
What is E2E testing for startups? It means covering only your three to five most critical user flows (checkout, signup, core activation) with automated tests that run on every deploy. Skip the UI-detail tests (they break constantly). Flaky tests are worse than no tests. For teams without dedicated QA, agentic testing tools that generate and maintain tests from your codebase eliminate the setup-and-maintenance burden that kills scripted suites at small teams.
A three-person team shipping daily cannot afford the same testing strategy as a 200-person engineering org with a dedicated QA function. Most of the advice online was written for the wrong team. This playbook is written for yours.
Why Most E2E Testing Advice Fails Small Teams
Search "end-to-end testing" and you get guides written for teams with QA engineers, CI pipelines already in place, and time to maintain 500-test suites. The advice is technically correct and practically useless for a team of six building a SaaS product.
The real question isn't "how do I set up E2E testing?" It's "given that I have two engineers, no dedicated QA, and we ship three times a week, what's the minimum viable testing strategy that actually protects us?"
That question has a real answer. This is it.
What E2E Testing Actually Means (and What It Doesn't)
End-to-end testing is the practice of testing an application's complete workflow — from the user interface through APIs, databases, and third-party integrations — to verify that the entire system behaves as expected.
End-to-end testing verifies that a user can complete a workflow from start to finish in your actual application. Not a unit of code. Not an API contract. A real user flow: sign up, add a product, check out, receive a confirmation email.
The word "end-to-end" matters. You're testing the seams between systems: the frontend talking to the backend, the backend talking to the database, the email service firing correctly. These seams are where production bugs actually live. Unit tests can pass completely while your checkout flow is broken because a third-party payment API changed its response format.
This is different from integration testing, which verifies that two systems talk to each other correctly. E2E testing verifies that a human goal can be achieved through those systems. The distinction matters when you're deciding what to write. For a deeper primer on the fundamentals, see our complete end-to-end testing guide.
What E2E testing is not: a replacement for unit tests on complex business logic, a substitute for monitoring in production, or a tool for catching every possible edge case. At a startup, you need E2E coverage on your most critical flows and unit tests on your most complex calculations. Everything else is optional.
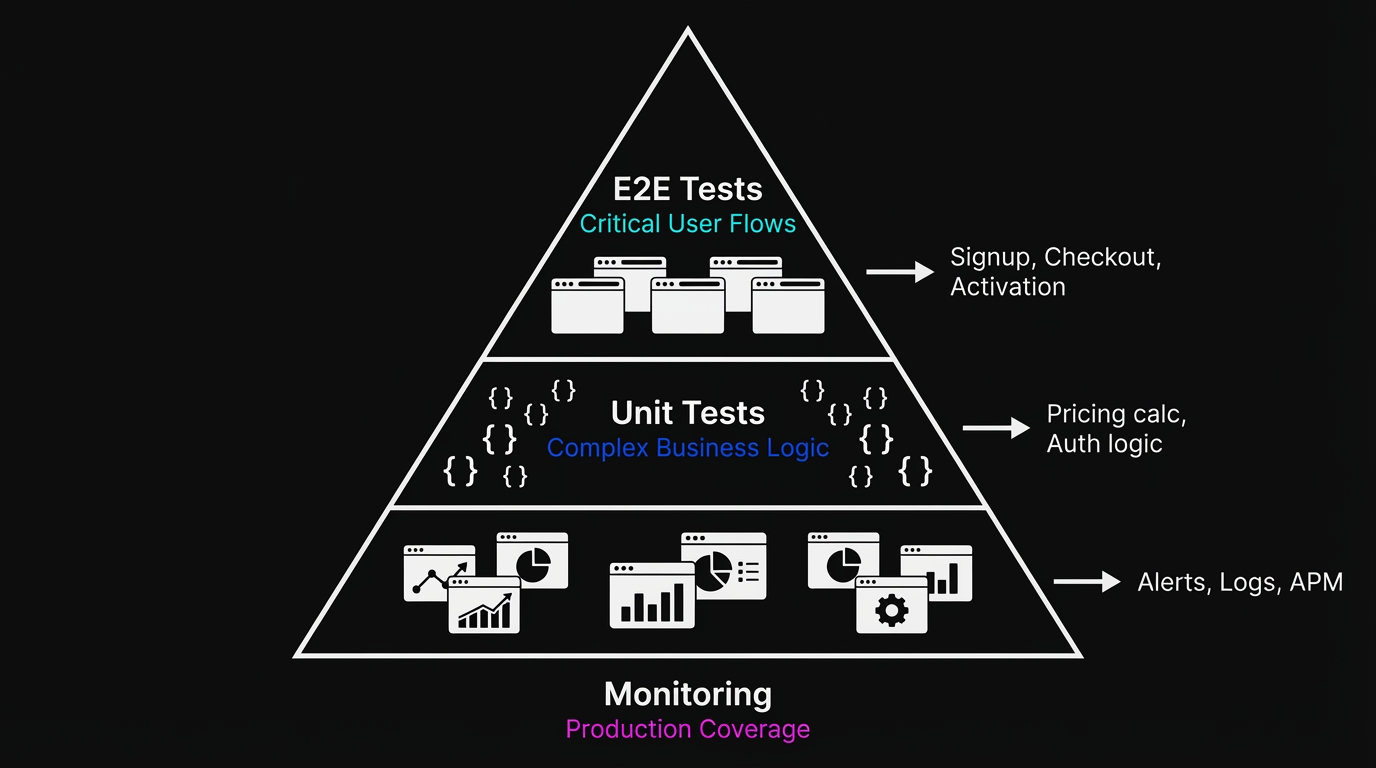
Which User Flows to E2E Test First at a Startup
Most startup teams make the same mistake: they try to test everything and end up testing nothing. A 200-test suite that nobody runs is worse than ten tests that run on every deploy.
Here's the prioritization framework we've seen work consistently across the startups we work with at Autonoma.
Your money flow is non-negotiable. If your product takes payments, your checkout, subscription creation, and upgrade path must be E2E tested. A broken checkout is not a bug you discover in standup. You discover it when revenue stops appearing in Stripe. This is the flow that gets tested first, every time, no exceptions.
Your core activation flow is next. What does a new user do in the first ten minutes? Sign up, verify email, create their first project, invite a teammate? Whatever that sequence is, it needs an E2E test. Acquisition is expensive. Breaking the activation flow means you're paying to acquire users and then failing to convert them, silently, until someone checks the analytics.
Your most-changed feature is third. Every product has one part that gets touched constantly: a dashboard being rebuilt, a settings page being redesigned, a new onboarding flow being iterated on. That's where regressions happen. Put a test there.
Everything else can wait. Your admin panel can be clicked through manually. Your reporting features can skip automated E2E coverage until you have the bandwidth. The goal is a small suite that runs fast, breaks rarely, and catches the things that hurt most when they break.

If you want those three tests running without writing scripts or managing selectors, Autonoma reads your codebase and generates E2E coverage for these critical flows automatically — so you get the protection without the setup time.
The Hidden Cost of E2E Test Maintenance
You set up Playwright. You write fifteen tests. They all pass. You feel good.
Three weeks later, your designer ships a new component library. Button classes changed, form labels updated, a modal was refactored. CI turns red. Twelve of your fifteen tests fail. Not because anything is broken, but because Playwright is trying to click elements that don't exist anymore.
You spend half a sprint fixing selectors. You push. Green. The next iteration of the design system goes out two weeks later. Six more fail. Someone on the team starts skipping the test run before deploy because it's faster to check manually.
This is the hidden cost of E2E testing for small teams: maintenance. A scripted test suite compounds in maintenance debt every time your product gets better. That problem compounds when you shift testing left without the tooling to support it. For a large QA org, that maintenance is manageable (it's someone's job). For a three-person team, it consumes a meaningful fraction of your engineering bandwidth. If you're weighing whether to hire a QA engineer to handle this, the calculus changes when you consider self-maintaining alternatives.
This is exactly why the choice of tool matters more for small teams than for large ones. If you're evaluating what framework to use, the question isn't just "which framework has the best API" but "how much ongoing maintenance does this require from engineers who have other jobs to do." Our guide to choosing the right e2e testing tools breaks down that decision in detail.
The maintenance problem has two solutions. You can invest in writing tests that are less brittle (better selectors, more resilient assertions, proper waiting strategies). Or you can use a tool where maintenance happens automatically.
How to Write E2E Tests That Don't Break Constantly
If you go the scripted route with Playwright or Cypress, the single most important thing you can do is write resilient selectors. Most tests break not because flows changed but because the HTML changed.
The selector hierarchy that actually holds up over time: data attributes first, semantic roles second, text content third, CSS classes last.
// Fragile - breaks when CSS classes change
await page.click('.btn-primary.checkout-submit')
// Better - semantic role with text
await page.getByRole('button', { name: 'Complete Purchase' })
// Best - explicit test attribute, unaffected by any UI change
await page.getByTestId('checkout-submit-btn')Adding data-testid attributes to your components takes ten minutes and makes your tests ten times more durable. It's the highest-ROI thing a small team can do if they're going the scripted route.
Beyond selectors, flakiness is your other enemy. A test that passes 70% of the time is useless. You can't trust it, so you ignore it, so it might as well not exist. The 2025 State of Testing Report (the most recent available) found that flaky tests are the number one frustration for testing teams. The usual culprit is timing: tests that click before the page is ready, or assert before data has loaded.
// Flaky - assumes the page has rendered
await page.click('#submit')
await expect(page.locator('.confirmation')).toBeVisible()
// Reliable - waits for the action's result explicitly
await page.click('#submit')
await page.waitForURL('/confirmation')
await expect(page.getByText('Order confirmed')).toBeVisible()The principle is simple: never assert immediately after an action. Always wait for the state you're asserting to be reachable. Playwright's built-in auto-waiting handles most of this, but complex flows (API calls, redirects, background jobs) still need explicit waits.
Agentic testing tools like Autonoma sidestep this problem entirely. Because agents interact with your application the way a real user would, they wait for the page to actually be ready before taking the next action. There are no hardcoded waits or timing assumptions to get wrong. The agent observes the real page state and proceeds when the UI is stable, which eliminates the most common source of flakiness in scripted suites.
Setting Up E2E Tests in CI Without Over-Engineering It
A test suite that only runs locally is not a test suite. It's a script you occasionally remember to run. The value of E2E testing comes from automatic execution on every deploy.
For most startups, the simplest setup that works: run E2E tests on every pull request against a preview environment, and block merges when they fail. That's it. No elaborate parallelization, no test sharding, no dedicated test infrastructure. Just a GitHub Actions job that runs your suite against your staging URL.
# .github/workflows/e2e.yml
name: E2E Tests
on:
pull_request:
branches: [main]
jobs:
e2e:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: '20'
- run: npm ci
- run: npx playwright install --with-deps chromium
- run: npx playwright test
env:
BASE_URL: ${{ secrets.STAGING_URL }}One browser (Chromium) is enough to start. You can add Firefox and Safari later if cross-browser coverage matters for your users. Starting with one browser means faster runs and less infrastructure to maintain.
If your suite runs in under two minutes, keep it sequential. Parallelization adds complexity. The time you spend configuring workers is usually better spent writing tests that actually matter.
The Database State Problem (And How to Solve It)
The hardest part of E2E testing that nobody warns you about: your tests need data to work with. Your checkout test needs a product in the cart. Your dashboard test needs a user with existing data. Your upgrade test needs a user on a free plan.
Scripted E2E tests typically handle this through fixtures (seed data loaded before tests run) or through the UI itself (the test creates the data by clicking through the creation flow). Both approaches have failure modes.
Fixtures get stale. As your schema evolves, fixture files become incorrect. Tests start failing for reasons unrelated to your features. Maintaining fixtures becomes a job.
Creating data through the UI is slow and fragile. A test that spends thirty seconds creating a project before it can test the feature that uses projects is a test that fails whenever the project creation flow has a bug, even if the feature you're actually testing is fine.
The cleanest solution for small teams: a dedicated seed endpoint that puts your database in a known state for a given test scenario. One API call before each test that creates exactly the data needed. It's fast, explicit, and doesn't depend on other flows being working.
// Before each test, seed the state you need
test.beforeEach(async ({ request }) => {
await request.post('/api/test/seed', {
data: {
scenario: 'user-with-active-subscription',
userId: TEST_USER_ID
}
})
})
// Now your test starts from a known state
test('user can upgrade plan', async ({ page }) => {
await page.goto('/settings/billing')
// test the actual thing you care about
})This is a backend engineering task. Your team needs to build and maintain these seed endpoints, but it pays for itself immediately in test reliability.
If you use Autonoma, the Planner agent handles this automatically. It reads your schema and test scenarios, then generates the seed endpoints needed to put your database in the right state for each test. That removes one of the more tedious pieces of E2E test setup for small teams. We've written a detailed guide on data seeding for E2E tests that covers this topic in depth.
Scripted vs. Agentic E2E Testing: The Honest Tradeoff
There are now two meaningfully different approaches to E2E testing for startups: scripted automation and agentic testing. Understanding how generative AI is changing software testing helps explain why the gap between these approaches is widening.
Scripted automation (Playwright, Cypress, and their alternatives) gives you full control and predictability. You write exactly what you want tested. The tradeoff is maintenance: every UI change that touches a tested flow requires someone to update the tests. For a team shipping fast, this cost is real and recurring.

Agentic testing is the newer approach. Rather than writing test scripts, you connect your codebase and agents read your code (routes, components, user flows) and generate test cases automatically. When your UI changes, the tests adapt without human intervention. There's no script to update because there's no script; there's an agent that understands intent.
The honest assessment: scripted testing works well if your UI is relatively stable and you have an engineer who owns test maintenance. It struggles when your team is shipping fast and nobody has time to babysit the suite.
At Autonoma, we built the agentic approach specifically for teams who don't have a dedicated QA function. Connect your codebase, agents plan tests from your code, execute them, and self-heal when things change. No test scripts to write, no selectors to maintain, no fixtures to keep current. The Planner agent also handles database state setup automatically, generating the endpoints needed to put your DB in the right state for each test scenario.
The teams we see switch to agentic testing are typically the ones who tried scripted automation, invested real time in it, and then watched the suite slowly become a liability as the product evolved. If you haven't started yet, you can skip that phase entirely. For a broader look at how AI is reshaping QA beyond just test maintenance, see our guide to autonomous testing.
E2E Testing Tools for Small Teams
Choosing the right tool matters more for small teams than for large ones, because the maintenance burden falls on engineers who have other jobs to do. Here's how the most common options compare.
| Tool | Open Source | Language Support | Best For | Learning Curve |
|---|---|---|---|---|
| Cypress | Yes | JavaScript, TypeScript | JavaScript-heavy teams wanting a smooth DX | Low |
| Playwright | Yes | JS/TS, Python, Java, .NET | Cross-browser testing with strong auto-waiting | Low-Medium |
| Selenium | Yes | Java, Python, C#, Ruby, JS | Legacy suites and broad language support | Medium-High |
| TestCafe | Yes | JavaScript, TypeScript | Teams that want no WebDriver dependency | Low |
| Autonoma | No (SaaS) | Any (reads your codebase) | Teams with no QA who need zero-maintenance E2E | Minimal |
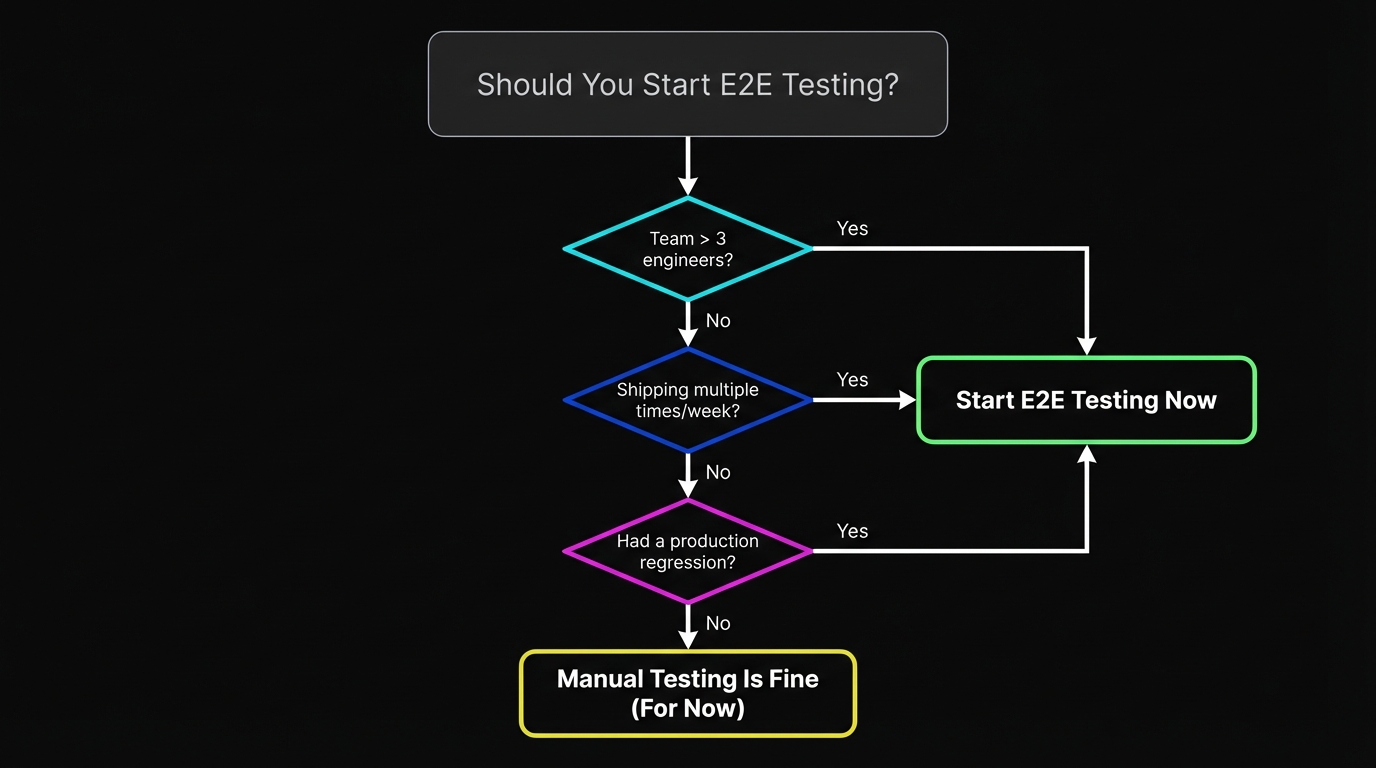
When Should a Startup Start E2E Testing?
The most common question from early-stage founders: "When do we actually need E2E testing?"
The honest answer: earlier than you think, but not from day one.
Day one through launch, manual testing is fine. You're iterating so fast that tests would be outdated before they ran. Your team knows the product intimately. The surface area is small.
The inflection point is when manual testing stops being sufficient. That usually happens when: your team grows past three engineers (more than one person can change things independently), you start shipping multiple times per day, or you've had a production incident that manual testing didn't catch. Any one of those is a signal.
A useful heuristic: if your pre-deploy smoke test takes more than ten minutes of clicking, you need automated E2E coverage. If you've ever discovered a broken checkout in production, you needed it yesterday.
How Many E2E Tests You Need at Each Stage
For a team of two to four: three tests. Signup flow, core action (create a project / send a first message / add a product), and checkout if you take payments. Run them on every PR. Takes thirty minutes to set up with Autonoma or Playwright.
For a team of five to ten: your three critical flows plus the two or three features you're actively iterating on. Add a test when you fix a bug that came from a regression. Keep the suite under ten minutes.
For a team of ten to twenty: start thinking about test ownership. Assign E2E coverage to feature areas. Consider whether your maintenance burden is becoming an engineering tax. If it is, this is when teams typically evaluate agentic approaches. The ROI becomes very clear when test maintenance is consuming sprint capacity.
At every stage, the rule is the same: a small, reliable suite beats a large, ignored one. Delete tests that are consistently flaky. Don't add tests that take more than ten minutes to stabilize. Treat your test suite like production code, not like a backlog.
Getting Started With E2E Testing This Week
If you're starting from scratch, the fastest path to meaningful E2E coverage:
- Pick your most critical flow (almost certainly checkout or activation).
- Write one test for the happy path.
- Get it running in CI.
- Declare victory and ship.
From there, add one test per sprint for the flow that broke most recently. After six sprints, you have coverage on your six most fragile paths. That's a more useful suite than most startups have.
If you'd rather not write scripts at all, connect your codebase to Autonoma and let agents generate your initial coverage. The Planner agent reads your routes and components, identifies your critical flows, and generates test cases automatically. Your first tests are running within minutes of connecting your repo.
Either way, the goal is the same: coverage on the things that break in production, running automatically before every deploy, maintained with minimal engineering time. Everything else is optimization.
Book a demo if you want to see how Autonoma works on your specific application, or start with our documentation to understand what agents generate from your codebase.
Frequently Asked Questions
End-to-end testing for startups means verifying that your most critical user flows work correctly from the user's perspective: signup, checkout, core feature activation. Unlike enterprise E2E testing that aims for comprehensive coverage, startup E2E testing is about ruthless prioritization: cover the three to five flows that hurt most when they break, run them automatically on every deploy, and keep the suite small enough that it actually gets maintained. For teams without QA bandwidth, agentic tools like Autonoma can generate and maintain that coverage directly from your codebase.
Yes, once you reach the inflection point where manual testing doesn't scale. That's usually when your team grows past three engineers, you're shipping multiple times per day, or you've had a production incident that manual testing missed. Before that point, manual smoke tests are often sufficient. After it, you need automation. The question is which approach fits your team's bandwidth. Agentic tools like Autonoma offer a low-maintenance path, since agents generate and update tests as your product evolves, so you get coverage without the ongoing upkeep of a scripted suite.
It depends on whether you can own test maintenance. For teams that don't have bandwidth to maintain scripts as the UI evolves, Autonoma generates and maintains tests from your codebase automatically, with no scripts to write or update. If you prefer the scripted route, Playwright is the strongest option: fast, reliable, great TypeScript support, built-in auto-waiting. Cypress is a close second with a better developer experience for JavaScript teams.
Far fewer than you think. Three to five tests covering your critical flows (checkout, activation, core feature) get you most of the value. A suite of ten tests that runs reliably on every PR is worth more than a suite of 200 tests that nobody maintains. Start small, add tests when you fix regressions, and delete tests that are consistently flaky. If you use Autonoma, agents can generate your initial coverage automatically by reading your routes and components, giving you a solid starting suite without the manual effort.
The cleanest approach is seed endpoints: API routes your tests call before each run to put the database in a known state for a given scenario. This is faster and more reliable than creating data through the UI and more maintainable than fixture files that go stale. If you use Autonoma, the Planner agent handles database state setup automatically, generating the endpoints needed to put your DB in the right state for each test scenario.
Integration testing verifies that two systems communicate correctly (your API talks to your database correctly). E2E testing verifies that a user can achieve a goal through your full system (a user can sign up, create a project, and invite a teammate). E2E tests are broader and slower but catch a different class of bugs, specifically the ones at the seams between systems that unit and integration tests can't see. For a deeper comparison, see our guide on integration testing vs E2E testing.
Flakiness almost always comes from timing issues and fragile selectors. Use data-testid attributes instead of CSS classes. Replace hard waits (sleep 1000ms) with explicit waits for state (waitForURL, waitForSelector). Assert on the result of an action, not immediately after triggering it. If a test is consistently flaky, delete it. A flaky test is worse than no test because you start ignoring it. Alternatively, Autonoma's agentic approach eliminates selector-based flakiness entirely, since agents observe the real page state rather than relying on brittle CSS selectors or hardcoded waits. For a deeper guide, see our article on [reducing test flakiness](/blog/reduce-test-flakiness-best-practices).
For most startups with fewer than 20 engineers shipping web or mobile products, automated E2E testing covers your functional needs at a fraction of the cost. A QA engineer costs $150K-$200K+ per year all-in, while AI-powered testing tools run $200-$500/month. Hire when you have compliance mandates, hardware testing needs, or a genuinely large codebase where strategy requires dedicated attention. For a complete decision framework, see our guide on [whether to hire a QA engineer](/blog/hire-qa-engineer).
The three tools worth evaluating depend on your team's approach. Autonoma is best for teams that want coverage without maintaining scripts, since agents generate and update tests from your codebase automatically. Playwright is the strongest scripted framework: fast execution, TypeScript-native, excellent auto-waiting, and a thriving ecosystem. Cypress offers a smoother developer experience with its interactive test runner, which makes it a good fit for JavaScript-heavy teams. For a detailed comparison of scripted frameworks, see our guide on test automation frameworks.



