
Key Takeaways: The shift left approach is about catching bugs earlier, ideally before code is merged. For small teams without dedicated QA, this means automated tests that run continuously in CI, not a manual process bolted onto the end. The practical question isn't "should we shift left?" but "how do we actually do it with eight engineers and no QA function?"
A bug found before the PR merges costs minutes. The same bug found in production costs hours, plus user trust you can't get back. The core idea is simple — but every guide you'll find was written for a 500-person engineering org. Here's what shift left actually looks like when there's no QA team to shift.
The Problem with How Enterprises Talk About Shift Left Testing
Search "shift left testing" and you'll find IBM white papers, Dynatrace enterprise guides, and Wikipedia definitions that read like they were written for a 500-person engineering org with a dedicated QA department, a test environment team, and a release manager. You'll read about "organizational culture transformation," "cross-functional alignment," and "test infrastructure investment."
None of that is relevant to your situation.
You have eight engineers. No QA. You're shipping multiple times a week. Someone probably clicks through the app before a big deploy, maybe runs a smoke test, then pushes and watches Sentry for a few hours. That's your current "QA process," and it's fine for a while, until it isn't.
The enterprise framing of shift left is architecturally sound but operationally useless for small teams. So let's rebuild it from first principles.
What Is Shift Left Testing, Really?
Shift-left testing is the practice of moving testing activities earlier in the software development lifecycle — from post-development to requirements and design phases. The term was coined by Larry Smith in a 2001 Dr. Dobb's Journal article, arguing that testing should begin at the earliest possible stage.
So what is shift left testing in practical terms? Picture your development timeline as a horizontal line. On the far left: writing code. On the far right: production. In the middle: code review, CI, staging, deploy.
"Shifting left" means moving your quality checks toward the left side of that line. Testing in development, not after deployment. Finding bugs before they reach users, not after.
The reason this matters economically is well-documented. A bug caught during development takes one engineer a few minutes to fix. That same bug caught by a user after deployment takes debugging time, a hotfix, a deploy, potential customer support involvement, and reputation damage you can't measure. The IBM Systems Sciences Institute put the cost multiplier at roughly 30x between development and production. A National Institute of Standards and Technology (NIST) study found similar results, estimating that software bugs cost the US economy $59.5 billion annually, with a significant portion attributable to late-stage detection. The exact numbers are debated, but the direction isn't: earlier is cheaper.
The enterprise version of shifting left involves hiring QA engineers earlier in the process, embedding testers in feature teams, setting up dedicated test environments, and implementing formal test plans. That's the right answer at scale.
At eight engineers, none of that is on the table. If you're weighing the decision of whether to hire a QA engineer, the calculus changes when you consider self-maintaining alternatives. So the question becomes: what does shifting left actually look like when there's no QA team to shift?
Shift Right vs Shift Left Testing
While shift left testing moves quality checks earlier in the development process, shift right testing takes the opposite approach: validating software behavior in production. Shift right techniques include canary releases, feature flags, A/B testing, observability, and chaos engineering. Both strategies are complementary, not competing — but they address different risk profiles.
| Aspect | Shift Left Testing | Shift Right Testing |
|---|---|---|
| When | During development, before code merges | After deployment, in production |
| Focus | Preventing defects from reaching users | Detecting issues in real-world conditions |
| Techniques | Unit tests, integration tests, E2E in CI, code reviews | Canary releases, feature flags, observability, chaos engineering |
| Goal | Catch bugs early when they're cheap to fix | Validate behavior under real user load and data |
| Risk addressed | Regressions, broken flows, logic errors | Performance issues, edge cases, infrastructure failures |
For startups with small teams, shift left is where the ROI lives: preventing bugs before they ship is far cheaper than discovering them in production. Shift right becomes more important as you scale and need to validate behavior under real-world conditions that staging can't replicate.
The Startup Version of Shift Left Testing
For a small team, shifting left is really about one thing: automated tests that run before code ships, not after.
Not a QA person reviewing PRs. Not a test environment that someone manages. Automated coverage that runs in CI, catches regressions before they reach main, and doesn't require anyone to babysit it.
Here's the practical reality of most startups at the 8-engineer stage:
You probably have unit tests for critical business logic. Maybe 20-50 of them, written by the engineers who built the features, run in CI. This is already shifted left. Good.
You probably don't have reliable E2E test coverage for your core user flows. The checkout path, the onboarding sequence, the feature that generates 80% of your revenue. These are tested manually, intermittently, by whoever remembers to check before deploying.
That gap is where bugs live. And closing it is what shift left actually means for you. For a deeper look at building that coverage from scratch, see our E2E testing playbook for startups.
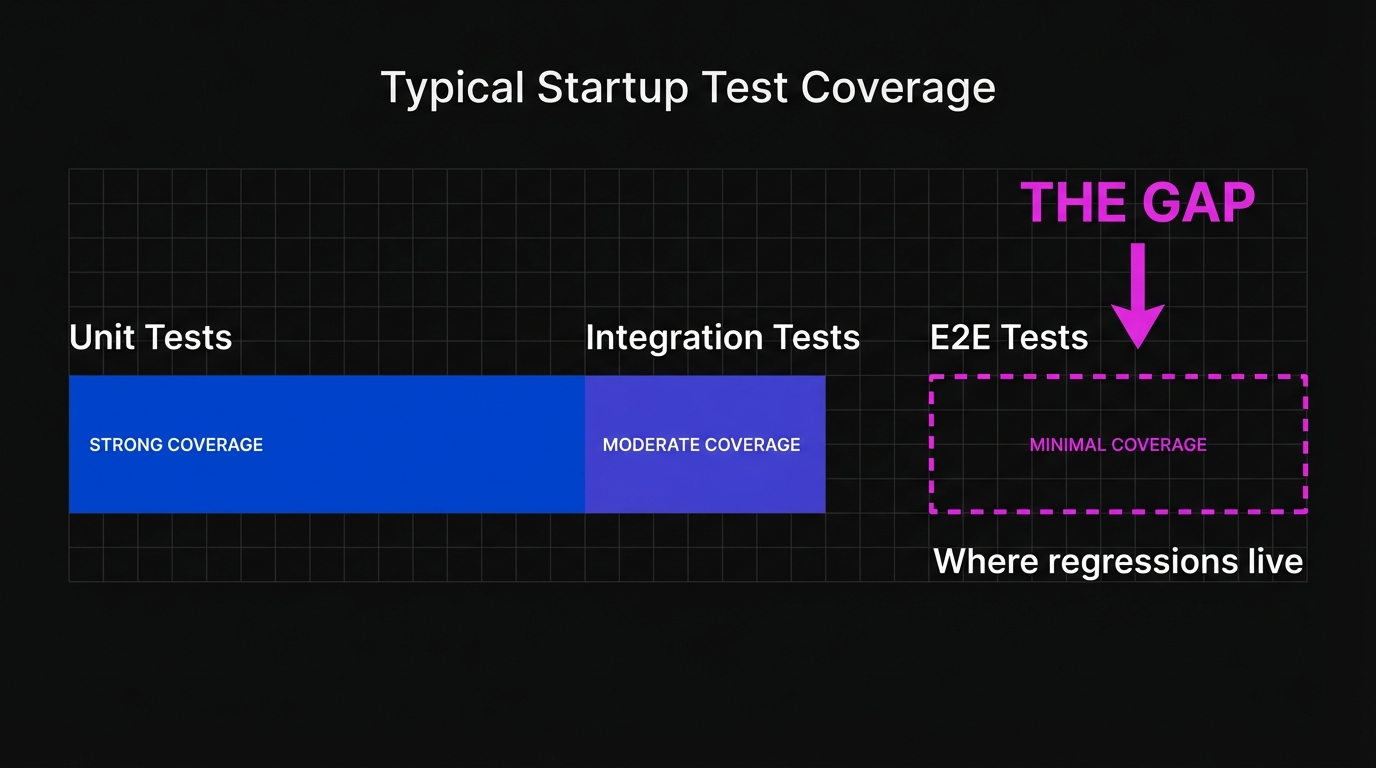
Why E2E Testing Is Where Most Startups Get Stuck
Unit tests are easy to maintain because they test isolated logic. Change the function, update the test. One-to-one relationship.
E2E tests are harder because they test your application as a user experiences it, clicking through real flows in a real browser. When your UI changes (which it does constantly at the startup stage), E2E tests break. Not because the feature is broken, but because a CSS class changed, a button was renamed, a form was refactored.
The maintenance burden compounds. We've talked to founders who built Playwright suites of 50-100 tests that worked great for three months, then became a liability. Developers stopped running them. Someone disabled the CI check "temporarily." The suite still existed but no longer served its purpose.
This is the shift left paradox for startups: the testing that would help most (E2E, user flow coverage) is the testing that's hardest to maintain with a small team. So teams either skip it or build it and watch it rot. This is precisely why self-maintaining E2E solutions like Autonoma exist: they close the coverage gap without adding to the maintenance load.
If you've read about integration testing vs E2E testing, you'll recognize this tension: integration tests are more maintainable but miss what E2E tests catch. For most startup workflows, you need both, which is exactly the problem.
The Three Layers of a Practical Shift Left Strategy
For a small team, a workable shift left approach has three layers. They don't require equal investment, and you don't need to implement all three at once.
| Layer | What It Covers | Maintenance Cost | Tools | When to Add |
|---|---|---|---|---|
| Unit tests in CI | Business logic, calculations, data transforms | Low | Jest, Vitest, pytest | Day one (table stakes) |
| Integration tests for API | Backend endpoints, auth, data contracts | Medium | Vitest, Jest, pytest, Supertest | When you have 3+ API endpoints |
| E2E tests for critical flows | Checkout, onboarding, core features | High (traditional) / Low (agentic) | Autonoma, Playwright, Cypress | When a broken user flow costs revenue |
The first layer is unit tests in CI. Most teams already have this. If not, start here. Focus on business logic: pricing calculations, auth rules, data transformations. These tests are fast, cheap to maintain, and catch the bugs that matter most at the code level. Run them on every PR. Block merges on failure. This is table stakes.
The second layer is integration tests for your API. If your product has a backend, your API endpoints are the contract between your code and your frontend. Testing them directly, without a browser, is fast and stable. A broken auth endpoint or a bad data query shows up immediately without UI fragility. Tools like Vitest, Jest, or pytest work well here. This layer is where most small teams have a gap and where the return on investment is high relative to the maintenance cost.
The third layer is E2E coverage for critical user flows. This is the hardest layer to maintain with a traditional test automation framework. But it's also the layer that catches the bugs your users actually experience: a checkout flow that silently fails, an onboarding step that errors on mobile, a feature that works in development but breaks in production with real data.
The key insight for small teams is that you don't need comprehensive E2E coverage. You need coverage of the flows that would be catastrophic to break: your payment path, your core feature, your login. Five well-placed E2E tests that run reliably are worth more than a hundred flaky ones nobody trusts.
Shift Left Testing in Action: A Concrete Example
Your engineer pushes a PR that refactors the checkout form. They've changed the button component from a custom <SubmitButton> to the design system's <Button variant="primary">. Unit tests pass: the component renders, the props work, the styles apply correctly.
But the click handler was accidentally dropped during the refactor. The button renders beautifully and does nothing when clicked. Without E2E coverage running in CI, this ships to production. With it, the PR is blocked before merge. The engineer fixes it in five minutes. That's shift left testing in one sentence: the bug costs five minutes instead of five hours plus a customer complaint.
The Maintenance Problem Is the Real Blocker
A conventional approach to E2E testing means someone on your team writes and maintains Playwright or Cypress scripts. That person has to update tests every time the UI changes. Every sprint. Every design refresh. Every component rename.
For a 3-QA team at a big company, this is a job. For a 6-engineer startup where everyone is also building features, it's a tax that eventually gets skipped.
This is why the traditional "shift left" advice doesn't translate to small teams. It assumes you have QA capacity to absorb the maintenance. You don't.
What actually works at the startup scale is E2E coverage that doesn't require constant maintenance. Tests that adapt when your UI changes, not tests that break and wait for someone to fix them. If you want to understand the full range of what creates test flakiness and how to combat it, the patterns are consistent: brittle selectors, hard-coded waits, and tests that don't understand intent.
The reason we built Autonoma the way we did is directly connected to this problem. Our customers aren't enterprises with QA departments. They're teams like the ones above: eight engineers, no QA, shipping fast. The shift left approach only works for them if the E2E layer is self-maintaining.
How Autonoma Makes Shift Left Testing Viable for Small Teams
When you connect your codebase to Autonoma, a Planner agent reads your routes, components, and user flows, then generates test cases automatically. You don't define the tests. The codebase is the spec.
A Maintainer agent watches for code changes and keeps tests passing as your UI evolves. When a button is renamed, when a form is refactored, when a CSS class changes, the agent adapts. No one has to fix broken selectors at 11pm before a deploy.
This is what makes the third layer of shift left actually achievable for a small team. The E2E coverage exists, runs in CI, and doesn't create a maintenance burden. You get the benefit of earlier bug detection without the ongoing cost that usually makes E2E testing impractical at your scale.
The result, practically speaking: a bug in your checkout flow gets caught when the PR runs in CI, not when a customer tries to pay. That's shifting left. That's the whole point.
This is an example of generative AI in software testing applied to the shift left problem. For context on how this fits into the broader landscape of AI for QA, agentic testing sits at the far end of the spectrum: not AI helping you write scripts, but AI owning the entire test lifecycle.

Where to Start if You're an 8-Engineer Team Today
Don't try to implement everything at once. Here's what actually moves the needle:
Start with whatever layer is currently missing. If you have no automated tests, unit tests for your core business logic are the first day's work. If you have unit tests but nothing for your API, add integration tests for your three most critical endpoints this week. If you have those but your E2E coverage is manual, that's where the shift left investment pays most.
For E2E specifically, the honest answer is that a self-maintaining approach is worth more than a manually-maintained one, even if it costs more. The math changes when you account for the engineering hours spent fixing broken tests versus the hours saved by catching regressions earlier. Agentic testing exists precisely because the traditional approach doesn't scale to small teams.
The one thing to avoid: building a comprehensive test suite and then letting it rot. A rotting suite is worse than no suite. It creates a false sense of coverage, erodes trust in CI, and eventually gets disabled entirely. If you're going to invest in E2E coverage, invest in coverage that stays green without constant human intervention.
The Shift Left Mindset for Teams Without QA
It's worth noting the contrast with "shift right" testing, which focuses on testing in production through monitoring, canary deploys, and feature flags. Both have value. Shift right catches issues in real user conditions. But for a startup, shift left is where the ROI lives: you can't afford to find bugs in production when five engineers are your entire company.
The enterprise version of shift left is about organizational process: where in the development lifecycle does QA get involved? That's not your problem.
Your problem is simpler and more tractable: bugs should be caught by CI, not by users.
If a regression in your checkout flow requires a customer to email support before anyone notices, you don't have a shift left problem; you have a coverage problem. The fix isn't hiring QA. It's getting automated tests in place that run every time code changes.
That's it. That's the startup shift left strategy. Everything else (the IBM white papers, the organizational transformation frameworks, the enterprise QA maturity models) is noise for your stage.
Get your unit tests running in CI. Add integration tests for your API. Get E2E coverage on your critical flows using a tool that doesn't require a human to maintain it. Ship faster and with more confidence because bugs get caught before they reach production.
If you want to see how this works in practice, connect your codebase to Autonoma and the agents will handle the E2E layer. Or book a demo if you want to see it on your specific application first.
Frequently Asked Questions
Shift left testing means moving quality checks earlier in the development process, catching bugs during development rather than after deployment. The 'left' refers to the left side of a development timeline, where code is written. Bugs found earlier are significantly cheaper to fix than bugs found in production. For small teams, shift left practically means automated tests running in CI before code merges, not a manual QA process at the end of the cycle. Tools like Autonoma make this achievable by generating and maintaining E2E tests without manual effort.
The shift left approach is the practice of integrating testing and quality checks as early as possible in the software development lifecycle. Instead of testing being a final gate before release, it becomes part of development itself: unit tests run on every commit, integration tests run on every PR, and E2E tests run before code merges to main. The goal is to surface defects when they're cheapest to fix, rather than discovering them through user reports after deployment.
Without dedicated QA, shift left means automated coverage that runs without human intervention. Start with unit tests for business logic, add integration tests for your API layer, and use a self-maintaining E2E solution for critical user flows. The key is avoiding test suites that require constant maintenance. When tests break due to UI changes and no one fixes them, they get disabled and the coverage disappears. Tools like Autonoma generate and maintain E2E tests automatically, which makes the third layer viable for teams without QA capacity.
Shift left testing is specifically about moving quality validation earlier in the development cycle. DevOps is a broader philosophy about integrating development and operations, including deployment, infrastructure, monitoring, and culture. Shift left is one component of a DevOps approach (the testing side of the 'continuous quality' principle). You can practice shift left testing without a full DevOps transformation, and vice versa.
Not exactly. TDD is a specific practice where you write tests before writing the code that makes them pass. Shift left testing is a broader strategy about when in the development lifecycle testing happens. TDD is one way to implement shift left thinking, but you can shift left without doing TDD. For most startups, the practical application of shift left is automated CI tests that run before code ships. TDD is one philosophy for writing those tests, but not the only one.
The main challenge is E2E test maintenance. Unit and integration tests are relatively stable and cheap to maintain. E2E tests, which test real user flows in a browser, break every time the UI changes, and a startup's UI changes constantly. For a small team with no dedicated QA, maintaining E2E scripts becomes a tax that eventually gets skipped. The solution is E2E coverage that self-heals when the UI changes. Autonoma handles this automatically, so the maintenance burden doesn't fall on the engineering team.
Autonoma's agents generate E2E tests from your codebase and keep them passing as your UI evolves. You connect your repo and the Planner agent reads your routes, components, and user flows to create test cases automatically. The Maintainer agent updates tests when your code changes. This gives small teams reliable E2E coverage in CI (the third layer of a shift left strategy) without the maintenance burden that usually makes it impractical at small team scale.



