
Generative AI in software testing means AI that reads your codebase, understands application behavior, and autonomously generates, executes, and maintains tests — no scripts, no selectors, no manual maintenance. Here's what that looks like in practice:
- Codebase-first test generation — AI reads your routes, components, and user flows to automatically create and execute test cases.
- Self-healing maintenance — when your code changes, the AI adapts tests instead of breaking on stale selectors.
- Full lifecycle ownership — unlike AI-assisted scripting tools (Copilot, Cursor), the AI owns everything. You connect your repo; agents handle the rest.
Most articles about generative AI and testing describe a future that hasn't arrived yet — aspirational language, shallow examples, mechanisms never explained. This article is different. It covers what's happening right now, on real codebases: how AI reads code, derives understanding of what an application does, and uses that understanding to generate and maintain tests automatically. If you're a startup with five engineers and no dedicated QA, this isn't a future trend to monitor. It's a decision you can make today.
Why Was Test Generation Hard Before Generative AI?
To understand what generative AI changes, you need to understand what made test generation difficult before it.
Traditional test automation frameworks like Playwright and Cypress are powerful, but they're fundamentally dumb about your application. They don't know what your app does. They don't know what a "checkout flow" is or why it matters. A Playwright script is a sequence of DOM instructions: find this element, click it, assert that value. The framework has no model of intent. It just executes steps.
This creates two hard problems. First, someone has to define every step. That someone is typically an engineer, writing test code that mirrors the production code they just wrote. Two codebases to maintain, both describing the same behavior. Second, when the application changes, the scripts don't know. They fail blindly. A button renamed from "Checkout" to "Complete Order" breaks every test that referenced the old label. The tests aren't wrong about what they were verifying. They're just brittle.
Generative AI changes both problems. Not by making it easier to write scripts, but by making scripts unnecessary. This is the approach Autonoma takes: instead of generating Playwright or Cypress code for you to maintain, the AI owns the tests entirely.
How Does Generative AI Read Your Codebase?
When we say AI reads your codebase, that phrase deserves unpacking. It's doing more than parsing files.
A large language model trained on code has learned the patterns of software: what a route handler does, what a React component renders, how an API endpoint relates to the UI that calls it. When it reads your codebase, it's not just indexing file names. It's building a model of your application's behavior from the code itself.
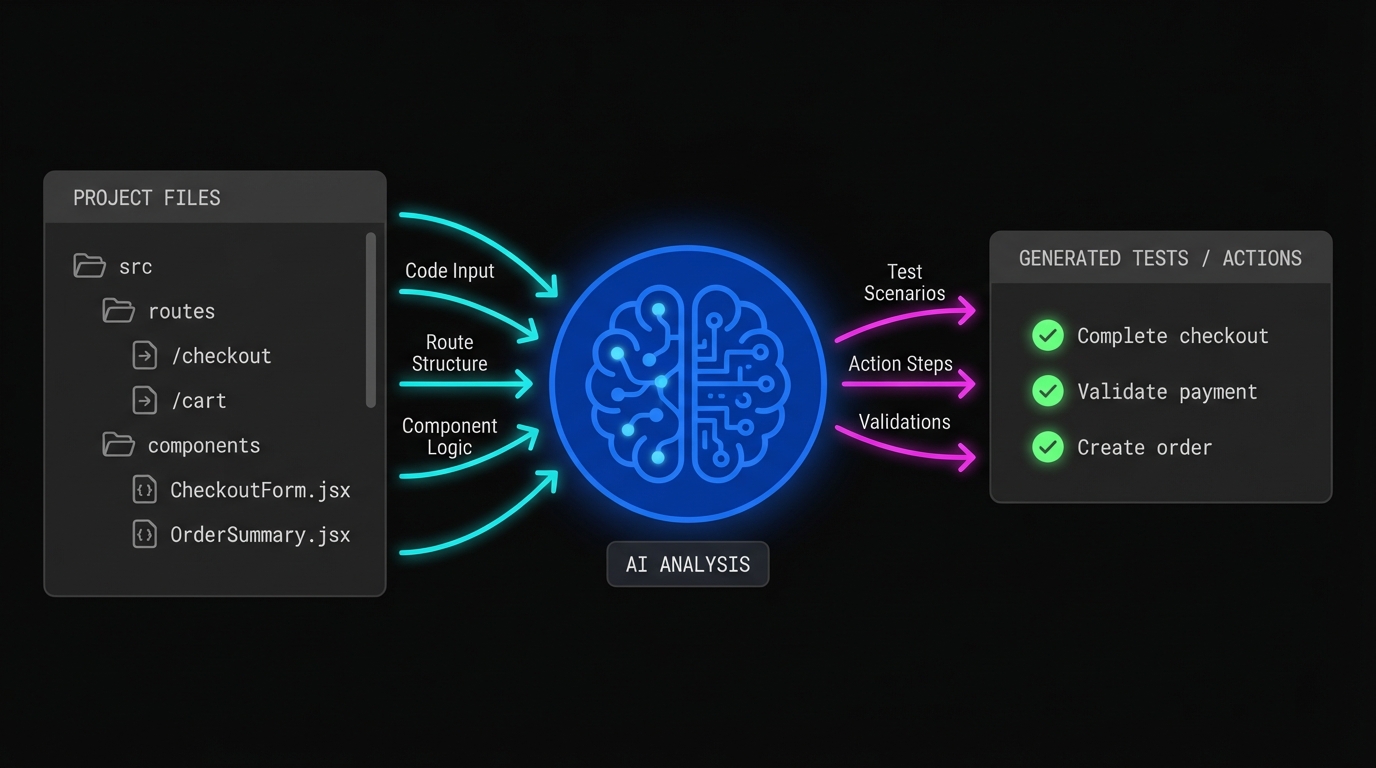
Consider a simple example. Your codebase has a route at /checkout, a CheckoutForm component that collects card details and a shipping address, and a POST /api/orders endpoint that the form submits to. A generative AI system reading that code can infer: there is a checkout flow, it requires a user to be authenticated, it accepts payment and address input, and it should result in an order being created. That's a test case, derived entirely from the code, without anyone describing it.
This is the core shift. Your codebase already contains the specification for what your application should do. Generative AI makes that specification readable to a testing system.
How Does AI Translate Code Understanding Into Test Cases?
Understanding the codebase is necessary but not sufficient. The harder problem is translating that understanding into tests that are reliable, complete, and maintainable.
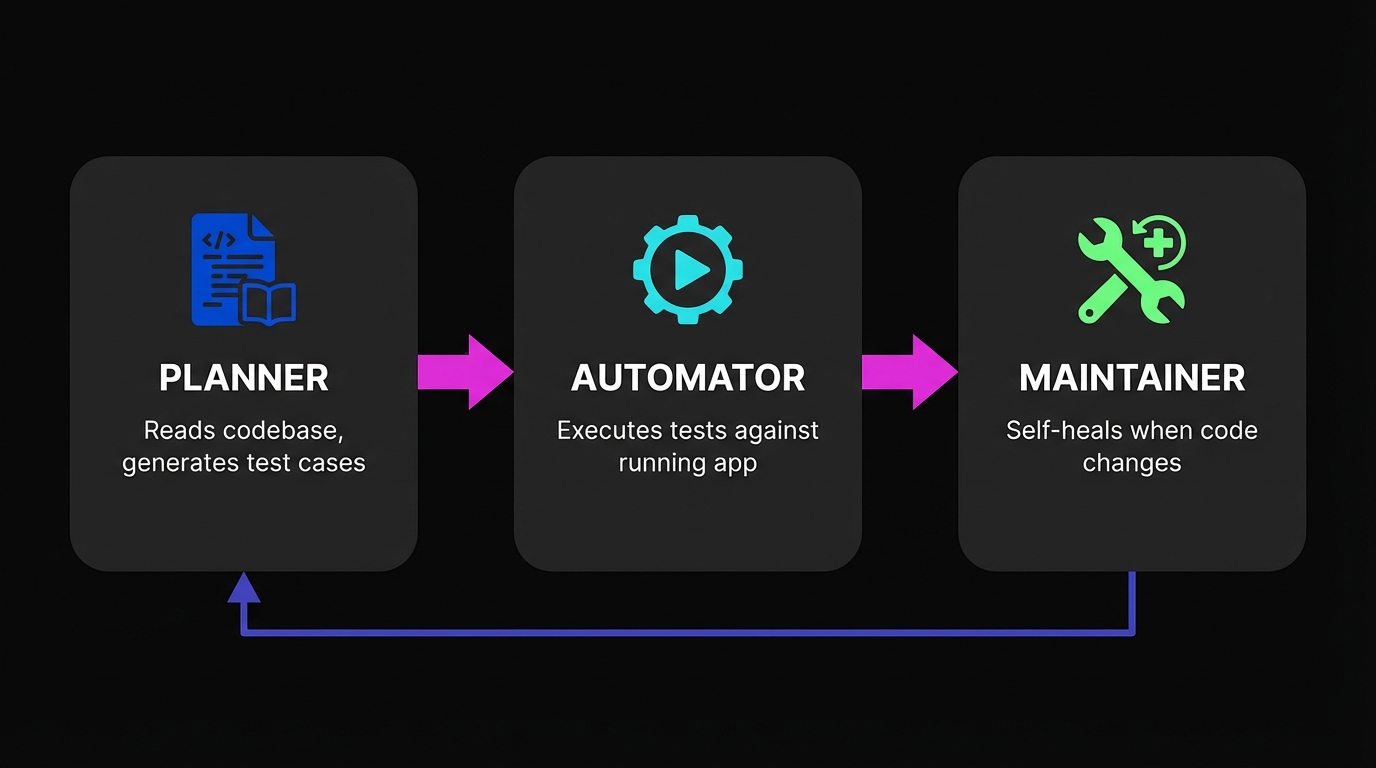
This is where the architecture matters. At Autonoma, a Planner agent does this translation. It reads routes, components, and user flows, then generates test cases that describe what to verify, not how to verify it. A test case isn't a script. It's a goal: "A user can add an item to cart and complete checkout using a valid credit card." The Automator agent receives that goal and figures out how to execute it against your running application.
The Planner also handles something that trips up most testing approaches: database state. Testing a checkout flow requires a user account, a product in the catalog, and valid payment credentials in a test environment. Historically, this setup was configuration work that engineers did manually: seeding databases, creating fixtures, writing before-hooks. The Planner generates the endpoints needed to put your database in the correct state for each test scenario automatically. No manual configuration.
How Does Generative AI Solve Test Maintenance?
Most discussions of AI in testing focus on test generation. That's the flashy part. The harder and more important problem is maintenance.
A test suite that generates quickly but breaks constantly isn't useful. It's just a different kind of work. This is why early "AI testing tools" often disappointed: they made the writing phase faster but didn't change the brittleness problem. You still had AI-generated scripts that failed every time someone renamed a CSS class. Autonoma was built specifically to solve this maintenance problem.
Generative AI solves maintenance differently because the system understands intent rather than selectors.

When a Playwright script encounters a button whose data-testid attribute changed from checkout-btn to complete-order-btn, it fails. The script doesn't know what a checkout button is. It only knows the attribute value it was told to find.
When Autonoma's Automator agent understands that it's trying to verify checkout completion, it looks at the page, identifies the button that initiates checkout based on its context and label, and clicks it. The attribute change is invisible to the goal. This is what self-healing actually means at a mechanical level: the system reasons about intent, not implementation.
Our Maintainer agent watches for code changes and re-evaluates tests that might be affected. It's not a selector-repair system. It's a re-evaluation of intent given updated application state. If a flow fundamentally changes, the agent surfaces that as a real failure worth investigating, not a selector error to ignore.
How Does Generative AI Testing Fit Into a Startup's Workflow?
The teams this matters most for are startups shipping fast with no dedicated QA function. Here's what the workflow looks like in practice.
You connect your codebase to Autonoma. The Planner agent reads your routes and components and generates test cases for your critical flows. The Automator executes those tests against your running application. Within a short period, you have coverage over checkout, authentication, your core feature paths, all without anyone writing a test script.
From that point, the workflow is largely passive. Tests run on each deploy. When something breaks, you get a failure report explaining what the agent verified, what it tried, and where it got stuck. When your UI changes, the Maintainer re-evaluates and heals tests that are affected by style or structural changes. When your flows change in a meaningful way (a new form field, a changed user journey), the Planner picks that up from the updated codebase and generates updated test cases.
No one on your team needs to write or maintain tests. The Planner derives them from your code. The Automator runs them. The Maintainer keeps them passing. This is the practical meaning of generative AI in software testing: not AI as a coding assistant, but AI as a complete testing system.
If you're building end-to-end testing for your startup, the generative approach eliminates the maintenance burden that kills scripted suites at small teams. Teams looking to shift testing left also benefit, since AI-generated tests keep pace with rapid iteration cycles.
For a broader view of where this sits in the landscape, our guide to AI for QA covers the full spectrum from AI-assisted scripting to fully autonomous approaches. And if you're weighing the cost of hiring a QA engineer versus using generative AI testing tools, the economics have shifted dramatically.
Generative AI Testing vs. AI-Assisted Testing: What Is the Difference?
These two things sound similar and are frequently confused. They're meaningfully different.

AI-assisted testing means using a language model (Claude, Copilot, Cursor) to help write test scripts. You describe what you want to test, the AI generates Playwright or Cypress code, you review it, paste it in, and run it. Faster than writing from scratch. You still own the script. When it breaks, you fix it.
We've looked at this approach directly. Our comparison of Cursor and Claude for E2E testing shows how the generated tests perform in practice. The tests work, but they inherit all the brittleness of hand-written scripts. Hard-coded selectors, text matching, timing assumptions. The AI reduced the writing time; it didn't change the maintenance burden.
Generative AI testing (the approach we're describing here) means the AI owns the full lifecycle. It generates tests from your code, executes them, interprets results, and adapts when things change. You don't write anything. You don't review generated scripts. You connect your codebase and the system takes over.
The distinction isn't about which AI model is smarter. It's about architecture. A coding assistant generates code for a human to own. A generative testing system generates behavior for itself to own.
How Do You Verify AI-Generated Tests Are Correct?
A fair objection to generative AI testing: if the AI is making decisions at every step, how do you know it's doing the right thing?
This is a real concern with poorly designed systems. An agent that wanders through your application taking random paths provides coverage of something, but you can't be sure what. Flaky results undermine confidence faster than no tests at all.
Well-designed generative testing systems address this through verification layers at each step. At Autonoma, the Planner produces structured test cases with explicit goals and preconditions. The Automator verifies after each action that the application reached the expected intermediate state before proceeding. Failure reports include the full trace of what the agent verified, what it tried, and what it observed. This is how you get consistent results rather than probabilistic wandering.
The agents don't take random paths. They pursue explicit goals with checkpoints, and they surface clear information when something genuinely goes wrong.
For a deeper look at how this architecture scales and what it looks like in enterprise contexts, see our piece on autonomous testing. And if you want to understand the fuller picture of what separates agentic testing from scripted automation, what is agentic testing covers that ground in detail.
Generative AI Testing Tools: What to Look For
If you're evaluating generative AI testing tools, the landscape is broader than it was a year ago, but the distinctions matter. Most tools marketed as "AI testing" fall into one of three categories.
AI coding assistants (Copilot, Cursor, Claude Code) help you write test scripts faster. You still own the scripts, maintain them, and fix them when they break. The AI is a productivity tool, not a testing system.
AI-enhanced testing platforms (Testim, mabl, certain modes of codeless test automation tools) add an AI layer on top of scripted frameworks. Self-healing selectors, smart element location, automatic waiting. These reduce maintenance but don't eliminate it. You still define every test manually.
Codebase-first generative testing (Autonoma) is where the AI reads your code and owns the full lifecycle. No human defines tests, writes scripts, or maintains anything. The system derives test cases from your codebase, executes them, and heals them when your code changes.
| Tool | Primary Capability | AI Feature | Best For | Pricing Model |
|---|---|---|---|---|
| Testim | AI-stabilized test automation | Smart element locators | Teams with existing scripts | Free tier + paid plans |
| Mabl | Low-code test automation | Auto-healing, visual testing | QA teams wanting less code | Usage-based subscription |
| Applitools | Visual AI testing | Visual regression detection | UI-heavy applications | Per-checkpoint pricing |
| Functionize | NLP-based test creation | Natural language to tests | Non-technical testers | Enterprise subscription |
| Katalon AI | Full-stack test platform | Self-healing, AI suggestions | Cross-platform testing | Free tier + enterprise |
| GitHub Copilot | AI code generation | Test script generation | Engineers writing tests faster | Per-seat subscription |
| Autonoma | Codebase-first autonomous testing | Full lifecycle AI agents | Startups with no QA team | Usage-based subscription |
The question to ask any tool: "Does the AI own the test lifecycle, or does it help me own it?" The first changes your team's relationship with testing. The second makes your current relationship slightly less painful.
What Should You Do Next?
If you're running a startup and your current approach to testing is "someone clicks through it before we deploy," generative AI testing is a direct replacement. Connect your codebase to Autonoma, get coverage over your critical flows, and stop clicking.
If you have an existing Playwright or Cypress suite that's become a maintenance burden, Autonoma can run alongside it while you evaluate whether it covers your flows reliably. Most teams find that within a few weeks, Autonoma's agent-based coverage is more complete and significantly less work than maintaining scripts.
If you're evaluating AI testing tools, the question to ask isn't "does it use AI?" Almost everything claims to. The question is: "does the AI own the test lifecycle, or does it just help humans write scripts?" The first changes your team's relationship with testing. The second doesn't.
Connect your codebase to Autonoma and agents plan, run, and maintain your tests from day one. No scripts to write, no selectors to maintain. Or book a demo to see it working on your specific application.
For more on what makes AI-powered testing different from traditional approaches, see our overview of AI-powered software testing.
Frequently Asked Questions
Generative AI in software testing means AI reads your codebase, understands what your application does, and generates test cases automatically. Rather than a human writing test scripts or recording flows, the AI derives tests from the code itself. It can then execute those tests, interpret results, and adapt when your application changes, all without any human involvement in the test creation or maintenance process. Autonoma is an example of this approach, using Planner, Automator, and Maintainer agents to handle the full testing lifecycle.
AI-assisted testing means using AI to help write test scripts (tools like Copilot or Cursor generating Playwright code) that a human then owns and maintains. Generative AI testing, like the approach Autonoma uses, means the AI owns the full test lifecycle: creating tests from your codebase, running them, healing them when code changes, and surfacing real failures. The human defines what application to test; the AI handles everything else.
No. With a codebase-first approach, the AI reads your routes, components, and user flows directly. Your code is the specification. The Planner agent derives test cases from what you've built, so no one needs to describe tests in natural language or click through the application to record flows.
This is one of the harder parts of test generation that codebase-first systems handle automatically. The Planner agent analyzes what state each test scenario requires (a logged-in user, a product in the catalog, a specific account condition) and generates the endpoints needed to put the database in the right state before each test. No manual fixture configuration required.
Traditional AI-generated scripts (like Playwright code from Copilot) break just like hand-written scripts because they rely on specific selectors and attributes. Generative AI systems that understand intent, rather than selectors, adapt when UI changes. When a button's label or CSS class changes, Autonoma's Automator finds the button through context and continues. The Maintainer agent also watches for code changes and re-evaluates affected tests proactively.
Generative AI testing is best for user flows, feature verification, and regression coverage. These are the end-to-end scenarios that matter most for shipping with confidence. Authentication flows, checkout, onboarding, core feature paths. Autonoma excels at these because its agents understand user intent rather than relying on brittle selectors. For narrow cases requiring exact behavioral contracts (precise string matching, pixel-level layout checks), deterministic tests give more control. Most teams use both: Autonoma for flows, unit or integration tests for strict business logic.
With Autonoma, your first tests are generated within minutes of connecting your codebase. The Planner agent reads your routes and components and produces test cases immediately. Most teams have their critical flows covered within a week of onboarding, without anyone writing a single test script.
Generative AI testing tools fall into three categories. AI coding assistants (Copilot, Cursor) help write test scripts faster but you still own maintenance. AI-enhanced platforms (Testim, mabl) add smart selectors to scripted frameworks. Codebase-first generative testing tools like Autonoma read your code and own the full test lifecycle: generating, executing, and self-healing tests without any human scripting. The key question when evaluating tools is whether the AI owns the test lifecycle or just helps you own it.



