most critical flows should have automated regression tests that run on every PR. This is non-negotiable. Whether you achieve this with an agentic platform like Autonoma or with hand-written scripts, these flows must be covered. If you have no testing function at all, start with our QA automation guide for teams with no QA before building a regression strategy.
Decide how you'll handle maintenance. This is the decision that determines whether your regression strategy survives past month three. If you have dedicated QA engineering capacity (at least one full-time engineer whose job includes test maintenance), scripted tests can work. If you don't, and most teams under 20 engineers don't, the maintenance will eventually overwhelm you. An agentic approach eliminates this constraint. See our guide on whether to hire a QA engineer for help with this decision.
Run regression tests at the right cadence. Fast, targeted regression tests should run on every PR. The full regression suite should run before every deployment to a production environment. Extended regression (including edge cases and less critical flows) can run nightly. For teams deploying to preview environments on platforms like Vercel or Netlify, we've written specific guides for regression testing on Vercel preview deployments and regression testing on Netlify deploy previews.
Expand coverage incrementally. After your critical flows are covered, add regression tests for the next tier of flows. Then the next. The key is that each new test must be maintainable. If adding 10 more tests means 10 more tests that break on UI changes, you've increased your maintenance burden without proportional benefit. If adding 10 more tests through an agentic platform means 10 more tests that maintain themselves, the marginal cost of expanding coverage is near zero.
What Regression Testing is Not
Regression testing is one layer of a complete testing strategy, not the whole thing. It's worth being clear about what regression testing does and does not cover.
Regression testing is not exploratory testing. Regression tests verify known flows. They don't discover new categories of bugs. Exploratory testing, where a human uses the application creatively to find unexpected failures, remains valuable and cannot be fully automated. For a broader view of how regression testing fits within a quality engineering practice, see our systems guide for engineering leaders.
Regression testing is not performance testing. A regression test verifies that the checkout flow works. It doesn't verify that the checkout flow works under 500 concurrent users. Performance testing is a separate discipline.
Regression testing is not security testing. Regression tests don't probe for SQL injection, XSS, or authentication bypasses. Security testing requires specialized tools and approaches.
Regression testing is not unit testing. Unit tests verify that individual functions work correctly in isolation. Regression tests verify that the application works correctly as a whole. Both are valuable, but they serve different purposes. Unit tests are excellent for complex business logic with many edge cases. Regression tests are excellent for verifying that user-facing flows haven't broken. For more on how these layers relate, see our piece on the testing pyramid.
The mistake many teams make is treating regression testing as a substitute for all other testing. It's not. It's the specific answer to one specific question: did we break something that used to work?
Measuring Regression Testing Effectiveness
You should track three metrics for your regression testing program. Just three. Teams that track more than this are usually tracking vanity metrics that don't drive decisions.
Escaped defect rate. How many bugs reach production that your regression suite should have caught? This is the single most important metric. If bugs are regularly escaping to production in flows that have regression coverage, your tests are not effective. Either they're testing the wrong things, or they're broken and being ignored.
Maintenance cost ratio. What percentage of your engineering time goes to maintaining regression tests versus building features? If this exceeds 10%, your regression approach is unsustainable. If it exceeds 20%, it's actively harming your ability to ship. Most teams using traditional scripted tests land between 15% and 25%. Teams using agentic testing report under 2%.
Mean time to regression detection. How long after a regression is introduced does your suite catch it? If your regression tests only run nightly, a regression introduced Monday morning isn't caught until Tuesday. If they run on every PR, the regression is caught before the code merges. Shorter detection time means cheaper fixes.
The Economics of Automated Regression Testing
Let me put real numbers on this.
Traditional scripted approach for an eight-person team:
- Initial test creation: 3 to 4 weeks of engineering time across sprints
- Ongoing maintenance: 8 to 12 hours per week (one engineer's time, roughly)
- Annual maintenance cost: 400 to 600 engineering hours
- At a blended engineering cost of $120/hour, that's $48,000 to $72,000 per year in maintenance alone
- This doesn't count the opportunity cost of features not built
Agentic approach with Autonoma:
- Initial setup: hours, not weeks
- Ongoing maintenance: near zero (the agent handles it)
- Annual maintenance cost: effectively $0 in engineering hours
- Engineering time is freed for feature development
The comparison is not "scripted tests versus no tests." It's "scripted tests with a permanent maintenance tax versus automated tests that maintain themselves." For a team that can't afford to dedicate an engineer to test maintenance (which is most teams under 20 people), the agentic approach is not just more convenient. It is the only approach that's sustainable.
When Regression Testing Goes Wrong
The most common failure modes I see, ranked by frequency:
The graveyard suite. The team wrote 200 regression tests over six months. 80 of them are marked test.skip(). 40 are flaky and everyone ignores their failures. The remaining 80 cover basic happy paths but miss the edge cases where bugs actually live. The suite provides a false sense of security. The team thinks they have regression coverage. They don't.
The bottleneck suite. The regression suite takes 90 minutes to run. PRs sit in queue waiting for the suite to complete. Engineers start merging without waiting for results. The suite becomes a background process that nobody watches, which is the same as not having it.
The change-averse suite. Every refactor breaks 30 tests. Engineers start avoiding refactors. Technical debt accumulates because the regression suite punishes improvement. The tool meant to enable safe changes becomes the reason the team is afraid to make changes.
The coverage theater suite. The team tracks test coverage as a KPI. Coverage is at 85%. Management is happy. But the tests verify trivial behavior (this component renders, this function returns a string) while critical user flows have no coverage at all. The number looks good. The protection is absent.
Every one of these failure modes stems from the same root cause: regression tests that require human maintenance will eventually outpace the team's capacity to maintain them. The suite degrades. Trust erodes. The team reverts to manual testing or ships without testing at all.
Moving Forward
Regression testing is not optional. Every codebase that ships to production needs some form of regression verification. The question is not whether to do it but how to do it without drowning in maintenance.
The traditional approach, writing and manually maintaining scripted tests, works if you have the engineering resources to sustain it. For large organizations with dedicated QA teams, it's a viable strategy. But for lean teams shipping fast, the maintenance burden makes it unsustainable.
The shift is from writing tests to describing intent. From maintaining selectors to letting an agent that understands your codebase keep your regression suite current. From spending 20% of your engineering capacity on test maintenance to spending that capacity on building the product your users care about. This is especially critical as AI coding agents accelerate the volume of code changes: the more code changes per sprint, the more regression testing matters, and the less sustainable manual maintenance becomes.
If you're spending more time fixing broken tests than catching real bugs, the problem is not your tests. The problem is your testing model. Agentic testing platforms like Autonoma access your codebase, understand your application, and autonomously maintain your regression suite so you can ship with confidence without the maintenance tax.
Your codebase will change every sprint. Your regression tests should keep up without burning engineering hours.
Frequently Asked Questions
Regression testing verifies that previously working functionality still works after code changes. Every time you add a feature, fix a bug, update a dependency, or refactor code, you risk breaking something that was already working. Regression tests catch those breaks before users do.
Retesting verifies that a specific bug fix works. Regression testing verifies that the fix (or any code change) didn't break other existing functionality. You retest the thing you changed. You regression test everything else. Both are necessary, but they answer different questions.
Automated regression testing uses scripts or AI agents to verify that existing functionality hasn't broken, without manual human testing. Traditional tools like Playwright and Cypress require ongoing maintenance when the UI changes. Agentic platforms like Autonoma read your codebase and autonomously maintain the tests, eliminating that maintenance burden.
The main types are selective (tests affected by the change), complete (entire suite), progressive (adding tests for new features), corrective (re-running unchanged tests), and partial (changed area plus related flows). The right type depends on your team's capacity to maintain the suite. Selective regression is the most sustainable for lean teams.
Critical flow regression tests should run on every pull request. The full suite should run before every production deployment. Extended regression covering edge cases can run nightly. If your suite is too slow for every PR, split it into a fast critical tier and a slower comprehensive tier.
They break because they encode implementation details (CSS selectors, DOM structure, step sequences) rather than user intent. When someone changes a CSS class or restructures a form, tests fail even though the application works correctly. This coupling to implementation is the primary source of regression test maintenance cost.
Agentic regression testing uses AI agents that access your codebase, understand your application, and autonomously generate, execute, and maintain regression tests. When code changes, the agent detects the impact and updates tests automatically. This eliminates the maintenance cost that makes traditional automated regression testing unsustainable for lean teams.
Start with 3 to 5 critical user flows: signup, core activation, checkout, and your most frequently changed feature. This translates to 10 to 30 tests. Expand after the critical tier is stable. 30 well-maintained regression tests catch more bugs than 300 broken ones.
Yes, but it doesn't scale. Manual regression works for small apps with infrequent releases. Once you're deploying daily or weekly, manual regression consumes unsustainable engineering time. Automation is necessary to maintain velocity.



