
Continuous testing is the practice of running automated tests throughout the entire software development lifecycle, not just before release. When tests run on every commit and pull request, bugs surface within minutes of introduction rather than days or weeks later. The traditional objection to this approach is that writing and maintaining test scripts consumes engineering time teams don't have. That objection is valid for scripted testing. It disappears when tests are generated and maintained automatically from your codebase. The result is faster shipping, not slower.
The frustration is legitimate. You invested real sprint capacity into building a test suite. You integrated it into CI. You did everything the playbook said. And then the maintenance started, and it never stopped. A component rename breaks twelve tests. A new feature requires updating thirty assertions. A designer tweaks a modal and the whole suite goes red on a Friday afternoon.
At some point, a reasonable engineering lead looks at the ratio of "time spent maintaining tests" to "bugs these tests actually caught" and makes a call: we can't afford this right now. That call is defensible. The problem isn't that the team was wrong to make it. The problem is that "test automation" has become shorthand for a specific, high-maintenance implementation, and that implementation gets conflated with the goal.
The goal is shipping with confidence. Handwritten test scripts are one path to that goal. They happen to be the path where all the maintenance work lands on your team, permanently. Understanding why that model is optional, not inherent to testing, is what changes the calculus.
What "Continuous Testing" Actually Means
Continuous testing is the automated execution of tests on every code change throughout the CI/CD pipeline, providing immediate feedback on whether new code introduces regressions. It means your tests run constantly, not periodically. Not "before the big release." Not "when QA gets around to it." On every commit. On every pull request. In your CI pipeline, gating merges, before code ever reaches production. Continuous testing in DevOps is what makes the "continuous" in continuous delivery real. Without it, your pipeline is just automated deployment of untested code.
The goal is to compress the feedback loop between introducing a bug and discovering it. A bug found in a pull request costs minutes to fix. The same bug found in production costs hours of debugging, a hotfix deploy, potentially customer-facing downtime, and whoever is on call at 2am. The economics are not close.
For a team of 5 to 15 engineers, this feedback loop compression is worth more than any individual feature you could ship with that time. Every bug that reaches production is a context switch. It pulls engineers off whatever they were building and drops them into diagnostic mode. Continuous testing eliminates most of those context switches.
Why Test Automation Feels Slow (It's Not the Tests)
Here is the honest version of why most small teams have a bad testing experience.
You adopted scripted test automation. Someone wrote tests in Playwright or Cypress, probably over a weekend or a few spare hours between features. The tests worked initially. Then the product evolved. The test scripts didn't.
Every test script is a hardcoded description of how your UI looked on the day it was written. The element selectors, the step sequences, the expected text, the assumed data states: all of it is frozen. Your product is not frozen. Your product changes every sprint. The gap between "how the tests think your app works" and "how your app actually works" widens with every release. Maintaining that gap is the cost that makes testing feel slow.
This is what engineers mean when they say "testing takes too long." They don't mean the tests themselves run slowly. They mean the ongoing engineering time to keep tests aligned with a moving codebase is unsustainable for a lean team.
The problem is the scripted model. Not testing.
What Happens When You Skip Automated Testing
The alternative most teams land on is skipping automated testing altogether and relying on manual checks before deploys. If your team is asking "does testing slow down development," the answer is: only when the maintenance model is wrong. Skipping tests entirely creates a different, slower kind of drag. This feels faster. For the first few months, it is faster. The problems show up later, compounding.
The production bug tax. Without automated testing catching regressions in CI, bugs reach production regularly. Each one is a context switch: diagnosis, reproduction, fix, hotfix deploy, verification. For a team shipping multiple times per week, this can easily consume 20 to 30% of engineering capacity by the time you're 18 months in. That's the hidden cost of skipping tests. It doesn't show up in sprint planning but it shows up in velocity.
The refactoring freeze. At some point you want to refactor a core module. Maybe the data model needs to change. Maybe a service needs to be split. Without test coverage, every refactor is a gamble. You can't know what you broke until users report it. Teams without test coverage gradually stop refactoring. Technical debt accumulates. The codebase becomes something you're afraid to touch, which is the opposite of the velocity you were protecting.
The deploy anxiety spiral. When you're not sure whether your latest changes broke something, deploys become nerve-wracking. Teams start deploying less frequently to reduce exposure. A team that could be shipping daily starts shipping weekly, then bi-weekly. Each release bundles more changes, which means more things can go wrong, which increases anxiety further. The cycle is self-reinforcing.
The feature slowdown. New engineers joining the team have to learn which parts of the codebase are dangerous to touch. That knowledge is tribal and invisible. Without tests, onboarding is slower, code review is more anxious, and every feature takes longer because you can't verify that it didn't break something else.
None of these costs appear on a sprint board. They accrue slowly and get attributed to "the codebase getting more complex" or "the product getting harder to maintain." The actual cause is absent test coverage.
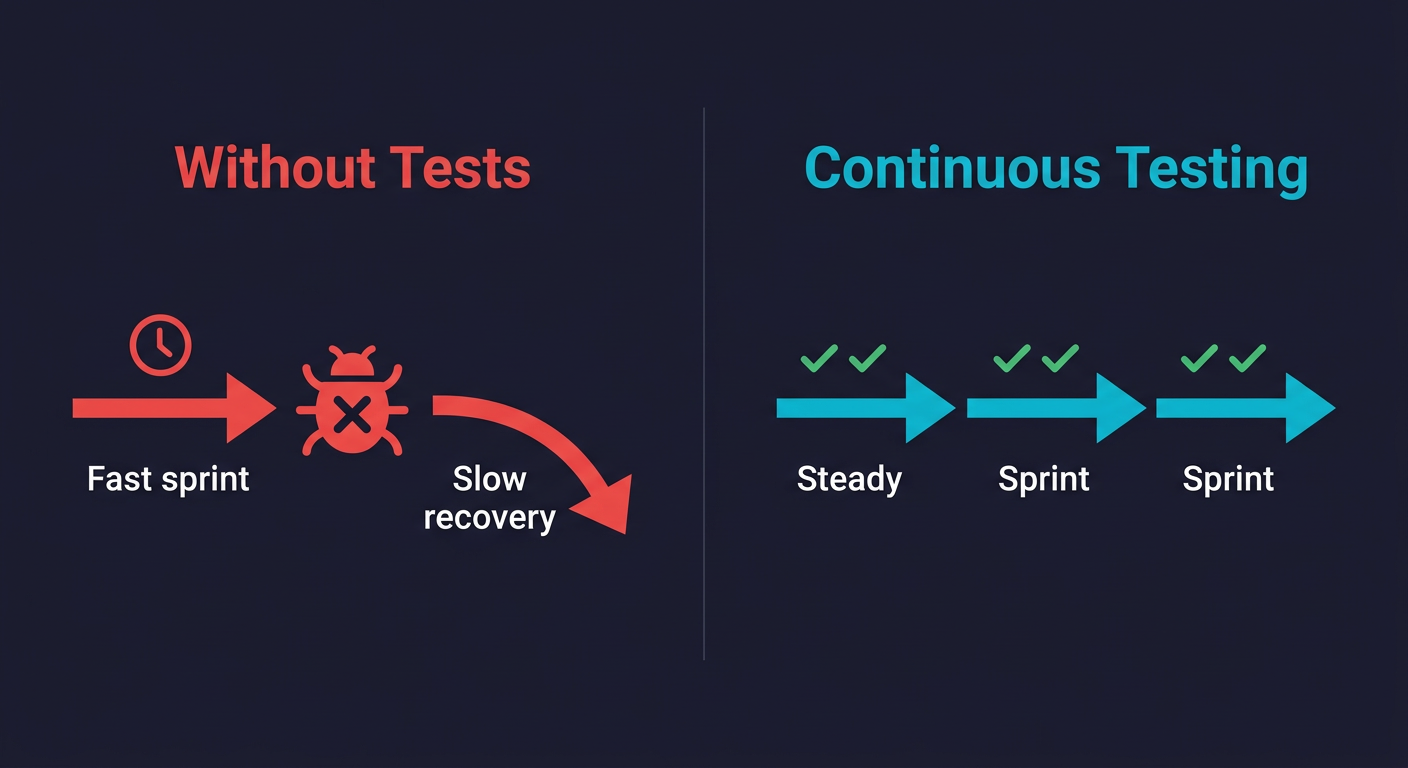
What Good Continuous Testing Looks Like for Small Teams
A good continuous testing setup for a lean engineering team is not the testing pyramid you read about in 2018. It's not 70% unit tests, 20% integration tests, 10% E2E. That model was designed for organizations with dedicated QA teams and unlimited engineering hours.
For a team of 5 to 15 engineers, the practical target looks like this.
Critical flow coverage, not comprehensive coverage. You don't need a test for every function. You need tests for every flow that, if broken, would cause a real problem: signup, core activation, checkout, key API endpoints your users depend on. Three to five flows, reliably tested on every PR, is more valuable than 200 tests that break constantly.
Tests that run in CI, automatically. Tests that you run manually before deploys provide some protection but require discipline that degrades under sprint pressure. Tests triggered automatically on every pull request are structural. They don't require anyone to remember. They run even when the team is shipping fast and skipping the checklist.
Fast feedback. A test suite that takes 45 minutes to complete won't gate your PRs. Engineers will merge without waiting. The feedback loop breaks. For continuous testing to work, the critical-path suite needs to run in under 10 minutes. E2E tests on modern tooling can cover your core flows in 3 to 5 minutes if they're well-scoped.
Minimal maintenance overhead. This is the constraint that determines whether your testing practice survives past the first quarter. If tests break every time the UI changes, someone has to fix them. For a team without dedicated QA, "someone" is an engineer who was supposed to be building features. The maintenance burden must be low enough to be absorbed by the team without derailing sprints.
The right testing layers for lean teams. The traditional testing pyramid prescribes 70% unit tests, 20% integration tests, 10% E2E tests. That ratio was designed for large organizations with dedicated QA capacity. For a team of 5 to 15 engineers, the highest-leverage starting point is end-to-end testing of your 3 to 5 critical flows. These tests verify what your users actually experience. Unit tests are valuable for complex business logic, and integration tests fill the gap between units and user flows, but E2E coverage of your critical paths is where the risk reduction per test is highest.
Where does your team fall? Most teams that have tried and abandoned test automation are stuck between Level 1 and Level 2. The jump from Level 2 to Level 3 is where continuous testing starts paying for itself.
| Level | Description | What It Looks Like |
|---|---|---|
| Level 0 | No automated tests | Manual QA before releases, production bugs found by users |
| Level 1 | Some tests, run manually | A few Playwright or Cypress scripts someone wrote, run locally before big deploys |
| Level 2 | Tests in CI, not gating | Tests run on PRs but failures don't block merges. Suite is often red and ignored |
| Level 3 | Tests gate merges on critical flows | 3-5 critical flows tested on every PR. Failures block merges. Suite stays green |
| Level 4 | Comprehensive coverage, auto-maintained | Broad flow coverage that updates automatically as the codebase evolves. Zero maintenance burden |
The goal is not to reach Level 4 immediately. The goal is to get to Level 3 and stay there. Level 3 is where the ROI inflection happens: enough coverage to catch real regressions, structured enough to be trusted, lean enough to be sustainable.
The Test Automation Framework Question
Most discussions of test automation immediately turn into debates about frameworks: Playwright or Cypress? Selenium or something newer? Should we write in Python or TypeScript?
For small teams, this is the wrong question to be stuck on. The framework matters less than the maintenance model.
Playwright is excellent. It's well-maintained, fast, multi-browser, and has good TypeScript support. If you have engineers who want to write and maintain Playwright tests, it's a strong choice. The same is broadly true of Cypress. Both tools can support a solid continuous testing practice.
The catch is that both require someone to write the tests, keep them updated as the product evolves, fix them when they break, and manage the infrastructure to run them. For a team with 8 engineers all building features, this typically means test maintenance falls to whoever wrote the tests originally, which means it gets deprioritized whenever sprint pressure increases. Within a few months, the suite is stale.
On the CI infrastructure side, GitHub Actions is the most common choice for small teams. It's free for public repos and straightforward to configure. GitLab CI and CircleCI are solid alternatives. The CI provider runs your tests; the question is what generates and maintains those tests. A test automation framework is a tool. The question for lean teams is not which tool is best but who maintains it and when. That's the question most framework comparisons skip.
For teams that want continuous testing without the maintenance tax, agentic testing platforms like Autonoma sit at the other end of the spectrum: tests are generated from your codebase and maintained automatically, with no scripts to write or repair.
Why Test Automation ROI Turns Negative for Many Teams
The promise of test automation is straightforward: spend time writing tests now, save time debugging bugs later. The ROI depends on the ratio of bugs caught to maintenance cost.
For a stable application with a slow-moving UI, this ratio is favorable. You write the tests once, they run for months without needing attention, and they catch regressions reliably. Traditional scripted automation works well here.
For a fast-moving product (which describes most teams between seed and Series B), this ratio inverts. The UI changes constantly. New features change existing flows. Designers iterate. The tests break not because something is wrong with your application but because something changed. Every change requires a maintenance pass. The "save time debugging bugs" side of the equation never materializes because the maintenance cost consumes all the time you saved.
This is why teams that adopt test automation often abandon it within six months. Not because testing doesn't work. Because the maintenance cost exceeded the benefit for their specific situation: a small team with a fast-moving product.
The ROI equation for test automation has a variable that most frameworks can't fix: maintenance cost. Reducing that variable is the only way to make automated testing genuinely sustainable for lean teams.
| Dimension | No Testing | Scripted Test Automation | Agentic Testing |
|---|---|---|---|
| Maintenance cost | None | High (grows with product changes) | Near-zero (auto-maintained) |
| Bug detection speed | Hours to days (found in production) | Minutes (found in CI) | Minutes (found in CI) |
| Engineering time required | None upfront, heavy ongoing (bug fixes) | Heavy upfront + ongoing maintenance | Minimal setup, no ongoing maintenance |
| ROI timeline | Negative by month 6-12 | Positive if stable product, negative if fast-moving | Positive within weeks |
| Best for | Throwaway prototypes only | Stable products with QA capacity | Fast-moving teams without dedicated QA |
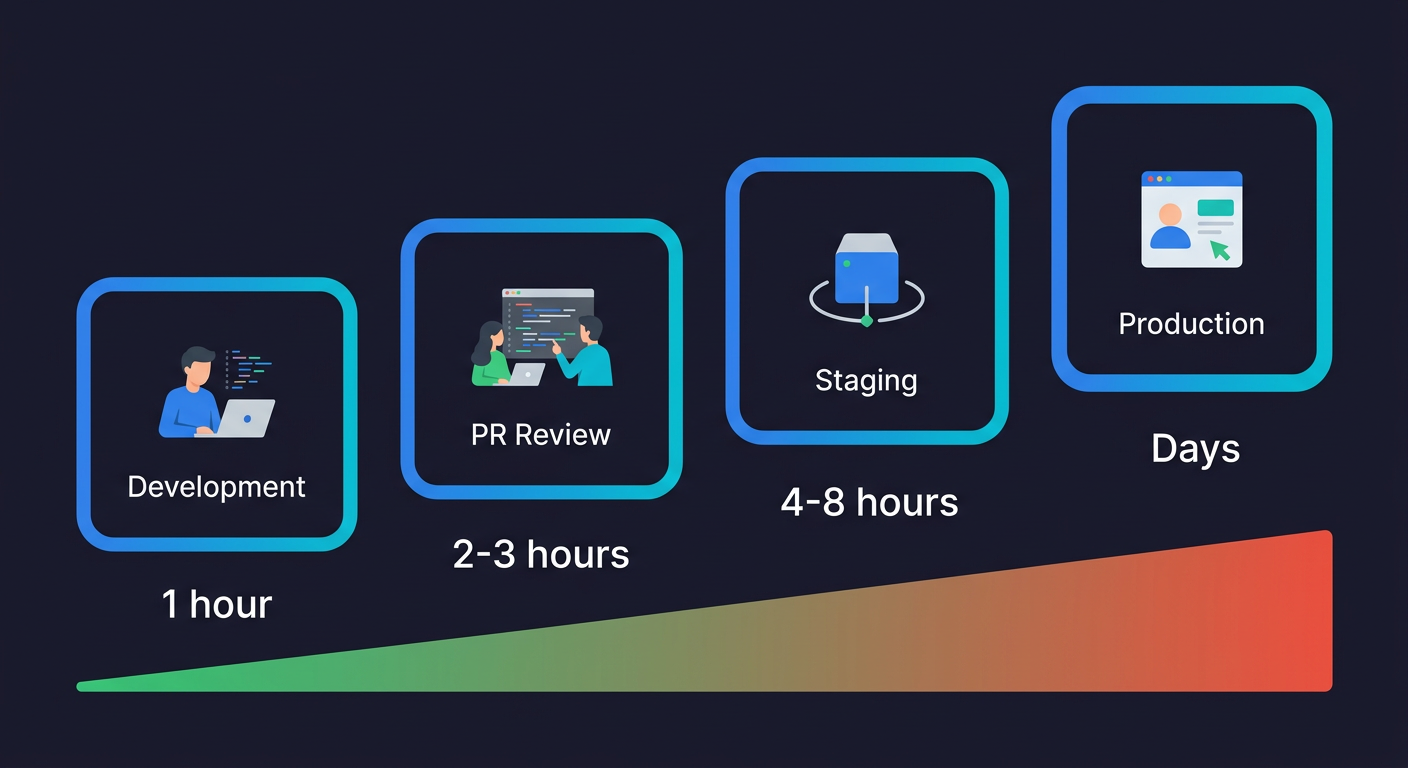
Shift Left Testing: Catching Bugs Earlier in the Cycle
"Shift left" refers to moving testing earlier in the development process. Instead of testing at the end (the right side of the development timeline), you test at the beginning (the left side). The earlier a bug is found, the cheaper it is to fix.
The economics are stark.
| Stage Where Bug Is Found | Typical Cost to Fix | Impact |
|---|---|---|
| During development | ~1 engineer-hour | Minimal disruption |
| PR review | 2-3 hours | Context switch, review cycle, re-review |
| Staging | 4-8 hours | Release delay, broader investigation |
| Production | Days | Incident response, root cause analysis, hotfix, customer communication |
These numbers are consistent across industry research on defect cost escalation. The later a bug is found, the more context is lost and the more systems are affected.
Shift-left testing is not just about writing tests. It's about integrating testing into the development workflow so bugs surface at the point where they're cheapest to fix. For most teams, this means tests that run in CI on every PR, before code merges.
The challenge is doing this without slowing the development workflow. A PR that takes 40 minutes to get a test result is one that engineers will start bypassing. Shift left only works if the feedback is fast. For critical-path continuous testing, targeting under 10 minutes for the core suite is a practical benchmark.
CI/CD Testing: The Infrastructure You Actually Need
CI/CD testing is not complex to set up for a small team. The infrastructure overhead gets overstated. Here is what you actually need.
A CI provider. GitHub Actions is free for public repos and reasonably priced for private ones. Most small teams already have it. GitLab CI, CircleCI, and others work equally well. The choice matters less than having something.
A test suite that runs without manual intervention. Your tests need to execute in a clean, reproducible environment. If they require a specific database state or external service, those need to be handled in the CI setup (mocked, seeded, or using test credentials). Tests that only run on a developer's local machine are not CI tests.
A merge gate. Tests should block merges when they fail. A test suite that runs but doesn't block anything is informational noise. The whole point is structural enforcement: broken tests mean broken code, and broken code doesn't merge. This is what makes continuous testing continuous rather than aspirational.
Here is a minimal GitHub Actions workflow that runs E2E tests on every pull request:
name: E2E Tests
on:
pull_request:
branches: [main]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: 20
- run: npm ci
- run: npx playwright install --with-deps
- run: npm run build
- run: npx playwright testThat's 15 lines. Once your functional tests are running, consider adding security scanning to the same pipeline. Static application security testing (SAST) tools like Semgrep or CodeQL can run alongside your E2E tests, catching common vulnerabilities (SQL injection, XSS, insecure dependencies) before they reach production. For a small team without a dedicated security function, this is the most practical way to get continuous security testing without adding process.
The complexity people associate with CI/CD testing usually comes from maintaining the tests themselves, not from the infrastructure. With the infrastructure handled by your CI provider, the only ongoing cost is keeping tests current.
How Agentic Testing Changes the Maintenance Equation
The maintenance cost problem is what we built Autonoma to solve. Autonoma is open source and self-hostable, with a free tier and a $499/mo cloud option.
The traditional model for continuous testing requires engineers to write test scripts, maintain selectors, update flows after UI changes, and triage failures after every sprint. For a 10-person team, this means someone is perpetually on test maintenance duty, usually at the expense of feature work.
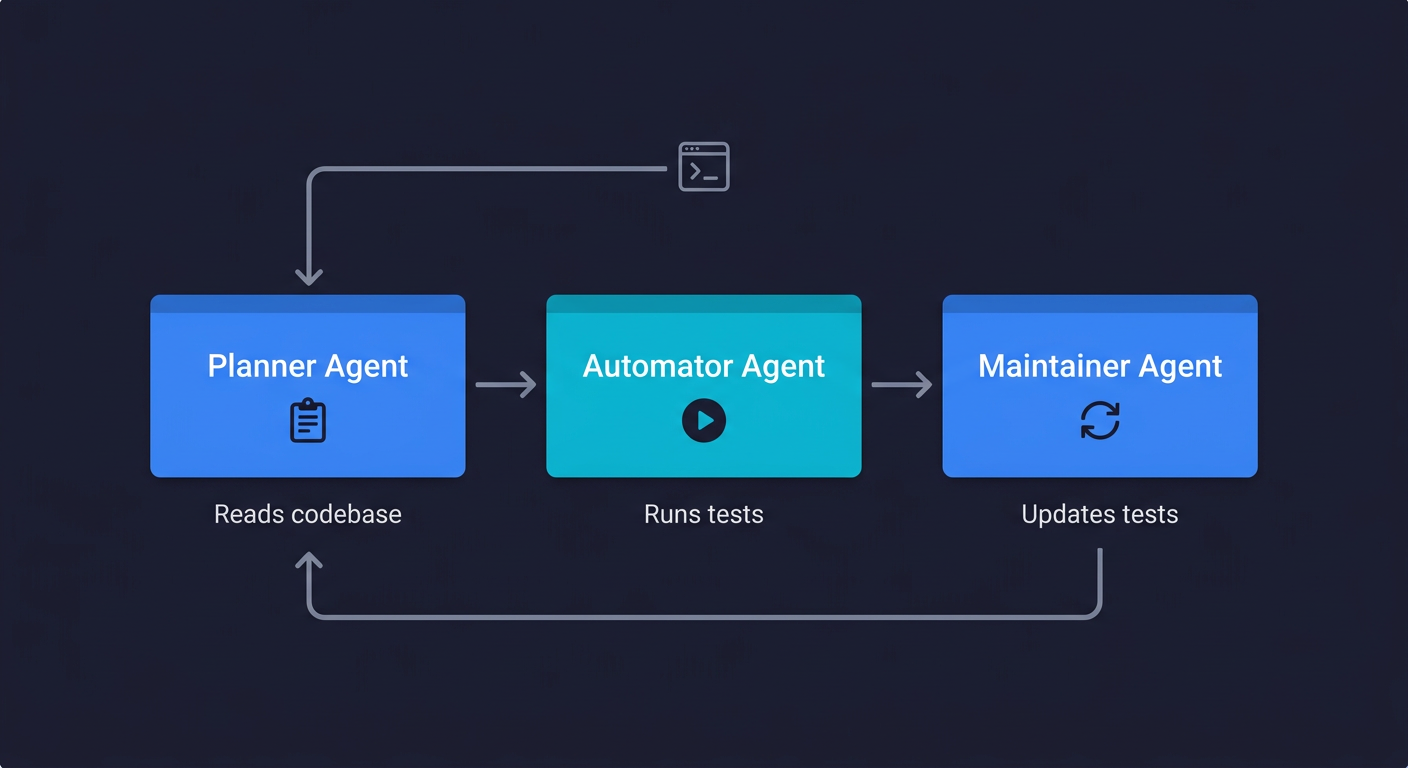
Autonoma works differently. You connect your codebase. A Planner agent reads your routes, components, and user flows and generates test cases directly from the code. An Automator agent executes those tests against your running application. A Maintainer agent monitors code changes and updates tests automatically when the application evolves.
The critical difference is where the test definition lives. Traditional scripts encode what the UI looked like on the day the test was written. Autonoma derives tests from the codebase itself. When your code changes, the Maintainer agent re-reads the codebase, understands what changed, and updates tests accordingly. The test doesn't break because a CSS class changed. It adapts because the agent understands the application, not just the UI surface.
For teams that have tried scripted continuous testing and abandoned it because of maintenance cost, this is the change that makes the economics work. Tests don't go stale. Engineers don't spend sprint time fixing broken selectors. The coverage expands as the product grows, automatically.
The hands-off aspect matters particularly for teams between 5 and 20 engineers where no single person can own testing full-time. The agents handle what would otherwise require a dedicated QA function.
Building a Practical Continuous Testing Practice
If you're starting from near zero, here is the sequence that works for small teams.
Start with your highest-risk flows (Week 1-2). Pick three to five user flows that, if broken, would constitute a serious production incident. For most products: signup/login, the core activation flow, checkout or billing if you have it, and any API endpoint that external customers depend on. These are your initial targets for continuous testing coverage.
Get those flows covered and running in CI (Week 3-4). Whether you use Playwright, Cypress, or an agentic platform like Autonoma, get automated coverage on those critical flows and integrate it into your CI pipeline as a merge gate. This step alone eliminates the majority of production regressions for most small teams.
Don't expand until what you have is stable (Month 2-3). The instinct is to add more tests immediately. Resist it. A small suite of stable, trusted tests is worth more than a large suite with intermittent failures. Once your initial coverage is running cleanly for a month with no false positives, start expanding.
Treat maintenance cost as a first-class metric (Ongoing). Track how much engineering time goes to fixing broken tests per sprint. If that number exceeds two to three hours per week for a 10-person team, your maintenance model is not sustainable and you should either reduce the scope or change your tooling. For QA automation without a QA team, keeping this number low is the difference between a practice that survives and one that gets abandoned.
Integrate with your PR workflow (Week 3-4). Tests should run automatically on PR open and update on every push. Status checks should be required before merging. This is the structural enforcement that makes continuous testing genuinely continuous rather than something you remember to do before big releases.

When Test Automation Feels Slow, Change the Model
The argument against testing is usually framed as a velocity trade-off: time spent on tests is time not spent on features. The faster you need to move, the less time you can afford to spend on testing.
This framing treats testing as a tax on development velocity rather than an investment in it. The teams that ship fastest are not the ones that skip testing. They're the ones that have made testing fast enough to be invisible in the development workflow.
A PR that passes CI in 6 minutes and merges clean is faster than a PR that merges without tests and generates a production bug three days later. The bug cost is just deferred and amplified.
The question is never "should we test?" The question is "what's the cheapest way to test that our critical flows still work?" The answer has changed. Writing and maintaining scripts is no longer the only option. An agentic platform that reads your codebase and generates tests automatically is now available, and for lean teams, it changes the trade-off calculation entirely.
Teams wondering how to speed up testing should focus on eliminating script maintenance, not writing faster scripts. Testing doesn't have to slow you down. The version of test automation that slows teams down is the version where engineers write and maintain scripts by hand. Remove that cost, and continuous testing becomes the thing that lets you ship faster, not slower.
Frequently Asked Questions
Continuous testing is the practice of running automated tests throughout the entire software development lifecycle, not just before release. Tests run on every commit and pull request in a CI pipeline, catching bugs within minutes of introduction rather than days or weeks later. The goal is to compress the feedback loop between writing code and discovering that it broke something.
Scripted test automation slows teams down when the maintenance cost of keeping tests current exceeds the time saved by catching bugs automatically. This typically happens within 3 to 6 months for fast-moving products using traditional tools like Playwright or Cypress. Agentic testing platforms that generate and maintain tests automatically eliminate this maintenance cost, making test automation a net positive for velocity even for lean teams.
The best test automation framework for a small team depends on how much maintenance capacity you have. Playwright and Cypress are both strong choices if you have engineers willing to write and maintain scripts. If test maintenance is the constraint, an agentic platform like Autonoma generates and maintains tests automatically from your codebase, which is a better fit for teams without dedicated QA capacity.
Shift left testing means moving testing earlier in the development process, so bugs are found at the point where they are cheapest to fix. A bug caught during development costs roughly one engineer-hour to fix. The same bug in production can cost days. Shift left testing is achieved by running automated tests in CI on every pull request, before code merges to the main branch.
To integrate continuous testing into CI/CD: (1) Pick a CI provider (GitHub Actions is the most common for small teams). (2) Write or generate automated tests for your critical user flows. (3) Configure your CI to run tests automatically on pull requests. (4) Set the test results as required status checks that block merges when they fail. The infrastructure is straightforward. The ongoing cost is keeping tests current as your product changes.
Start with 3 to 5 critical user flows: signup, core activation, checkout, and any API your users depend on. That typically translates to 10 to 30 tests. This scope covers the majority of production regressions for most products without creating an unmanageable maintenance burden. Expand after your initial coverage is stable and trusted. More tests are only valuable if they stay current.
Test automation ROI is positive when the cost of bugs caught exceeds the cost of writing and maintaining the tests. For stable products with slow-moving UIs, this ratio is typically favorable with traditional scripted tools. For fast-moving products (most teams between seed and Series B), the maintenance cost often exceeds the benefit. Agentic testing changes this by eliminating maintenance cost, making the ROI positive regardless of how fast the product is evolving.
Agentic testing uses AI agents that read your codebase, generate tests from your routes and components, execute those tests against your application, and update them automatically when code changes. Traditional test automation requires engineers to write test scripts that encode specific UI selectors and step sequences, then manually update those scripts whenever the UI changes. The key difference is maintenance: traditional scripts break when the product changes, agentic tests adapt.
For a small team starting from zero, expect 1-2 weeks to identify critical flows and set up initial coverage, another 1-2 weeks to integrate into CI as a merge gate, and 2-3 months to stabilize and build trust in the suite before expanding. With an agentic platform like Autonoma, the setup phase compresses significantly because tests are generated automatically from your codebase rather than written by hand.
The leading continuous testing tools include Autonoma (codebase-driven agentic testing with zero maintenance), Playwright (powerful scripted browser testing), Cypress (developer-friendly E2E testing), Selenium (cross-browser scripted testing for large suites), and GitHub Actions or GitLab CI (CI infrastructure to run any of these automatically on every commit). For lean teams that need continuous testing without dedicated QA capacity, Autonoma is the most sustainable choice.



