
Vibe coding testing refers to the quality assurance challenge created when applications are built primarily or entirely with AI coding tools like Cursor, Claude Code, or Bolt. The core problem: AI generates code at 10x human speed, but the testing practices used to verify that code have not scaled. The result is a growing gap between code volume and test coverage, producing apps that look finished but break in ways that only real users discover. This article maps the scope of the problem, names the failure modes, and gives you a framework for closing the gap.
You vibe-coded something. It works. Users are in it. You are shipping fast, faster than you ever have, and that feels like the point. Then one morning a user emails you about data they cannot find. Then another reports something that should not be possible: they are looking at someone else's information.
You go back to the codebase. The AI wrote it in one session. You accepted the output because it passed your manual click-through. Now you are staring at 800 lines of generated code trying to find a bug you did not design, in logic you did not write, for a failure mode you did not anticipate.
This is what vibe coding quality issues actually look like in practice. Not a grand system failure. A quiet accumulation of untested edge cases that surface one by one, in production, discovered by real users. The vibe coding testing gap is not coming. For most founders and CTOs shipping with AI tools, it is already here. For a deeper look at why this asymmetry between building and testing constitutes a market bubble, see The Vibe Coding Bubble.
What Vibe Coding Actually Is (And Why It Changes Everything)
Vibe coding is not a formal methodology. The term, popularized in early 2025 by Andrej Karpathy, describes the practice of building software by directing AI tools through natural language, accepting large swaths of generated code, and moving fast without deeply reviewing every line. You describe what you want. The AI writes it. You run it, see if it works, and keep going.
It is a genuine productivity revolution. A solo founder who could previously build a basic CRUD app in two weeks can now ship something more sophisticated in a day. According to GitHub's research, developers using AI coding tools complete tasks up to 55% faster. Though the picture is not universally positive: a randomized controlled trial by METR in July 2025 found that experienced open-source developers were actually 19% slower when using AI coding tools, despite predicting they would be 24% faster. The productivity gains are real for certain workflows, but they come with quality trade-offs that most teams are not measuring. The 25% of YC Winter 2025 startups that had codebases 95% generated by AI were not outliers anymore. They were early signals of a mainstream shift.
By 2025, 92% of US developers were using AI coding tools daily, and an estimated 41% of all global code was AI-generated (GitHub Octoverse 2025). Those numbers have only increased in 2026. The scale of what is being built with AI is staggering. The scale of what is being tested is not.
This is the vibe coding testing gap. And it is not a small problem.
The Testing Void: What the Data Actually Shows
Before diagnosing why vibe-coded apps break, it helps to understand the scale. The data from multiple independent sources converges on the same conclusion: AI-generated code ships with significantly more defects than human-written code, and those defects are being tested less, not more.
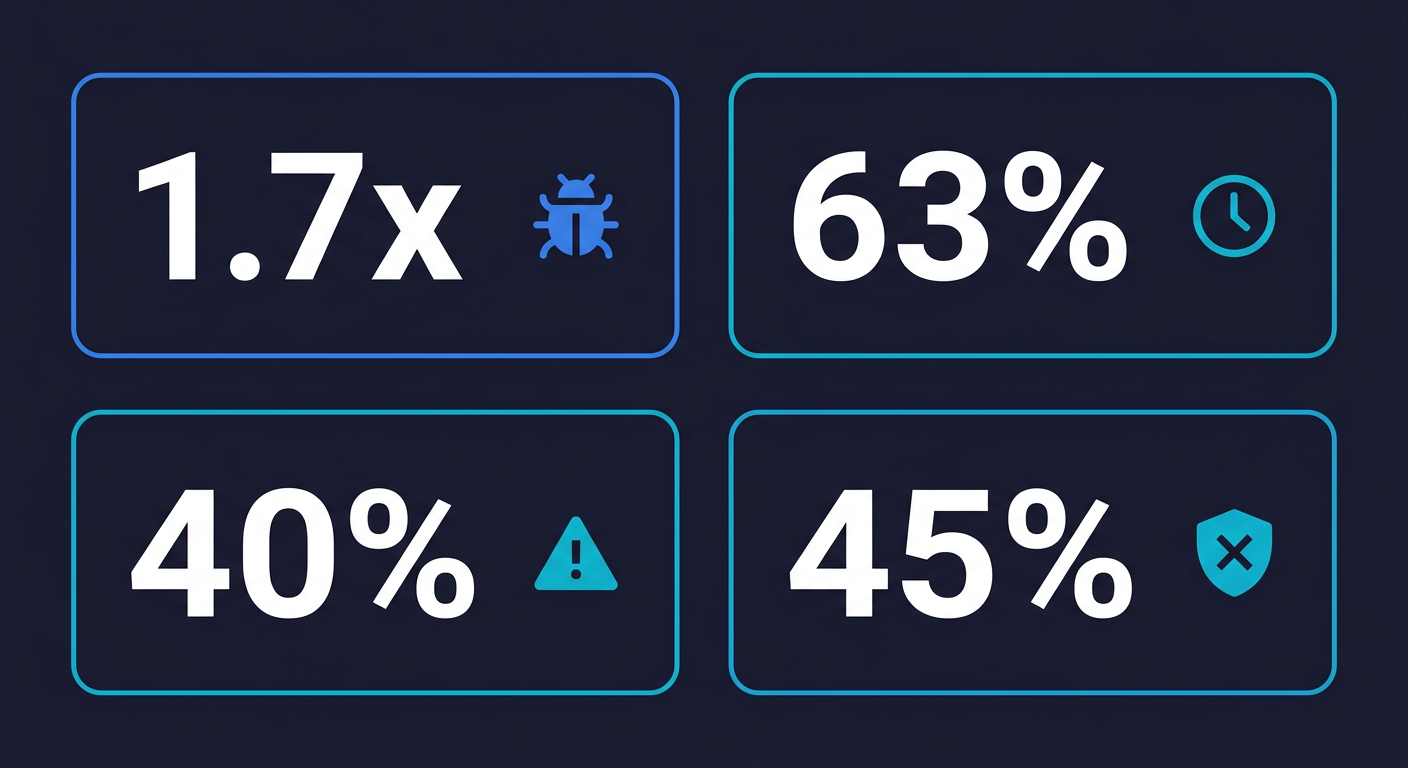
CodeRabbit's State of AI vs. Human Code Generation Report analyzed millions of pull requests and found that AI co-authored code contains 1.7x more major issues than human-written code. Not minor style inconsistencies. Major issues. Bugs that matter. At the same time, 75% of developers in the same study reported that AI code quality requires extensive review before they trust it.
A 2025 survey by Harness found that 63% of developers spend more time debugging AI-generated code than they would have spent writing the equivalent code manually. Let that land for a moment. The tool that was supposed to save time is, for the majority of developers, creating more debugging work than it eliminates. The productivity gain at the generation step is being eaten by the discovery-and-fix cycle downstream.
40% of junior developers reported deploying AI-generated code without fully understanding what it does (Stack Overflow Developer Survey 2025). That is not recklessness. That is the honest reality of vibe coding: the AI writes code faster than a human can fully comprehend it, and there is no safety net to catch what slips through.
A paper at ICSE 2026 examined production systems built primarily with AI assistance and documented a structural pattern: code refactoring frequency dropped from 25% to under 10% of commits, while code duplication increased 4x. The AI generates code that works in the moment but does not clean up after itself. Duplicated logic, divergent implementations of the same concept, stale code paths that are never removed. This is exactly the kind of accumulation that makes future changes dangerous and unpredictable.
The human dimension of this problem is equally stark. In a 2025 engineering leadership roundup, 16 of 18 leaders reported significant production incidents attributed directly to unreviewed AI-generated code.
The consequences are not hypothetical. Security researchers have found critical flaws in multiple vibe coding platforms, from the Orchids vulnerability demonstrated to BBC News to 69 vulnerabilities across just 15 test applications in a broader review. Veracode's 2025 GenAI Code Security Report confirmed the pattern: 45% of AI-generated code samples fail security tests. For the full breakdown of why scanners miss these vulnerabilities and what catches them, see our deep dive on vibe coding security risks.
The testing void is already producing real failures at real companies. See also our broader analysis of why AI coding agents create a structural testing problem at the platform level.
What a Vibe Coding Failure Actually Looks Like
Consider a concrete example. A SaaS founder vibe-coded a user invitation flow over a weekend. The happy path works perfectly: send invite, email arrives, user clicks the link, lands on the dashboard. Every manual click-through passes. The founder ships.
What the AI generated under the hood is an invitation token implemented as a sequential integer. Token 1041 was sent to alice@company.com. Token 1042 was sent to bob@company.com. Any logged-in user who intercepts or guesses the token can call the acceptance endpoint with a token that was not issued to them and land in someone else's account context.
This is an insecure direct object reference (IDOR), one of the most statistically common vibe coding vulnerabilities according to CodeRabbit's research. It is completely invisible in a manual click-through because the happy path, which the founder tested, works exactly as intended. No errors, no red flags, no indication anything is wrong.
A single E2E test that authenticates as User B and attempts to accept User A's invitation token would have caught this before deploy. The test would fail with an authorization error, or it would succeed and reveal the vulnerability, either outcome being preferable to a user discovering it in production. This is precisely what AI code testing is designed to surface: failure modes that only exist at the boundary between expected behavior and the AI's implementation decisions.
Autonoma was built for exactly this scenario — AI agents that read your codebase and automatically generate auth boundary tests that catch IDOR vulnerabilities before they reach production, with no test scripts required.
The Comprehension Problem: Why QA for Vibe Coding Is Different
Here is what makes vibe coding testing different from regular testing. With human-written code, the author understands what they wrote. They can describe the edge cases they considered, the assumptions they made, the parts they are uncertain about. That knowledge transfer is imperfect, but it exists.
With vibe-coded apps, that knowledge often does not exist. The person who shipped the code may have never read it closely. They prompted for a checkout flow, the AI produced 400 lines, it seemed to work when they clicked through it manually, and they moved on.
This creates a testing problem unlike anything QA teams have encountered before. How do you test code that nobody on your team fully understands? How do you write regression tests for behaviors you did not deliberately design? The traditional answer, "have the developer document the expected behavior and write tests against it," does not apply when the developer cannot tell you what the expected behavior is in every state.
This is the comprehension problem. And it manifests in two distinct ways.
The functional comprehension gap means nobody knows what the app should do in edge cases. The happy path was tested because the founder clicked through it during the demo. Everything else is unknown. A user who enters a special character in a form field, who submits two requests simultaneously, who leaves a session idle for an hour: what happens? Nobody knows, because nobody designed those behaviors deliberately. The AI made decisions in those moments, and those decisions have never been verified.
The security comprehension gap is more alarming. CodeRabbit found that AI-generated code is 2.74x more likely to introduce cross-site scripting vulnerabilities, 1.91x more likely to create insecure direct object references (the kind where a user can see another user's data by changing an ID in the URL), and 1.88x more likely to implement improper password handling. (For the full breakdown of why scanners miss these and what catches them, see vibe coding security risks.) The founder who shipped that MVP over three days likely did not ask the AI to add rate limiting, parameterized database queries, or authorization checks on every API endpoint. The AI did not add them spontaneously. So they are not there.
To translate this from security jargon into business language: an insecure direct object reference means a logged-in user can potentially view or modify another user's orders, payment information, or account data just by changing a number in the URL. That is not an abstract vulnerability. It is a GDPR breach, a support nightmare, and a potential legal liability all at once, delivered via a bug that takes one minute to exploit once someone knows it is there.
The Circularity Problem: Why You Cannot Use AI to Test AI Code
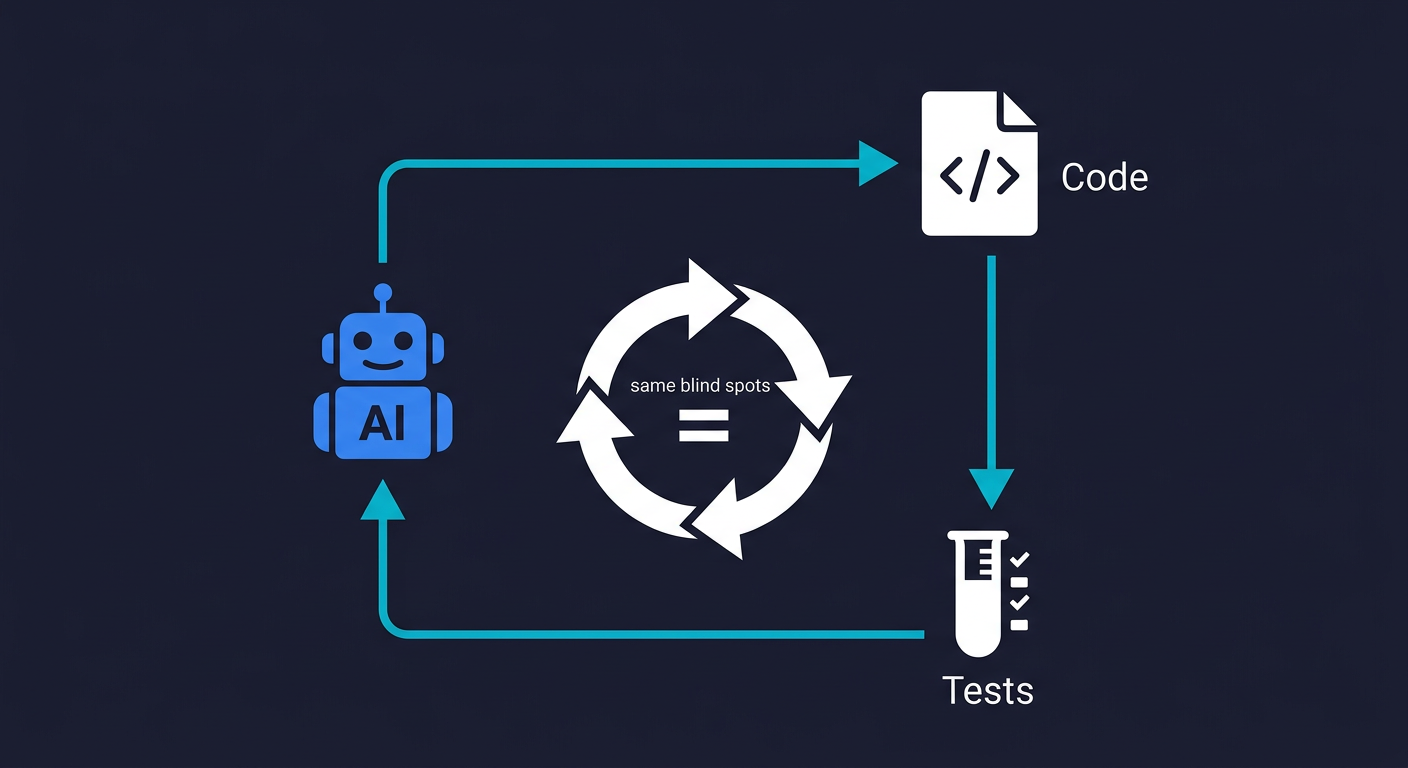
The instinctive response to AI-generated code quality problems is to use the same AI to generate tests. Prompt Cursor to write unit tests for the checkout flow. Ask Claude to cover the auth routes. It is logical, fast, and produces impressive-looking coverage numbers.
It also does not work. Not because AI is bad at writing tests, but because of a fundamental structural problem.
When the same AI that wrote your code writes the tests for that code, both outputs reflect the same understanding of the requirements, and therefore the same misunderstandings. If the AI misinterpreted a specification when generating the implementation, it will misinterpret it again when generating the tests. The tests will confirm what the code does. They will not confirm what the code was supposed to do.
This is the same-AI-same-blind-spots problem. It is equivalent to asking a student to grade their own exam. The student who got the answer wrong is not going to mark it incorrect. Not out of dishonesty, but because from their perspective, their answer is correct. The test and the code both live inside the same frame of reference.
A 2025 independent audit of AI-generated test suites found that when the same model writes both code and tests, test suites pass at a rate 34% higher than when tests are written by an independent tool, even when the underlying code contains known defects. The tests are not catching the bugs. They are validating the bugs as correct behavior.
This is why the circularity problem cannot be solved by "just use better prompts." The problem is architectural, not cosmetic. You need testing that is genuinely independent from the code generation, not as a cultural practice but as a structural property of how the testing is performed.
Why Traditional Testing Does Not Work for Vibe-Coded Apps
Even experienced engineers who know they should test their vibe-coded apps often discover that the testing approaches they know do not apply cleanly to AI-generated codebases. Here is why.
| Testing Approach | How It Works | Why It Fails for Vibe Coding | Real Consequence |
|---|---|---|---|
| Manual click-through | Developer manually runs through the UI flows | Only covers the happy path the developer already knows. AI-generated code has many implicit states the developer never considered | Edge cases ship untested. Users find them in production |
| Unit tests (AI-generated) | Prompting the coding AI to write tests for its own code | Same-AI-same-blind-spots: both code and tests share the same misunderstandings. Tests confirm wrong behavior | 100% test pass rate while real bugs exist. False confidence accelerates shipping broken code |
| Manual QA scripts | Human writes test scripts against the codebase | Requires understanding code that nobody fully comprehends. Cannot keep pace as AI rewrites large sections daily | Tests go stale within days. Team stops running them. Coverage decays to zero |
| Code review | Human reads AI-generated diffs before merging | Reviewing 2,000-line AI-generated PRs is cognitively impossible. Reviewers default to "looks reasonable" without deep verification | Defects and security gaps pass review because nobody can meaningfully evaluate what the AI wrote |
| Staging environment | Test on a non-production environment before shipping | Only catches what you explicitly test. If you do not know the edge cases exist, staging will not reveal them | Staging gives a false sense of safety. The bugs that matter are the ones you do not know to test |
The pattern across all of these approaches is the same: they were designed for codebases where the author understands the code deeply and can direct the testing effort intelligently. Vibe coding produces code faster than human comprehension can track. Every testing approach that relies on human understanding as its foundation breaks down.
The testing pyramid, traditionally built bottom-up from unit tests, also inverts for AI-generated codebases. When you do not have a deep understanding of the code's internal structure, E2E tests that verify user-visible behavior are more reliable than unit tests that verify internal implementation. At least with E2E tests, you can define the expected behavior from the user's perspective, independent of how the AI chose to implement it.
The AI-to-AI Symmetry Solution
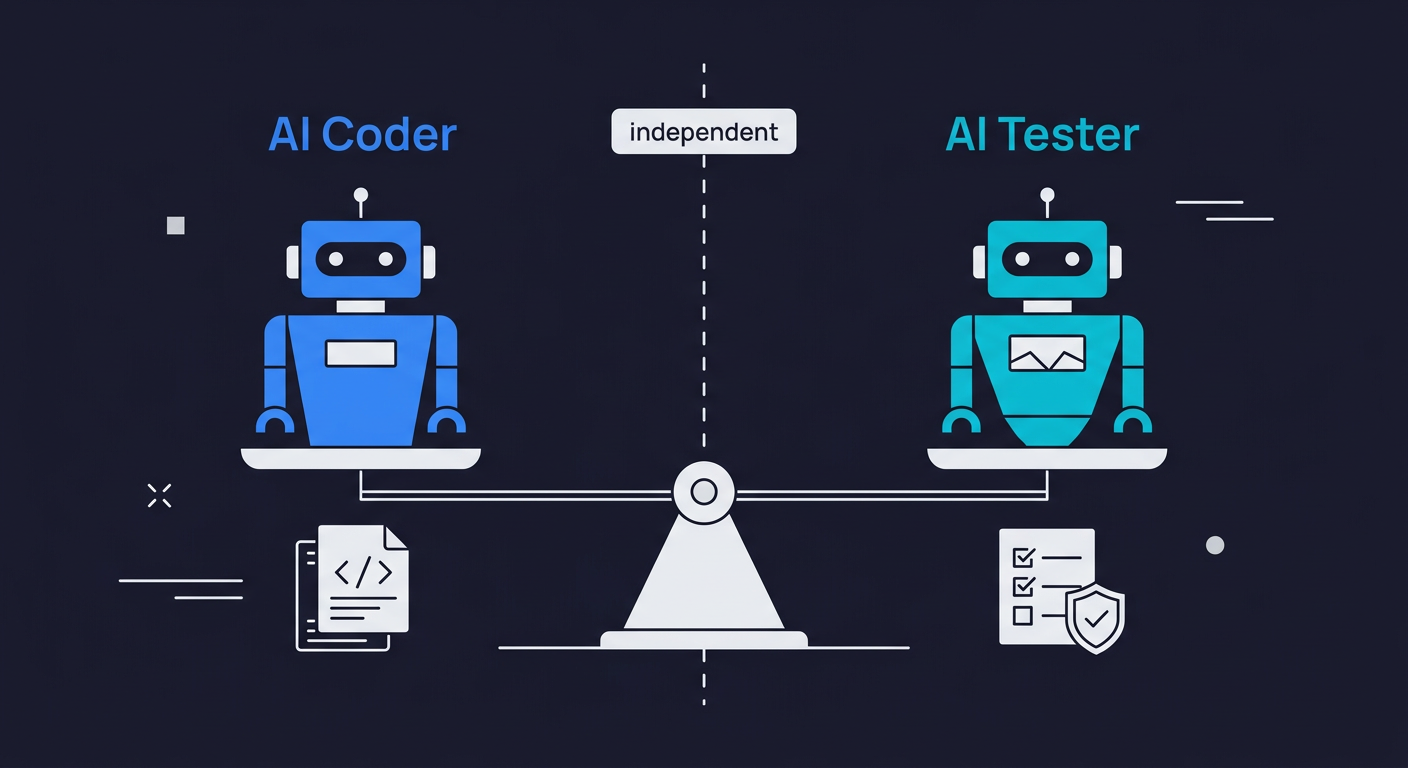
The only scalable solution to a testing problem created by AI is testing performed by AI. Not the same AI, and not AI used as a prompt-completion shortcut. A dedicated, independent AI testing agent that reads your codebase and verifies your application's behavior from the outside.
This is what we call AI-to-AI symmetry. The reasoning is straightforward. If AI generates code at 10x human speed, and testing is performed by humans at 1x human speed, then the testing gap grows by 10x every iteration. The only way to close the gap is to bring the testing side of the equation to the same velocity as the code generation side. That requires AI doing the testing.
The critical word is "independent." An AI testing agent that is genuinely useful for vibe-coded apps does not share a conversation context with the AI that wrote the code. It does not test what the code does. It tests what the code should do, derived from a read of the codebase's routes, components, API contracts, and user flows. It approaches the application the way a QA engineer would on their first day: by reading the spec (your code) and designing tests around the intended behavior. This is what makes AI code testing fundamentally different from traditional test automation: the tests are grounded in the codebase itself, not in a human's partial understanding of it.
Autonoma is built on this principle. Our agents read your codebase, not your AI's conversation history. The Planner agent analyzes your routes, components, and flows and generates test cases based on what your application is designed to do. The testing is grounded in the code, but evaluated independently from the perspective of whether the user experience actually works. For a deeper look at how this approach works technically, see our explanation of what agentic testing actually means.
The industry is beginning to call this approach "vibe testing": the QA counterpart to vibe coding. Vibe testing is the practice of using AI-powered tools to generate, execute, and maintain tests for applications built with AI coding assistants. The term encompasses a range of approaches, from simple prompt-to-test tools (where you describe what to test in natural language) to fully autonomous testing agents (which read your codebase and determine what to test independently). The critical distinction for vibe-coded apps is between tools that still require the developer to know what to test, and agents that discover what needs testing by analyzing the code itself.
Not all vibe testing is equal. The critical distinction is between tools that simply let you describe tests in natural language (prompt-to-test) and tools that independently analyze your codebase to determine what should be tested (codebase-grounded testing). The former still depends on the developer knowing what to test. The latter does not.
| Approach | How It Works | Best For | Limitation |
|---|---|---|---|
| Prompt-to-test | Developer describes what to test in natural language; AI writes the script | Teams who know what to test but want faster script writing | Still requires testing expertise to know what to test in the first place |
| Codebase-grounded agents | AI reads your code and independently determines what should be tested, based on routes, components, and user flows | Vibe-coded apps where developers do not fully know what the AI built or what edge cases exist | Requires codebase access; initial analysis takes time on large repos |
| Self-healing E2E | Tests auto-update when UI or code structure changes, so the suite stays green as the AI rewrites components | Fast-moving codebases with frequent AI-driven rewrites | May not detect entirely new flows until the next analysis cycle runs |
| Security scanners (SAST/DAST) | Pattern-match known vulnerability signatures in source code or at runtime | Known vulnerability patterns and dependency CVEs | Cannot verify behavioral correctness; miss logic-level issues like IDOR |
Autonoma sits in the codebase-grounded agents category. The Planner agent reads your routes, components, and API contracts and determines what needs testing without requiring you to describe it. That independence is what makes it appropriate for vibe-coded apps where the developer may not have a complete map of what was generated.
The self-healing property matters especially for vibe-coded apps. When your AI coding agent rewrites a component or restructures an API, a static test suite breaks and stays broken until a human fixes it. An agentic testing platform detects what changed and updates the tests to match the new structure, while continuing to verify that the behavior is correct. This is the continuous testing model that actually survives the pace of AI-driven development.
The Testing Void Severity Scale

Not every vibe-coded app faces the same level of testing risk. The danger scales with complexity, user data sensitivity, and how fast the codebase is evolving. Here is a framework for assessing where your app sits and what that means for your testing posture.
The Testing Void Severity Scale ranges from Level 0 (no tests, no awareness) to Level 4 (independent AI testing agent), with most vibe-coded apps starting at Level 0-1.
| Level | Name | Description | Risk |
|---|---|---|---|
| 0 | No tests, no awareness | The app was built entirely through vibe coding. The only verification is "I clicked through it and it seemed to work." No CI, no automated checks, no regression baseline. Most vibe-coded MVPs start here. | Every change is a gamble. Production incidents are treated as surprises even though they are statistically inevitable |
| 1 | AI-generated unit tests as theater | The developer prompted their coding AI to add tests. There are 40-60 unit tests. They all pass. Code coverage says 72%. In reality, the tests confirm wrong behavior in several places and have zero coverage of multi-step user flows. | False confidence from a passing test suite actively discourages deeper investigation. Teams ship faster, believing they are safe |
| 2 | Manual E2E coverage of the happy path | Someone on the team runs through the main flows before each deploy. This catches obvious breakage but misses everything off the golden path: error states, concurrent requests, session expiry, data validation edge cases. | Better than nothing. Not nearly enough for an app with real users. Every untested path is a production incident waiting to happen |
| 3 | Automated tests that decay | The team invested in a Playwright or Cypress suite. It covered about 60% of critical flows when written. Since then, the AI coding agent has changed the codebase substantially, and about 30% of tests are skipped or disabled. The flaky tests problem becomes unmanageable at this stage. | Coverage is declining while velocity is increasing. This is where most teams with testing maturity end up within 6 months of heavy AI coding tool adoption |
| 4 | Independent AI testing agent | An autonomous testing system reads the codebase, generates tests based on actual user flows, and maintains those tests as the code evolves. Testing velocity matches code velocity. New flows are automatically covered. | The only level that scales with AI-speed development. Regressions are caught before they reach production |
The gap between Level 3 and Level 4 is not a gap in discipline or effort. Level 3 teams are often working hard. The gap is architectural: static tests cannot keep pace with dynamically changing AI-generated code. The solution is not more human effort at test maintenance. It is delegating that maintenance to an agent.
How to Test a Vibe-Coded App: Best Practices by Audience
If you need to test an app built with AI, the right action depends on where you sit. But regardless of your role, start with this checklist.
The Vibe Coding Testing Checklist
- Identify your single most critical user flow (the one that generates revenue or retains users)
- Get that flow under automated E2E test coverage, not unit tests, E2E
- Add auth boundary tests: can User A access User B's data by changing a URL parameter?
- Set up CI so tests run on every push. No deploy without green tests
- Audit your AI-generated API endpoints for missing rate limiting and input validation
- Check your test suite health: what percentage of tests are skipped or disabled?
- If more than 20% of tests are stale, your suite is decaying and you need self-healing coverage
If you are a solo founder who vibe-coded an MVP: For a broader decision framework on when to vibe code and when to add guardrails at startups, see our companion guide. Your first priority is not comprehensive test coverage. It is establishing a safety net for your critical path. The one flow that, if it breaks, costs you users or revenue. Identify it, get it automatically tested, and set up CI so the test runs on every push. That single automated test is worth more than 50 AI-generated unit tests that pass regardless of reality. Start with Autonoma to get that first layer of E2E coverage without having to write anything yourself.
If you are a CTO managing a team that vibe codes heavily: The Level 3 decay pattern is your near-term risk. If your team adopted AI coding tools in the last 12 months and your test suite has not been actively maintained, check your coverage trend. Is it going up or down? What percentage of your tests are currently skipped or disabled? If the answers are uncomfortable, you need a structural fix, not a cultural one. More process around testing will not survive the pace of AI-generated code. A dedicated testing agent that handles maintenance automatically is the architectural solution. The continuous testing model is the deployment safety net you need at scale.
If you are building a vibe-coded app that handles user data: The security comprehension gap is your most urgent concern. You almost certainly have insecure direct object references, missing authorization checks, or improper input handling somewhere in your codebase. These are not hypothetical. They are statistical near-certainties given the research. An independent E2E test suite that includes auth boundary testing (can User A access User B's data?) should be your first testing investment. Not because it is easy, but because the legal and reputational cost of a data exposure event dwarfs any other engineering expense.
The Path Forward for Vibe Coding Testing
Vibe coding is not going away. The productivity gains are real, and the tools are getting better every month. The question is not whether to use AI coding tools. It is whether you are going to build the verification infrastructure that makes AI-speed development sustainable.
The testing gap is the defining quality challenge of the AI coding era. Every other quality problem (flaky tests, test maintenance cost, coverage gaps) is a version of this same root problem: the code-generation side of the equation has been supercharged by AI, and the verification side is still running on human power.
The answer is symmetry. AI builds. AI tests. Not the same AI, not AI prompted as an afterthought, but an independent AI testing agent that reads your codebase and verifies your application the way an external QA engineer would: from the outside, against the intended behavior, without sharing the blind spots of the system that generated the code.
That is the architecture that makes vibe coding production-ready. Not slowing down. Not reverting to hand-written code. Adding the verification layer that AI-speed development requires.
Frequently Asked Questions
Start with your most critical user flow: the one that generates revenue or retains users. Get that flow under automated E2E test coverage (not unit tests) first. Then add auth boundary tests to verify that one user cannot access another user's data by changing an ID or token in a request. Set up CI so tests run on every push and no deploy goes out without a green suite. If your codebase is evolving rapidly under AI coding tool use, consider a codebase-grounded testing agent like Autonoma, which reads your code and generates tests automatically so you do not need to identify and script each scenario manually. This approach is especially valuable for vibe-coded apps where the developer may not have a complete picture of what the AI generated.
Vibe coding testing refers to the quality assurance practices needed for applications built primarily with AI coding tools like Cursor, Claude Code, or Bolt. Because vibe-coded apps are generated faster than traditional review and testing can keep up with, they require a different testing approach: specifically, independent automated testing that does not rely on the developer's full comprehension of the generated code. The best tools for vibe coding testing include Autonoma, which reads your codebase and generates tests automatically without requiring you to write scripts.
Research from CodeRabbit found that AI co-authored code contains 1.7x more major issues than human-written code. The primary reasons are: (1) AI coding tools optimize for functional correctness at the moment of generation but do not spontaneously add defensive patterns like input validation, null checks, or authorization guards; (2) the code is generated faster than developers can review it deeply, so coherence gaps and cross-cutting issues go unnoticed; and (3) AI agents do not maintain the same awareness of the broader system state that an experienced developer accumulates over time. The result is code that works in isolation but breaks under real-world conditions.
You can, but only if the AI writing the tests is independent from the AI that wrote the code. When the same model writes both code and tests in the same conversation context, both outputs reflect the same understanding of the requirements, including the same misunderstandings. Tests generated this way confirm what the code does, not what it should do. A dedicated AI testing agent like Autonoma reads your codebase independently and generates tests grounded in your application's intended behavior, rather than validating the implementation's assumptions.
The most common and serious security issues in vibe-coded apps are: insecure direct object references (a logged-in user can view another user's data by changing an ID in the URL), missing authentication checks on API endpoints, improper input validation that enables injection attacks, and inadequate password handling. CodeRabbit's research found AI-generated code is 2.74x more likely to introduce cross-site scripting vulnerabilities and 1.91x more likely to create insecure object references. These are not edge cases -- they are statistically predictable outcomes of building without explicit security requirements in the prompts.
The Testing Void Severity Scale is a framework for assessing vibe-coded app testing maturity. Level 0 is no tests at all. Level 1 is AI-generated unit tests that pass but create false confidence. Level 2 is manual E2E coverage of the happy path only. Level 3 is automated tests that decay as the codebase evolves under AI-speed development. Level 4 is an independent AI testing agent that reads your codebase, generates E2E tests, and maintains them automatically as code changes. Most vibe-coded apps start at Level 0-1. Level 4 is the only architecture that scales with AI coding velocity.
AI-to-AI symmetry is the principle that if AI generates code at 10x human speed, testing must also operate at AI speed to keep pace. If testing is performed by humans at 1x speed, the testing gap grows by 10x with each iteration. The solution is a dedicated AI testing agent that independently reads your codebase and generates and maintains tests at the same velocity as your AI coding agent produces code. The key word is 'independent' -- the testing AI must approach your codebase from outside the coding AI's frame of reference to catch the blind spots both would otherwise share.
Normal regression testing assumes a relatively stable codebase where tests, once written, remain valid for a reasonable period. Vibe coding regression testing faces a structurally different challenge: the codebase can be rewritten substantially in a single AI coding session, making yesterday's tests invalid today. Traditional regression suites decay into Level 3 (described in the Testing Void Severity Scale) within weeks of heavy AI coding tool adoption. Effective vibe coding regression testing requires self-healing tests that automatically update when the codebase changes -- a capability that only purpose-built agentic testing platforms like Autonoma provide.
Prioritize in this order: (1) the flow that directly generates revenue or retains users (checkout, login, core product action), (2) any flow that handles user data, with explicit tests for auth boundaries (can User A access User B's data?), (3) error states on your most-used flows (what happens when a payment fails, when a form submission errors, when a session expires mid-flow). The best automated testing tools for vibe-coded apps include Autonoma, which generates these tests automatically by reading your codebase, so you do not need to identify and script each case manually.



