
The AI coding boom has a blind spot. AI coding agents like Cursor, GitHub Copilot, and Claude Code generate code at 10x the speed of manual development, but testing has not kept pace. Most teams still rely on human review, manual QA, or skipping tests entirely. The result is a growing gap between the volume of code being generated and the volume of code being verified. The only sustainable solution is symmetry: an AI testing agent that autonomously generates and maintains tests at the same speed code is being written. Autonoma is built for exactly this, an agentic testing platform that accesses your codebase and develops your test suite to keep pace with your AI coding agents.
Your AI coding agent just wrote 2,000 lines of code in an afternoon. The pull request is sitting there, green checkmark from the linter, ready to merge. One question: who tested it? According to CodeRabbit's State of AI vs. Human Code Generation Report, AI-generated pull requests contain 1.7x more issues than human-written ones and 1.4x more critical bugs. The code is flowing faster than ever. The verification is not keeping up.
The AI Coding Agent's 10x Problem Nobody Wants to Talk About
The AI coding agent has become the default tool for professional software development. Cursor, GitHub Copilot, Claude Code, Windsurf, Devin. By the end of 2025, roughly 85% of developers were regularly using AI tools for coding, and the market hit $4 billion. The tooling is excellent, improving monthly, and genuinely transforming how fast teams ship. According to GitHub's own research, developers using Copilot complete tasks 55% faster. Internal reports from teams using Cursor and Claude Code suggest even higher multipliers for certain categories of work.
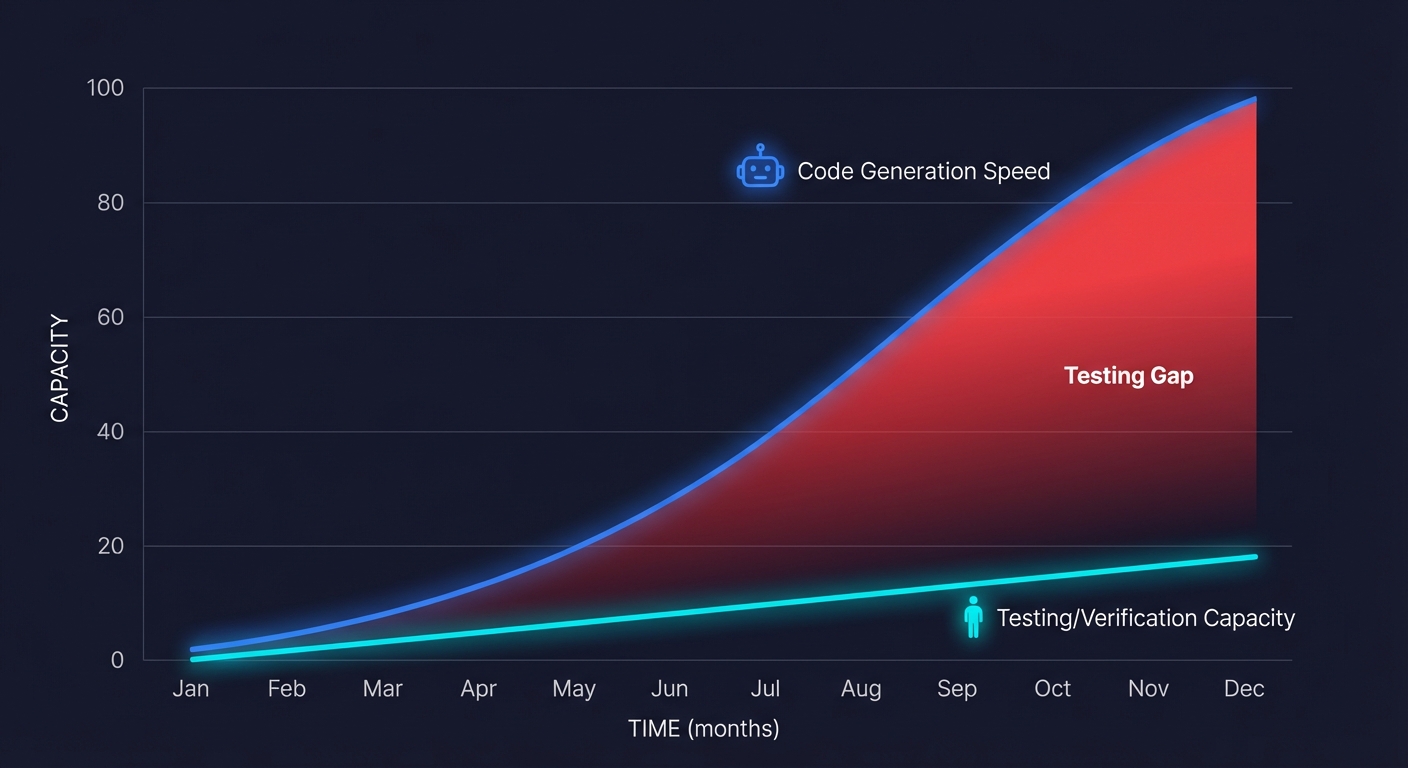
Here is what those numbers do not capture: the testing burden scales with the code output. When a single developer could write 200 lines of production code in a day, the testing surface was manageable. A senior engineer could review the changes, write a few unit tests, maybe run through the critical path manually. The ratio of code-to-verification was roughly 1:1 in terms of human attention.
Now that same developer, augmented by an AI coding agent, generates 2,000 lines in a day. The testing surface grew 10x. The human capacity to verify it did not. Something has to give, and what gives is quality. Not because anyone decided to skip testing, but because the math stopped working.
This is not a hypothetical. Talk to any engineering leader running a team of 5 to 20 developers who adopted AI coding tools in the last 12 months. Ask them about their test coverage trend. Ask them about the ratio of production incidents before and after they started using AI to write code. The pattern is consistent: velocity went up, and so did the bug rate. We mapped this pattern in detail in our analysis of the vibe coding testing gap, including a severity scale for assessing where your team sits.
Why Human Review Cannot Keep Up
Code review was never designed to be a testing methodology. It was designed to be a knowledge-sharing and design-quality mechanism. A good code review catches architectural issues, naming problems, and logical errors that are visible at the statement level. It was never meant to verify that a complex multi-step user flow still works after a refactor.
But in the absence of automated testing, code review has quietly become the last line of defense. And AI-generated code makes this defense even weaker for three specific reasons.
Volume saturation. A reviewer who can thoughtfully review 400 lines of code in an hour is now staring at 2,000-line pull requests generated in a single session. The quality of review degrades as volume increases. This is not a discipline problem. It is a cognitive load problem. Research on code review effectiveness consistently shows that review quality drops sharply after 200 to 400 lines.
Coherence gaps. AI coding agents are excellent at generating locally correct code. A function that does what its docstring says. An API endpoint that handles the specified request shape. But the agent does not always maintain awareness of the broader system state. It might rename a field in one file and miss the three other files that reference it. It might add an endpoint that conflicts with an existing route. These cross-cutting issues are exactly what human reviewers are worst at catching in large diffs.
Familiarity bias. When a human writes code, the reviewer can ask "why did you do it this way?" and get a reasoning chain. When an AI writes code, the developer who prompted it often does not fully understand every decision the agent made. They are reviewing code they did not write and may not fully comprehend, which means they default to "it looks reasonable" instead of "I verified this is correct."
The result is that AI-generated code passes through code review with less scrutiny than human-written code, despite needing more scrutiny because of its higher volume and lower transparency.
The Testing Gap Is a Systemic Risk
Let me quantify what this looks like at a typical Series A company running a 10-person engineering team.
Before AI coding tools: the team writes roughly 5,000 lines of production code per week. They have a test suite that covers about 60% of their critical paths. A senior engineer spends about 4 hours a week maintaining tests. The production incident rate is about 1.5 per week.
After adopting an AI coding agent: the team writes roughly 20,000 lines of production code per week. The test suite still covers the same 60%, but the codebase is changing so fast that tests break more frequently. The senior engineer now spends 8 hours a week on test maintenance, and the coverage is actually declining because new code is being added faster than new tests. The production incident rate climbs to 3 to 4 per week.
The team is shipping 4x more features. They are also shipping 2x more bugs. And the engineer who should be working on the product is spending two full days a week just keeping the test suite from rotting. This is the testing gap, and it is not a tooling problem. It is an asymmetry problem. The code-generation side of the workflow has been supercharged by AI. The code-verification side is still running on human power. The Cortex 2026 Engineering Benchmark quantified the scale: pull requests per engineer climbed 20% year-over-year while incidents per pull request rose 23.5% and change failure rates increased roughly 30%.
The data backs this up. In a 2025 Harness survey, 72% of organizations reported at least one production incident caused by AI-generated code, 59% said they experience deployment problems at least half the time when using AI coding tools, and 67% said they spend more time debugging AI-generated code than they did before adopting it. The gap is not anecdotal. It is measurable.
The Security Blind Spot Inside the Testing Blind Spot
The quality gap is bad enough. The security gap is worse. CodeRabbit's analysis found that AI-generated code is 2.74x more likely to introduce cross-site scripting (XSS) vulnerabilities, 1.91x more likely to create insecure object references, and 1.88x more likely to implement improper password handling compared to human-written code. AI-generated code frequently omits null checks, input validation, and exception handling, the kinds of defensive patterns that prevent real-world outages and breaches.
This matters because AI coding agents do not reason about security the way experienced developers do. They optimize for functional correctness: does this code do what the prompt asked? They do not spontaneously add rate limiting, parameterized queries, or authentication guards unless the prompt specifically requests them. The result is code that works but is vulnerable, and those vulnerabilities are invisible to functional testing.
A comprehensive testing strategy for AI-generated code must cover both functional correctness and security hygiene. An AI testing agent that understands your application's authentication model, data flow, and API surface can test for the security gaps that coding agents systematically introduce.
Why "Just Write More Tests" Is Not the Answer
The obvious response is: use the same AI coding agent to write the tests. Prompt Cursor to generate unit tests. Ask Copilot to write integration tests for the code it just produced. This sounds logical. In practice, it does not solve the problem, and understanding why is critical.
AI-generated tests verify the implementation, not the intent. When you ask an AI coding agent to write tests for the code it just wrote, the tests are derived from the code, not from the specification. If the code has a subtle bug, the tests will pass because they test what the code does, not what the code should do. This is the equivalent of grading your own homework. The tests and the code share the same blind spots.
Generated unit tests create a false sense of coverage. An AI can generate 50 unit tests in seconds. They will all pass. They will boost your coverage metric. But they test individual functions in isolation, which means they structurally cannot catch the integration failures, state management bugs, and cross-service regressions that cause production incidents. Your coverage number goes up while your actual protection stays flat. For why this matters, see our analysis of the testing pyramid's false confidence problem.
Test maintenance is the real cost, and it stays manual. Generating tests once is the easy part. The hard part is maintaining them as the codebase evolves. When a refactor changes the internal structure of a module, 30 unit tests break. Someone (a human) has to figure out which test failures represent real regressions and which are just stale tests. This triage cost is proportional to the number of tests, and if an AI coding agent is generating hundreds of tests, the triage burden can exceed the time saved by generating the code in the first place.
This is not an argument against AI coding agents. It is an argument that the testing side of the equation needs its own AI agent, one that operates independently from the code generation, understands the application at the behavioral level, and maintains itself.
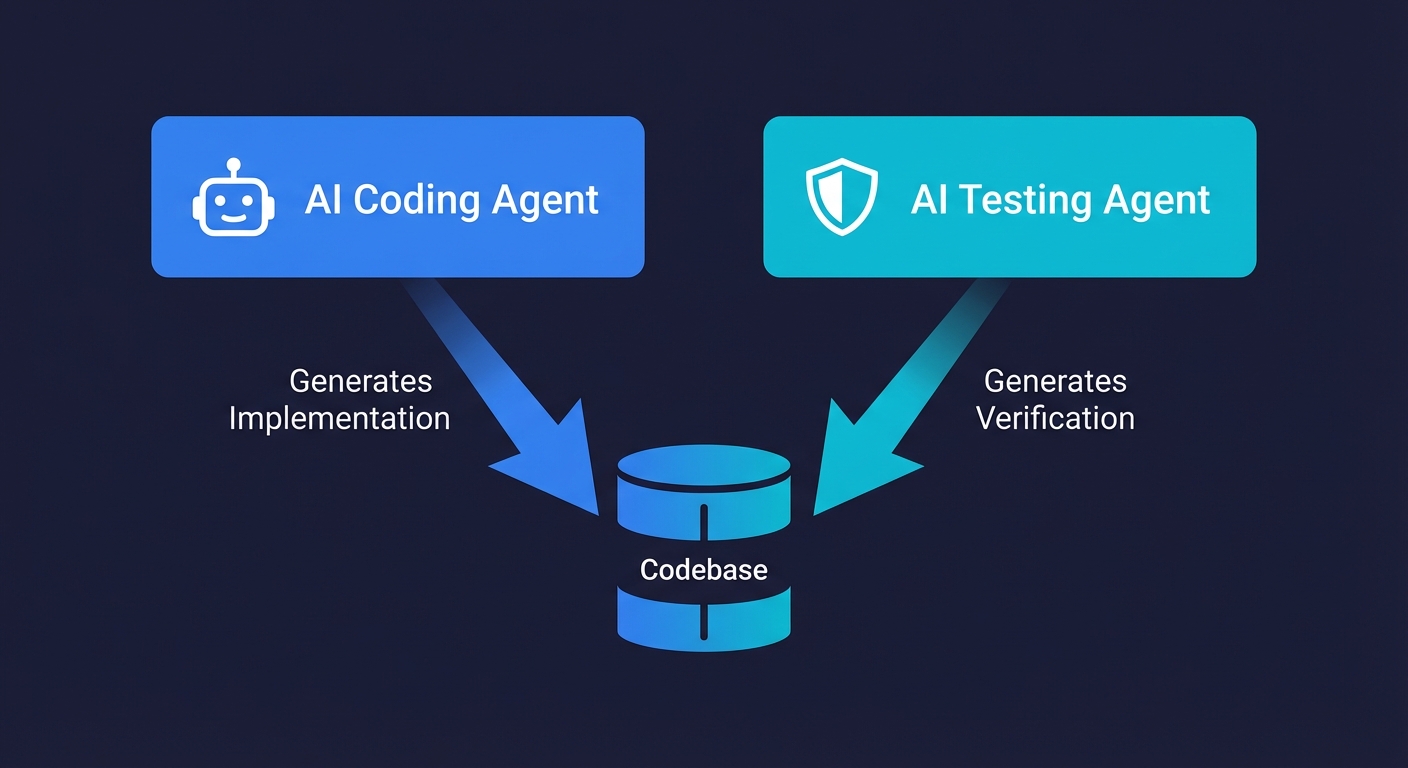
The Symmetry Argument: Code Agent Meets Test Agent
Think about the structure of the problem. You have an AI agent that reads your codebase, understands the patterns and architecture, and generates new code that fits into the existing system. It operates at the level of code: functions, modules, APIs. It is very good at this.
Now consider what testing requires. An agent that reads your codebase, understands the user flows and critical paths, and generates tests that verify the system works end-to-end. It operates at the level of behavior: what the user does, what the system should do in response, and whether it actually does it.
These are symmetric problems. The code agent generates implementation. The test agent generates verification. They access the same codebase but reason about it from different angles. The code agent asks "how should this feature work?" The test agent asks "does this feature actually work?"
This is why the solution to testing AI-generated code is not "use the same AI to write tests." The solution is a dedicated AI testing agent that approaches the codebase from the verification perspective, not the implementation perspective. One that understands your application's routes, components, API endpoints, and database schemas, and autonomously generates end-to-end tests that verify the user experience, not just the function signatures.
The difference between asking your coding agent to write tests and deploying a dedicated testing agent is the difference between asking the author to proofread their own manuscript and hiring an independent editor. Both involve reading the same text. One of them can actually find the problems.
What an AI Testing Agent Actually Does
The term "AI testing" covers a wide spectrum, from test case generators that output JUnit templates to fully autonomous agents that plan, write, execute, and maintain test suites. The distinction matters because only the latter solves the testing gap created by AI coding agents.
A genuine agentic testing platform works like this:
It accesses your codebase directly. Not screenshots, not recordings of mouse clicks. The agent reads your source code: routes, components, state management, API contracts, database schemas. It builds a model of how your application actually works at the code level.
It reasons about user flows, not functions. Instead of testing calculateTotal() in isolation, it tests "a user adds items to cart, proceeds to checkout, enters payment details, and sees a confirmation page." This behavioral-level testing is what catches the integration failures that unit tests miss.
It generates real, executable test code. Not pseudo-code suggestions. Not natural language descriptions. Production-quality test scripts that run in your CI pipeline, use your actual selectors and API endpoints, and produce clear pass/fail signals.
It maintains itself. When your codebase changes (and it changes constantly when you are using an AI coding agent), the testing agent detects what changed, evaluates whether existing tests need updating, and updates them. No human triage. No "test.skip()" accumulating in your repo. The maintenance cost that kills traditional test suites is handled by the agent.
This is what Autonoma does. It connects to your repository, reads your codebase, and autonomously develops and maintains your end-to-end test suite. When your AI coding agent pushes a refactor, Autonoma detects the changes and adapts the tests. The two agents work in parallel: one generating code, the other verifying it. The asymmetry closes.
The Real-World Math: With and Without a Test Agent
Let me walk through the economics for a concrete scenario. A 10-person engineering team building a B2B SaaS product. They ship to production daily. They use Cursor or Claude Code for code generation.
Without an AI testing agent:
| Metric | Before AI Coding | After AI Coding (no test agent) |
|---|---|---|
| Lines of code per week | 5,000 | 20,000 |
| Production incidents per week | 1.5 | 3-4 |
| Engineering hours on test maintenance | 4 hrs/week | 8-12 hrs/week |
| E2E test coverage of critical paths | 60% | 45% (declining) |
| Time from code generation to deploy | 2 days | 2 days (bottlenecked on review) |
With an AI testing agent (Autonoma):
| Metric | After AI Coding + Test Agent |
|---|---|
| Lines of code per week | 20,000 |
| Production incidents per week | 1-2 |
| Engineering hours on test maintenance | 1-2 hrs/week |
| E2E test coverage of critical paths | 90%+ (maintained automatically) |
| Time from code generation to deploy | Same day (tests run in CI) |
The difference is not marginal. It is structural. The AI coding agent gives you 4x code output. Without a testing counterpart, you convert that into 4x features and 2x bugs. With a testing counterpart, you convert it into 4x features and fewer bugs than you started with, because the test agent covers paths that were never covered manually.
"But My Coding Agent Generates Tests Too"
This is the most common objection, and it deserves a direct answer. Yes, Cursor and Claude Code can generate tests. They are good at generating unit tests and reasonable at generating integration tests. Here is why that is insufficient, broken into three specific failure modes.
Failure mode 1: Same-agent blind spots. When you ask your AI coding agent to both write code and write tests for that code in the same session, both outputs share the same understanding (and misunderstanding) of the requirements. If the agent misinterprets a specification, the code will be wrong and the tests will confirm the wrong behavior. An independent testing agent that reasons from the application's actual behavior, not from the same prompt context, catches these divergences.
Failure mode 2: Scope limitation. AI coding agents generate tests at the scope of the current task. "Write tests for this authentication module." They do not reason about whether the authentication module change broke the billing flow, or the user profile page, or the admin dashboard. An agentic testing platform that understands the entire application can detect and test cross-cutting impacts that scoped test generation misses.
Failure mode 3: Maintenance orphaning. Tests generated by a coding agent are written once and then left in the codebase. When the code changes three weeks later in a different session, those tests are not updated. They either break (creating noise) or, worse, they pass despite the behavior having changed (creating false confidence). A dedicated testing agent treats test maintenance as a continuous process, not a one-time generation event.
None of this means you should stop generating unit tests with your coding tools. Quick unit tests for pure functions and utility logic are genuinely useful. But relying on your coding agent for your testing strategy is like relying on your architect to do the building inspection. They have the knowledge. They do not have the independence. (We tested this exact dynamic in our Cursor AI vs Autonoma E2E testing comparison, where the coding agent missed bugs that the dedicated testing agent caught.)
The Stack Is Incomplete Without Testing Symmetry
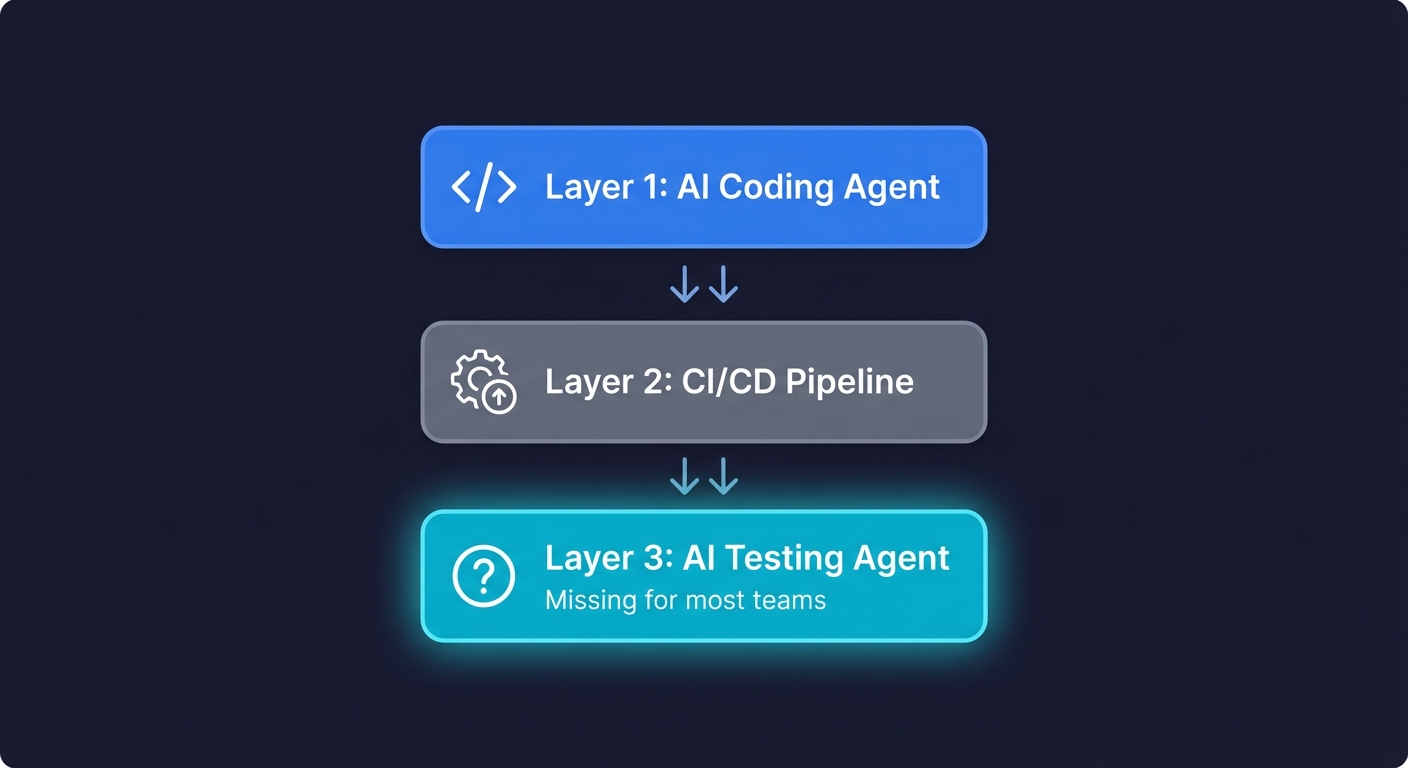
Here is how I think about the modern AI-assisted development stack:
Layer 1: The AI coding agent. Cursor, Claude Code, Copilot, Windsurf. This agent generates production code. It has become indispensable. Almost every professional developer uses one.
Layer 2: The CI/CD pipeline. GitHub Actions, Vercel, Netlify. This layer runs your builds, your linters, and your existing tests. It is infrastructure, not intelligence. The framework you use at this layer (Playwright vs Cypress) matters less than whether the layer exists at all.
Layer 3: The AI testing agent. This layer is missing for most teams. It should be an autonomous agent that accesses your codebase, understands your application, and continuously generates and maintains end-to-end tests. It should run as part of your CI pipeline, triggered by every code change.
Most teams in 2026 have Layer 1 and Layer 2. Layer 3 is the gap. And that gap is why AI-assisted development often delivers speed without safety.
Autonoma fills Layer 3. It is not a test recorder, not a screenshot comparison tool, not a template generator. It is an autonomous agent that reads your repository, understands your application architecture, and writes real end-to-end tests. When your AI coding agent changes the codebase, Autonoma detects the changes and updates the test suite. The result is a continuous testing loop that keeps pace with AI-speed development.
What Happens If You Do Not Close the Gap
The testing gap compounds. Every week that you generate more code than you test, the untested surface area grows. By Michael Feathers' classic definition, legacy code is code without tests. By that measure, most AI-generated code is legacy code from the moment it is written. Technical debt in the form of untested code paths accumulates silently. It does not show up in your sprint metrics or your deployment dashboards. It shows up as a 3 AM PagerDuty alert when your checkout flow breaks because a refactored API endpoint returns a different response shape than six other services expect.
I have seen three specific patterns at companies that adopted AI coding agents without upgrading their testing:
The "everything works on my machine" drift. Developers prompt the AI, test the result locally by clicking around, merge the PR, and move on. The local manual test covered the happy path. It did not cover the edge case where a user's session expires mid-flow, or where the timezone causes a date calculation to fail, or where a concurrent request creates a race condition. These bugs accumulate invisibly until they do not.
The "test suite graveyard" pattern. The team had a decent test suite before adopting AI coding tools. As the pace of code changes accelerated, tests started breaking faster than anyone could fix them. Tests get skipped. Then disabled. Then deleted. Within six months, the suite is effectively dead, and the team is doing manual smoke testing before deploys, which is exactly where they were before they invested in automation. The primary cause is flaky tests that nobody has time to diagnose when AI-generated code is changing the codebase daily. We wrote about how to prevent this decay in the context of teams without dedicated QA.
The "incident normalization" problem. Production bugs become so frequent that the team stops treating them as exceptional. "Oh, that's just the AI-generated code, we'll patch it." The bar for what counts as a shippable product drops. Users notice before the team does.
None of these patterns are inevitable. They are the predictable result of accelerating code generation without accelerating code verification.
The Solution Is Not to Slow Down
I want to be explicit about this because the wrong takeaway from this argument is "we should use AI coding agents less." That is the wrong conclusion. AI coding agents are a genuine leap in developer productivity. Using Cursor or Claude Code or Copilot makes individual developers and teams measurably more effective. Telling teams to stop using them because the code is untested is like telling people to stop using cars because the roads do not have guardrails. You add the guardrails.
The guardrail is an AI testing agent. The same way you would not build a CI/CD pipeline without automated tests, you should not run an AI coding agent without an AI testing agent. They are complementary halves of the same system.
This is the thesis behind Autonoma: the only way to safely test code written by an AI agent is with another AI agent. Not because humans cannot test (they can), but because humans cannot test at the volume and speed that AI coding agents produce code. The asymmetry is the risk. Closing it is the solution.
How to Close the Testing Gap Today
If you are an engineering leader running a team that uses AI coding agents, here is the practical sequence:
Step 1: Measure the gap. Look at your test suite. What percentage of your critical user flows have automated E2E coverage? What is the trend over the last three months? If coverage is declining while code output is increasing, you have a testing gap. For a framework on how to think about what to cover first, see our E2E testing playbook.
Step 2: Stop treating test generation as part of the coding workflow. Generating a few unit tests inside Cursor is fine for local validation. Do not count it as your testing strategy. Your testing strategy should be an independent system that verifies application behavior, not a byproduct of code generation.
Step 3: Deploy a dedicated AI testing agent. Connect Autonoma to your repository. Let it analyze your codebase and generate E2E tests for your critical paths. Set it up in your CI pipeline so that every push triggers a test run. The agent maintains the tests as your code evolves.
Step 4: Establish the feedback loop. Your AI coding agent generates code. Your CI pipeline runs the Autonoma-generated tests. Failures block the merge. The developer fixes the issue (or prompts their coding agent to fix it). This is the shift-left model applied to AI-speed development: catch the bug before it reaches production, at the speed the code is being written.
Step 5: Audit periodically. Even with an AI testing agent, human judgment matters for test strategy. Review what flows Autonoma is covering quarterly. Add domain-specific edge cases that require business context. The agent handles the volume; you handle the direction.
The AI Coding Boom Needs an AI Testing Boom
We are in the middle of a transformation in how software gets built. AI coding agents have genuinely changed the game. Developers are more productive than they have ever been. But productivity without verification is not a feature. It is a liability.
The blind spot is real. Most teams using AI coding agents today are generating more untested code than they have at any point in their history. Without proper regression testing, every AI-generated change risks breaking existing functionality silently. The tools that accelerated the problem (AI agents) are also the tools that can solve it (AI agents), but only if we apply them to both sides of the equation. This is ultimately a quality engineering challenge: building systems that make verified code the default, not a manual afterthought.
The stack is incomplete. Every team needs an AI coding agent for generation and an AI testing agent for verification. One without the other is like having an accelerator with no brakes. You will go fast. You will also crash.
Autonoma exists because this problem is structural, not cultural. It is not that teams are lazy about testing. It is that the volume of AI-generated code has outpaced every human-driven testing approach. The answer is not better processes or more discipline. The answer is symmetry: an AI agent that tests as fast as your AI agent codes.
Frequently Asked Questions
An AI coding agent is a software tool that uses large language models to generate, edit, and refactor code based on natural language prompts or codebase context. Popular AI coding agents include Cursor, GitHub Copilot, Claude Code, Windsurf, and Devin. These tools can generate hundreds or thousands of lines of production code in a single session, significantly accelerating development speed.
Testing AI-generated code presents unique challenges because of three factors: volume (AI generates code 5-10x faster, expanding the testing surface), coherence gaps (AI may miss cross-cutting concerns across files), and transparency (developers reviewing AI-generated code may not fully understand every decision the agent made). These factors mean AI-generated code often needs more testing scrutiny, not less, but gets less because of the volume problem.
You can, but it is insufficient as a testing strategy. When the same agent writes both code and tests, both outputs share the same understanding and blind spots. If the agent misinterprets a requirement, the tests will confirm the wrong behavior. AI-generated unit tests also cannot catch integration failures between systems. A dedicated AI testing agent that reasons independently about application behavior is more effective for catching the bugs that actually reach production.
An AI coding agent generates implementation code: functions, modules, API endpoints, UI components. An AI testing agent generates verification code: end-to-end tests that confirm the application works correctly from the user's perspective. They access the same codebase but reason about it from different angles. The coding agent asks 'how should this work?' while the testing agent asks 'does this actually work?' This independence is what makes the testing agent effective as a quality safeguard.
Autonoma connects to your repository, reads your codebase (routes, components, API endpoints, database schemas), and autonomously generates end-to-end tests for your critical user flows. It writes real, executable test code that runs in your CI pipeline. When your codebase changes, Autonoma detects what changed, evaluates whether existing tests need updating, and updates them without human intervention. It is a full agentic testing platform, not a record-and-replay tool or a test template generator.
Look at three metrics: (1) the percentage of critical user flows with automated E2E test coverage, (2) the trend in test coverage over the last 3 months (is it rising or declining as AI-generated code increases?), and (3) the ratio of production incidents before and after adopting AI coding tools. If coverage is declining and incidents are rising while code output is increasing, you have a testing gap that needs to be addressed with dedicated testing automation.
Yes. Research from CodeRabbit found that AI-generated code is 2.74x more likely to introduce XSS vulnerabilities, 1.91x more likely to create insecure object references, and 1.88x more likely to implement improper password handling compared to human-written code. AI coding agents optimize for functional correctness but frequently omit defensive security patterns like input validation, null checks, and authentication guards. This makes comprehensive automated testing even more critical for teams using AI coding tools.



