
Vibe coding security risks are real and frequently invisible. Vibe coding tools like Lovable, Bolt, and Base44 let non-engineers ship full applications from plain-language prompts. 53% of teams that shipped AI-generated code later discovered security issues that passed initial review. Across 5,600 vibe-coded apps, researchers found over 2,000 vulnerabilities, 400+ exposed secrets, and 175 instances of exposed PII. Security scanners find known vulnerability patterns in static code. They do not test whether your application actually behaves correctly. Automated testing is the missing layer that catches what scanners cannot: broken auth flows, exposed data through legitimate endpoints, and logic errors that only appear at runtime.
Ten months ago, a developer on the Lovable community forum posted something that made security engineers wince. He had shipped a fully functional B2B SaaS product in a weekend using Lovable. It was live, it had paying customers, and he was proud of it. He had also run it through a security scanner. Clean bill of health. Two weeks later, a researcher pointed out that his Supabase credentials were embedded directly in the client-side bundle, visible to anyone who opened DevTools. He was not an outlier. The same researcher found the same pattern in 10 out of 38 Lovable-built apps they reviewed.
The tool did not fail him. The scanner did not lie. The app just behaved in ways neither was designed to catch.
Vibe Coding Security Risks: The Scale of the Problem
Vibe coding tools have done something genuinely remarkable. They collapsed the gap between "I have an idea" and "there is a working app." A founder who cannot write a line of code can now describe a user dashboard and get a functional React application connected to a real database. The tools handle routing, authentication boilerplate, API design, and deployment. The promise is real and it is being delivered every day.
The security problem underneath that promise is also real.
In a survey of developers who had shipped AI-generated code, 53% reported discovering security issues that had passed initial review. These were not hypothetical risks identified by automated scanners. They were real vulnerabilities found after the code was already running in production. Research from Georgetown's CSET found that 86% of AI-generated code failed XSS defense mechanisms, and a separate analysis found that 45% of AI-generated code samples introduced OWASP Top 10 vulnerabilities. CodeRabbit's report confirmed the pattern: AI-generated code is 2.74x more likely to introduce XSS vulnerabilities than human-written code. (For the broader quality picture beyond security, including how these defects compound in the vibe coding testing gap, see our companion piece.)
The Escape.tech study of vibe-coded applications gave the most detailed picture. Scanning 5,600 apps built with vibe coding tools, they found over 2,000 vulnerabilities. More alarming than the raw count: 400+ exposed secrets (API keys, credentials, tokens sitting in accessible code) and 175 instances of personally identifiable information exposed through app endpoints. The DEV Community ran a smaller but consistent study, finding 318 vulnerabilities across just 100 vibe-coded apps scanned.
The Moltbook breach made these statistics concrete. Wiz researchers discovered that Moltbook, an AI agent social network, had exposed 1.5 million API authentication tokens, 35,000+ email addresses, and 4,060 private messages, including third-party API credentials shared between agents. The founder had stated publicly: "I didn't write a single line of code for Moltbook. I just had a vision for the technical architecture, and AI made it a reality." The root cause was not a code pattern that any scanner would flag. Moltbook's Supabase public API key was embedded in the client-side bundle, which is a common and normally acceptable configuration. What made it catastrophic was that Row Level Security (RLS) was disabled on the database. With RLS properly configured, the public key is safe. Without it, that key grants full unauthenticated read and write access to every table. A static scanner examining the code would see a credential in the bundle and possibly flag it, but it could not verify whether the database access controls that make that credential safe were actually active. A behavioral test that authenticated as one user and attempted to read another user's data directly through the API would have caught the missing RLS policies immediately.
There is a category of vibe coding vulnerability that gets less attention but carries equal risk: supply-chain issues. AI code generators frequently suggest packages that are deprecated, have known CVEs, or in some cases do not exist at all. When a model hallucinates a package name, an attacker can register that name and publish malicious code under it. Anyone who follows the AI's recommendation installs the attacker's package. Vibe coding tools also tend to leave dependency versions unpinned, which means a compromised update can silently enter a project without any code change on the developer's side. These risks are invisible to application-level security scanners because the vulnerability is in the dependency, not in the code that imports it.

These numbers deserve some context before jumping to conclusions. AI-generated code is not uniquely insecure. It makes predictable, consistent mistakes. It optimizes for "does this work?" and not "is this safe?" AI coding tools do not spontaneously add rate limiting, parameterized queries, or authentication guards unless explicitly prompted. They produce code that is functionally correct and structurally vulnerable, and that specific combination is what makes the risk hard to catch.
Why Security Scanners Are Not Enough
The standard advice after reading those statistics is "scan your code." Run SAST tools. Use Snyk or Semgrep. Check for known vulnerability patterns before you ship. This advice is correct and incomplete. Here is why.
Security scanners are pattern matchers. They read your static code and compare it against a database of known vulnerability signatures. They are very good at finding things like hardcoded secrets in environment files, use of deprecated cryptographic functions, SQL string concatenation that could enable injection, and dependency versions with published CVEs. If the code has a textbook SQL injection pattern, a decent scanner will catch it.
What scanners cannot do is run your application. They cannot log in as a user, navigate to the settings page, and try to access another user's data by changing the ID in the URL. They cannot submit a form with unexpected input and observe whether the server validates it on the backend or only on the frontend. They cannot click through a multi-step checkout flow and verify that the payment is actually authorized before the order is confirmed.
This distinction matters enormously for vibe-coded apps because the most dangerous vulnerabilities in those apps are frequently behavioral, not structural. Consider the real vulnerability categories that scanners systematically miss.
Broken object-level authorization (BOLA/IDOR, CWE-639) exploited through legitimate endpoints. This is the most common critical vulnerability in APIs, and scanners almost never catch it. Your code has an endpoint: GET /api/invoices/:id. The scanner reads the code and sees that the endpoint exists and returns data. What the scanner cannot verify is whether the server checks that the requesting user owns the invoice with that ID. The code might look like proper authentication is enforced. At runtime, it might not be. Only a test that actually calls the endpoint as a different user can verify the authorization check actually works.
Auth flows that pass static review but fail dynamically (CWE-613). Consider a password reset flow. The scanner looks at the token generation code, sees it uses a secure random function, and marks it clean. What the scanner cannot check: Does the token actually expire? Can it be reused after the password is changed? Is the old token invalidated when a new one is issued? These are behavioral questions. They require running the flow.
Frontend validation without backend enforcement (CWE-602). Vibe-coded apps frequently implement validation logic in the React component and nowhere else. The scanner reads the component, sees the validation logic, and considers the field validated. The actual API endpoint has no server-side validation. An attacker who calls the API directly bypasses every protection entirely. Testing catches this because a good test calls the API directly, not through the form.
Race conditions in financial or state-critical operations (CWE-362). If two requests hit a "redeem coupon" endpoint simultaneously, does the application handle them correctly? Static code analysis has no way to simulate concurrent requests. A test suite can.
Business logic errors that are invisible to pattern matching. If your free plan allows 5 projects but the limit check runs at creation time and not at upgrade time, a user can create 100 projects by timing their upgrade correctly. No scanner has a signature for "this business rule is not enforced consistently." A test that exercises the upgrade flow at the right moment does.
The Base44 vulnerability illustrates the ceiling of scanner-only approaches at a different level: it was a vulnerability in the platform itself, not in the generated code. The flaw allowed unauthorized users to bypass access controls and register for private applications, exposing every app built on the platform regardless of how carefully the generated code had been reviewed. Base44 patched it within 24 hours, but the window of exposure was real. Users who trusted that the output had been scanned for issues were exposed to a risk that no amount of scanning their own app would have caught.
The Development Environment Is Also an Attack Surface
The security conversation around vibe coding typically focuses on the code that gets generated. The tools doing the generating are themselves a risk layer that rarely gets discussed.
CVE-2025-54135 (CurXecute) made this concrete. Researchers at AIM Security disclosed a vulnerability in Cursor, the AI code editor, that allowed remote code execution on developers' machines without any user interaction. The flaw exploited Cursor's Model Context Protocol (MCP) auto-start functionality: an attacker could send a crafted message through a connected MCP server (such as a Slack integration), which would silently rewrite Cursor's global configuration and execute attacker-controlled commands before the developer had a chance to review or reject anything. Cursor runs with developer-level privileges, so the blast radius was the entire development machine.
MCP servers more broadly have accumulated a significant CVE backlog. A critical vulnerability in the widely-used mcp-remote package (downloaded over 437,000 times) allowed remote code execution when a developer's environment connected to an untrusted MCP server. Separate vulnerabilities in the Framelink Figma MCP Server and Anthropic's own Filesystem MCP Server allowed attackers to read and write files outside of approved directories.
The implication for vibe coding workflows is straightforward: the attack surface does not begin at the application you are building. It begins at the tool you are using to build it. This is yet another dimension that static code scanners cannot cover. Behavioral testing of the application you ship does not protect against a compromised development environment, but it does mean that even if an attacker modifies your code during development, the tests will catch the resulting behavioral changes before they reach users.

| Vulnerability Type | What Scanners See | What Testing Catches |
|---|---|---|
| BOLA / IDOR (CWE-639) | Endpoint exists and returns data | Endpoint returns User B's data to User A |
| Frontend-only validation (CWE-602) | Validation logic present in component | API accepts invalid input when called directly |
| Auth flow failures (CWE-613) | Secure token generation function used | Token never expires or can be reused after reset |
| Race conditions (CWE-362) | No detection capability | Concurrent requests bypass single-use checks |
| Business logic errors | No signature for incorrect business rules | Free-tier user exceeds limits via direct API call |
| Exposed credentials (CWE-798) | Finds hardcoded secrets in source files | Finds credentials accessible in deployed bundle |
The distinction matters most for vibe-coded apps: the security failures that reach users are overwhelmingly behavioral, not structural, and behavior is what tests observe. Autonoma generates end-to-end behavioral tests from your codebase that cover the authorization flows, input validation, and business logic enforcement that scanners cannot verify.
Testing: The Missing AI Code Security Layer
The testing approaches that close the gap scanners leave are not exotic. They are the standard practices of every well-run engineering team, applied specifically to the failure modes of AI-generated code.
End-to-end authentication testing is the highest-value starting point. Write tests that exercise every authentication path: login with valid credentials, login with invalid credentials, access to protected routes without a session, access with an expired session, and account lockout behavior. These tests do not require deep security expertise. They require treating authentication as a feature with expected behavior and verifying that behavior.
The value is in what they catch. A test that attempts to access /dashboard without a valid session and verifies the response is a 401, not a 200, catches the authentication misconfiguration that looks fine in static code. Lovable and similar tools generate authentication boilerplate that often passes visual code review. The test does not care how the code looks. It cares what the server returns.
Authorization testing across user boundaries is where BOLA/IDOR vulnerabilities get caught. For every endpoint that returns or modifies user-scoped data, write a test that authenticates as User A, retrieves a resource ID belonging to User B, and verifies the response is a 403. This pattern takes minutes to write once you have your test framework set up. It is the single most effective test for the most common API vulnerability class.
A vibe-coded app that generates a /users/:id/documents endpoint might look like it has authorization because the route handler checks for a session. The test verifies whether it checks that the session belongs to the right user.
Input validation testing at the API layer (not the form layer). For every data-accepting endpoint, write tests that send inputs the frontend would never send: empty strings where the UI requires values, strings over the expected length, SQL fragments, script tags, negative numbers where positive is expected, and missing required fields. These tests run against the API directly. They bypass the frontend validation entirely.
The gap they close: vibe coding tools routinely implement validation in the component and skip it in the API handler. The form test passes. The API test fails. That failure is a real vulnerability.
State integrity tests for multi-step flows. For checkout flows, subscription management, file uploads with processing, and any other multi-step process, test the intermediate states explicitly. Can a user skip step 2 of a 3-step checkout by calling the step 3 endpoint directly? Does the system correctly handle a user refreshing the page mid-flow? These edge cases cause bugs and security issues equally, and neither scanners nor happy-path tests catch them.
Permission boundary tests for feature flags and plan limits. If your app has a free tier with limits, test that the limits are enforced server-side. Create a free-tier user, hit the limit, then attempt to exceed it by calling the API directly. Vibe-coded apps routinely enforce these limits only in the UI. A test discovers that in seconds.
This is where Autonoma fits as the testing layer that scanners cannot replace. Security scanning finds known vulnerability patterns in your static code. Autonoma connects to your codebase and generates end-to-end tests that verify your application actually behaves correctly, including the authorization checks, input handling, and business logic enforcement that only appear at runtime. The two tools answer different questions and neither makes the other redundant. See how agentic testing works for a deeper look at the approach.
How to Secure a Vibe-Coded App: A Practical Testing Playbook
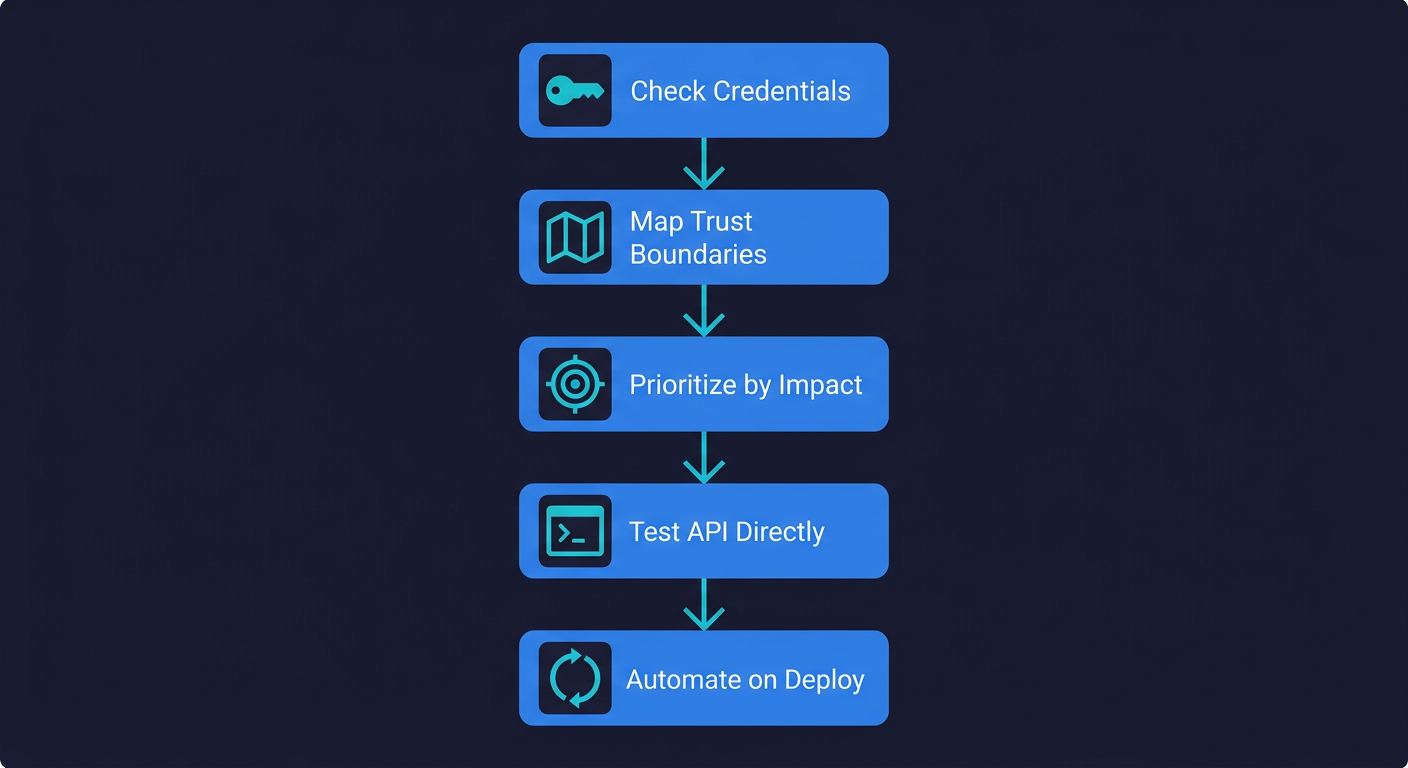
If you have built or are building with a vibe coding tool and want to close the security gap systematically, here is where to start. For the broader picture of why vibe coding creates a structural testing void, including a severity scale for assessing your own risk, see our companion article.
If you are a startup founder navigating these trade-offs, our guide on vibe coding at startups covers the full decision framework for when to vibe code, when to stop, and what to automate.
Before you do anything else: check for exposed credentials. Run a search across your repository and your deployed frontend bundle for any strings matching the pattern of your database connection strings, API keys, and service tokens. This takes five minutes and addresses the most immediately dangerous category of vibe coding vulnerability, the one that affected 400+ apps in the Escape.tech study and 10 of the 38 Lovable apps reviewed independently. If your Supabase URL and anon key appear in your client-side bundle, they are public. The anon key being "designed to be public" is not a complete defense if your row-level security policies have gaps. Verify those too.
Map your trust boundaries. Draw (or just list) every endpoint in your application that accepts input or returns data. For each one, answer: What authentication is required? What authorization check prevents one user from accessing another user's data? What input validation runs on the server (not just the client)? This mapping exercise will surface the gaps before any test is written.
Prioritize your test writing by impact. Not all endpoints carry equal risk. Authentication endpoints, payment flows, user data endpoints, and admin functionality have the highest blast radius if they behave incorrectly. Write tests for these first, before anything else. A broken profile photo upload is annoying. A broken authorization check on your billing endpoint is a breach.
Use your test framework to call the API directly. Do not test your security through your UI. UI tests are valuable for functional flows, but they always inherit the frontend's assumptions about what the user can and cannot do. Security tests should call your API with raw requests, bypassing the frontend entirely. In Playwright, this looks like using request.get() and request.post() directly. In any framework, the pattern is the same: authenticate, get a token, make direct API calls, assert on the response.
Build a regression test for every bug you find. When a scanner flags a vulnerability or manual review uncovers an issue, write a test that would have caught it before fixing it. Run that test. Watch it fail. Fix the vulnerability. Watch it pass. That test now lives in your suite permanently and will catch any regression of the same class. Over time, this builds a security regression suite that is specific to your application's actual failure modes, not generic vulnerability signatures.
Run your tests on every deploy, not just before launch. Vibe-coded apps often evolve rapidly. A prompt that regenerates a component can silently change the authorization logic in that component. Tests that run only at launch miss the ongoing regression risk. Set up your CI pipeline to run the security-focused tests on every pull request and every deploy. Continuous testing is what makes the investment in writing these tests compound over time.
The cost of not testing is not abstract for vibe-coded apps. It is a specific, quantifiable risk: a production incident, a credential rotation scramble, a data exposure notification, or a platform vulnerability you had no visibility into until it was too late.
The Speed Paradox: Why Testing Makes Vibe Coding Faster
The objection to all of this is predictable: "I'm using vibe coding because I want to move fast. Adding tests slows me down."
This is the wrong frame. The question is not whether tests slow down the first deploy. They do, marginally. The question is what happens to the second, fifth, and twentieth deploy.
A vibe coding workflow without tests looks like this: ship fast, discover bug in production, spend two days debugging and hotfixing, ship a fix, hope nothing else broke. Each incident response cycle consumes more time than the initial time savings from skipping tests. The real cost of a production bug at a small startup runs $8,000 to $25,000 when you account for engineering hours, customer impact, and opportunity cost.
A vibe coding workflow with automated tests looks different. The tests catch the authorization hole before the deploy. The developer sees a failing test, prompts the tool to fix the specific issue the test describes, and ships the corrected version. The entire cycle takes minutes instead of days. The customer never sees the vulnerability.
The iteration risk compounds in a way that is not obvious. Kaspersky research had GPT-4o modify existing code across multiple rounds while scanning each version after every iteration. After just five revisions, the code contained 37% more critical vulnerabilities than the initial generation. Feature-focused prompt iterations produced 158 new vulnerabilities across the test set, including 29 critical ones. Even prompts that explicitly emphasized secure coding still introduced 38 new vulnerabilities, seven of them critical. The implication for vibe coding is uncomfortable: each iteration without continuous testing does not maintain risk at a steady level. It compounds it. The developer who iterates on a vibe-coded app 20 times before shipping has likely ended up with a less secure codebase than the one generated on the first prompt, not because the tool got worse, but because incremental changes introduced incremental gaps that accumulated invisibly.
There is a deeper version of the speed paradox. Vibe coding tools are genuinely excellent at fixing specific, well-described bugs. "The test at line 42 verifies that a user cannot access another user's invoices. It is failing because the endpoint returns 200 instead of 403. Fix the authorization check in the invoice endpoint." That prompt produces a targeted fix. Compare it to "Something is wrong with how invoices work, some users might be seeing other users' data" which produces unfocused investigation.
Tests make the feedback loop faster, not slower. A failing test is a precise bug report. A production incident is an investigation that might run for hours before you even know what broke.
This is part of the broader vibe coding bubble: a verification gap where building has been democratized but testing has not, and security is the sharpest edge of that gap. It is also why the AI coding agent testing gap is a compounding problem rather than a one-time risk. Every iteration of a vibe-coded app that ships without tests adds more untested surface area. Every iteration that ships with tests tightens the feedback loop and accelerates the next iteration.
The teams getting the most out of vibe coding tools are not the ones who skip testing to go faster. They are the ones who treat testing as part of the prompt engineering workflow. The tool generates code. The tests verify the behavior. When the tests fail, the tool fixes the specific issue the tests describe. That loop is faster than any debugging session.
No. The security risks in vibe-coded applications are not platform-specific, though some platforms have had more publicly documented issues. The 53% figure spans developers using a range of tools. The underlying cause is consistent across platforms: AI code generators optimize for functional correctness and rely on the developer to specify security requirements explicitly. When security is not specified, it is often omitted. The Lovable credential exposure issue and the Base44 platform vulnerability represent different risk categories (generated code behavior vs. platform infrastructure), but both illustrate that the risk exists regardless of which specific tool you are using. Testing your application's behavior is necessary regardless of which vibe coding tool generated the code.
The vulnerabilities scanners most consistently miss are behavioral rather than structural. Broken object-level authorization (BOLA/IDOR) is the top category: code that looks like it checks authorization but does not enforce it correctly at runtime. Frontend-only input validation is the second most common: the form validates correctly, the API endpoint does not. Missing server-side session expiration, reusable password reset tokens, and plan limit enforcement only in the UI round out the top categories. All of these require running the application and observing its behavior, which static scanners cannot do. The best tools for finding these vulnerabilities are [Autonoma](https://getautonoma.com) for automated end-to-end behavioral testing, and purpose-built DAST (dynamic application security testing) tools for automated runtime scanning.
A complete security review of a vibe-coded app requires two distinct approaches. Static analysis (SAST) tools like Snyk, Semgrep, or GitHub Advanced Security scan your code for known vulnerability patterns: exposed credentials, dependency CVEs, injection patterns, and insecure cryptographic usage. These run against the code itself. Dynamic testing covers behavioral vulnerabilities that only appear at runtime: authorization checks, input validation enforcement, session management, and business logic errors. [Autonoma](https://getautonoma.com) generates end-to-end tests from your codebase that verify your application's actual behavior across these categories. For a manual starting point, also check your deployed frontend bundle for any credentials or API keys, and map every API endpoint against its authentication and authorization requirements.
Vibe coding tools can produce production-ready applications, but not by default. The safety gap is not in the tools themselves but in the workflow around them. Applications built with vibe coding tools and subjected to proper security scanning and behavioral testing are no more inherently risky than applications built with traditional tools. The problem is that the vibe coding workflow encourages fast shipping without testing, and the default outputs of these tools reflect that pressure: code that works functionally but omits defensive patterns. The answer is not to avoid vibe coding tools but to close the verification gap. Run static analysis on the code, write behavioral tests for authentication and authorization flows, and set those tests to run on every deploy.
The right framework depends on your stack, but the most important factor is picking something and using it consistently. For end-to-end behavioral testing of web applications, Playwright is the leading choice in 2026 for its reliability, speed, and built-in support for API testing alongside UI testing. See the [E2E testing tools comparison](/blog/e2e-testing-tools) for a detailed breakdown. For teams who want tests generated automatically from their codebase rather than written manually, [Autonoma](https://getautonoma.com) connects to your codebase and generates tests without requiring you to write them. The zero-maintenance aspect matters especially for vibe-coded apps, which tend to evolve rapidly and would otherwise require constant test updates.



