
The cost of not testing is not zero. It shows up as engineering hours lost to debugging production bugs, customers who quietly churn after a bad experience, support tickets that drain your team, and features you didn't ship because an incident derailed the sprint. For a 10-person startup, a single production bug typically costs $8,000 to $25,000 when you account for engineering time, lost revenue, support load, and opportunity cost. Smoke testing your critical paths and adopting automated testing are not luxuries. They are the cheapest form of insurance available to early-stage engineering teams.
That range is not hypothetical. It comes from working through the actual line items on a realistic incident at a 10-person startup: engineering hours at roughly $75 per hour, lost signups during the outage window, support load during incident response, and the features that didn't ship the week the team was in firefighting mode.
Most founders look at that number and assume it applies to the big, dramatic outages. The full-day database corruption, the payment processor failure. It doesn't. It applies to a broken signup flow that sat undetected over a weekend. Smoke testing that flow takes less than an hour to set up. Automated testing of your critical paths can run continuously with no human intervention. The math is not close.
The question isn't whether your team can afford testing. It's whether you've run the numbers on what you're paying to skip it.
What a Production Bug Actually Costs a 10-Person Startup
Most founders and CTOs have an intuitive sense that production bugs are expensive. The instinct is right. The number is usually larger than expected.
Let's work through a realistic scenario. Your signup flow breaks on a Friday afternoon. New users get a 500 error. You don't notice until Monday morning when the first support ticket comes in. Three engineers spent Monday diagnosing, another half-day on the fix and hotfix deploy, and another few hours verifying it was actually resolved.
Engineering time is the line item everyone accounts for. Three engineers at roughly $150K salary each work out to around $75 per engineer per hour. A modest four-engineer incident over two days costs about $4,800 in raw engineering time. More complex incidents, the kind that require root cause analysis across multiple services, can run $10,000 to $20,000 in engineering time alone before the fix ships.
Customer trust is the line item nobody puts a number on. If your signup flow was down for a weekend, how many potential users hit that error and never came back? At a conversion rate typical for SaaS, even 50 lost signups at a $150 average contract value is $7,500 in pipeline. For a startup at Series A with meaningful traffic, a weekend outage can erase a significant portion of a month's new revenue.
Support load compounds the problem. Every affected user who does reach out generates a ticket. Your team is already in incident mode. Now someone is also triaging user complaints, writing individual responses, issuing refunds or extensions, and updating a status page. A few hours from a non-engineer or a full day from an engineer who should be working on the fix instead.
Opportunity cost is the one that stings most on reflection. The sprint where the incident happened, what didn't ship? The feature that was supposed to go out Friday got pushed to next week. That delay has a downstream cost on every other commitment in the roadmap.
| Cost Category | Low Estimate | High Estimate | Notes |
|---|---|---|---|
| Engineering time (diagnosis + fix + deploy) | $2,400 | $12,000 | 4-16 engineer-hours at $75/hr, 2-4 engineers |
| Lost signups / revenue | $1,500 | $10,000 | Depends on traffic and ACV |
| Support overhead | $500 | $2,000 | Ticket triage, responses, refunds |
| Opportunity cost (delayed features) | $3,000 | $8,000 | Sprint capacity redirected to incident |
| Total per incident | $7,400 | $32,000 | One bad bug, one weekend |
Two to four production incidents per quarter is not unusual for a startup shipping without testing. That's $15,000 to $130,000 annually in incident cost alone, before you factor in the slower velocity and compounding technical debt. These numbers align with broader industry research: the National Institute of Standards and Technology (NIST) found that defects caught in production cost up to 30 times more to fix than those caught during development. The Stripe Developer Coefficient report estimated that developers spend 33% of their time dealing with technical debt and bad code, a figure that climbs fast at startups without automated testing in place.
Why Startups Skip Automated Testing (And Why the Reasoning Is Flawed)
The decision to skip testing is almost always framed as a velocity trade-off. Tests take time to write. Writing tests means shipping features more slowly. In a pre-product-market-fit environment, shipping fast matters more than building quality infrastructure.
This reasoning is directionally right about one thing: badly implemented test automation does slow teams down. Handwritten test scripts that break every time a designer renames a button, Selenium suites that require a dedicated engineer to maintain, brittle E2E flows that go red every sprint and get ignored. All of these are real, and all of them genuinely consume engineering time that could go toward features.
The flaw is that this reasoning conflates "tests as we've seen them done" with "tests as they need to be." There's an assumption baked in that testing necessarily means writing and maintaining scripts. That assumption was accurate for a long time. It isn't anymore.
The second flaw is the accounting. Startups correctly account for the upfront cost of writing tests (engineering hours this sprint). They rarely account for the ongoing cost of not having tests (incident response, support load, delayed features, lost customers). The upfront cost is visible. The ongoing cost accrues invisibly until it's large enough to notice, by which point it's already been paid.
A startup that skips testing isn't saving engineering time. It's deferring a larger cost into the future at a bad interest rate.
Tools like Autonoma eliminate the maintenance assumption entirely — agents generate tests from your codebase and update them as your product changes, making the ROI calculation far more straightforward.
Start With Smoke Tests for Your Critical Paths
If the idea of comprehensive automated testing feels overwhelming, there's a much smaller starting point that captures most of the protection with a fraction of the effort: smoke testing your critical paths. If you're starting from zero test coverage, our guide on how to add tests to a codebase that has none walks through the full setup.
Smoke testing is the practice of running a minimal set of automated checks against your most critical user flows after every code change to verify that core functionality still works. The name comes from hardware testing, where you'd power on a new board and check whether it smoked. In software, a smoke test suite asks a simple question: did we break anything fundamental?
It helps to understand where smoke testing fits relative to other types of testing:
| Aspect | Smoke Testing | Sanity Testing | Regression Testing |
|---|---|---|---|
| Purpose | Verify core functionality works | Verify a specific fix works | Verify nothing broke after changes |
| Scope | Broad, shallow | Narrow, focused | Comprehensive |
| When to run | Every new build or PR | After targeted bug fixes | Before releases |
| Duration | Minutes | Minutes | Hours |
For startups, smoke testing is the highest-leverage starting point because it's fast, broad, and catches the failures that cost the most. A full regression testing suite comes later as the product stabilizes.
For most startups, critical paths fall into three to five categories. The first is authentication: can users sign up, log in, and reset their password? If these break, no one can use your product. The second is the core activation flow: whatever a new user has to do to get value from the product for the first time. The third is any billing or checkout flow. The fourth is any API endpoint that external customers or integrations depend on.
That's it. You don't need to test every edge case, every settings page, every admin flow. You need to test the paths that, if broken, would cause a real problem for real users.
A smoke test suite covering these four areas might be 10 to 20 tests. Running on every pull request, it would catch the majority of production regressions before they ship. The signup form that breaks because of a dependency upgrade. The checkout button that stops working after a CSS change. The API endpoint that returns a 500 because of an unhandled null.
What to include in your smoke test suite. Authentication flows (signup, login, logout, password reset) cover your entry points. Your core value delivery flow, the three to five steps a new user takes to first get value from the product, covers your activation. If you have paid plans, a checkout or upgrade flow covers your revenue path. If external systems depend on your API, a handful of endpoint smoke tests cover your integration surface.
How to implement smoke tests. The simplest path is Playwright for E2E smoke tests. A basic Playwright test for signup looks like this:
// Smoke test: verify signup flow works end-to-end
import { test, expect } from '@playwright/test';
test('signup flow works', async ({ page }) => {
await page.goto('/signup');
await page.fill('[data-testid="email"]', 'test@example.com');
await page.fill('[data-testid="password"]', 'securepassword123');
await page.click('[data-testid="submit"]');
await expect(page).toHaveURL('/dashboard');
await expect(page.locator('[data-testid="welcome-message"]')).toBeVisible();
});Wire that into a GitHub Actions workflow that runs on every pull request and you have a smoke test pipeline:
name: Smoke Tests
on: [pull_request]
jobs:
smoke:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- run: npm ci
- run: npx playwright install --with-deps
- run: npx playwright test --project=smoke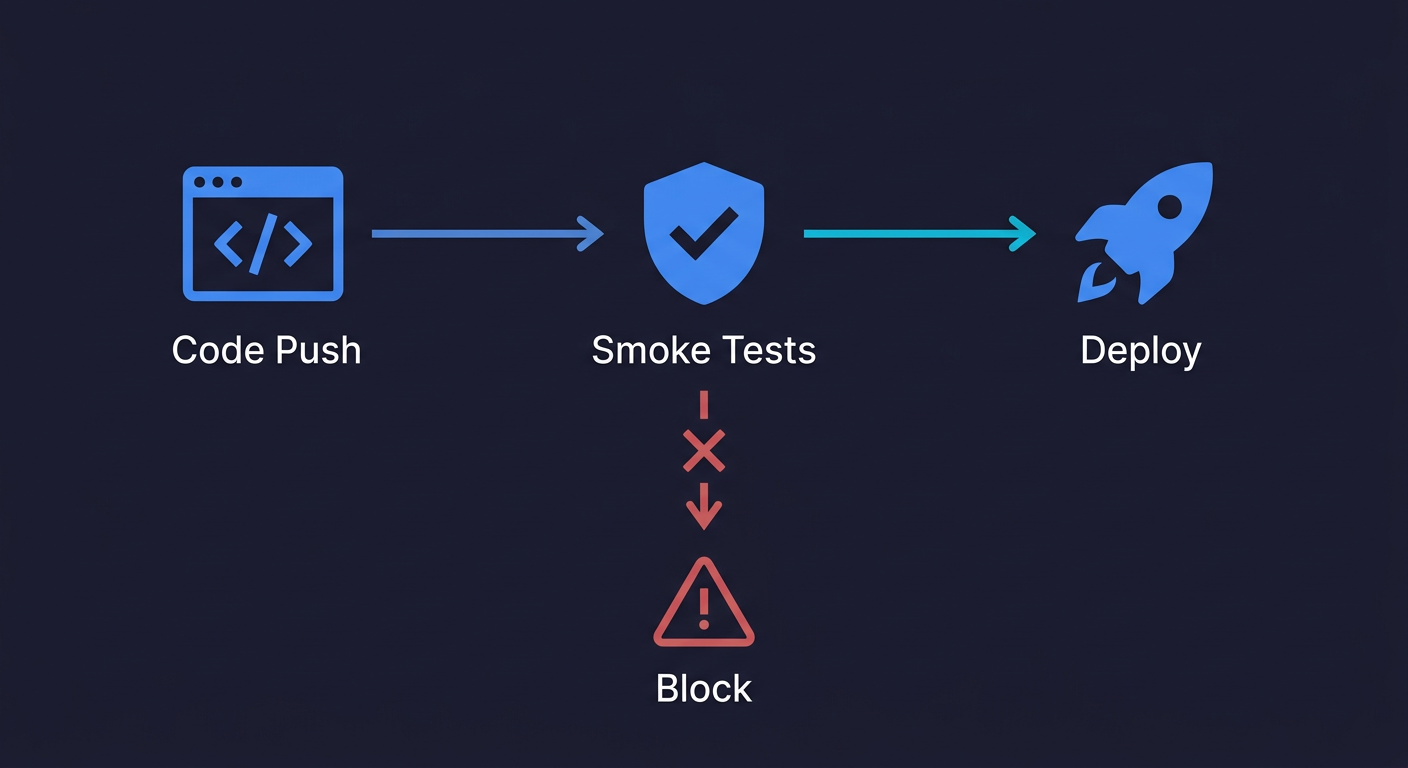
Not comprehensive. Not zero-maintenance. But it catches the bugs that would cost you $10,000 on a Friday afternoon.
The goal at this stage isn't full coverage. It's a reliable signal that nothing catastrophic broke before each deploy. A green smoke test suite won't tell you your application is perfect. It will tell you the critical paths still work.
How Automated Testing Changes the Economics of Production Bugs
Once your smoke tests are in place, the natural next question is how much coverage to add and whether the investment makes sense.
The ROI calculation for automated testing is straightforward in principle. You invest engineering time to write and maintain tests. In return, you catch bugs before production. The question is whether the time you save in incident response exceeds the time you spend on tests.
For scripted test automation, this trade-off is genuinely unfavorable in many startup environments. A Playwright test suite takes time to write and more time to maintain as the product changes. Selectors break. Flows change. The engineer who wrote the tests has to keep them current. For a fast-moving product with six engineers all building features, test maintenance often consumes more time than the incidents it prevents.
This is the honest version of why testing gets abandoned in early-stage companies. The math doesn't work with the traditional scripted model, and the teams that abandoned it were making a rational calculation.
The economics shift when you change the maintenance assumption. Consider three approaches for a 10-person startup shipping two to three times per week.
| Metric | No Testing | Scripted Automated Testing | AI-Generated Testing |
|---|---|---|---|
| Setup cost | $0 | 40-80 hours (writing initial suite) | Hours, not weeks |
| Monthly maintenance | $0 | 8-16 engineer-hours | Near-zero (self-healing) |
| Production incidents per quarter | 3-6 | 1-2 | 0-1 |
| Incident cost per quarter | $22,000-$65,000 | $7,000-$20,000 | $0-$7,000 |
| Testing overhead per quarter | $0 | $9,000-$18,000 | $1,500-$3,000 |
| Net quarterly cost | $22,000-$65,000 | $16,000-$38,000 | $1,500-$10,000 |
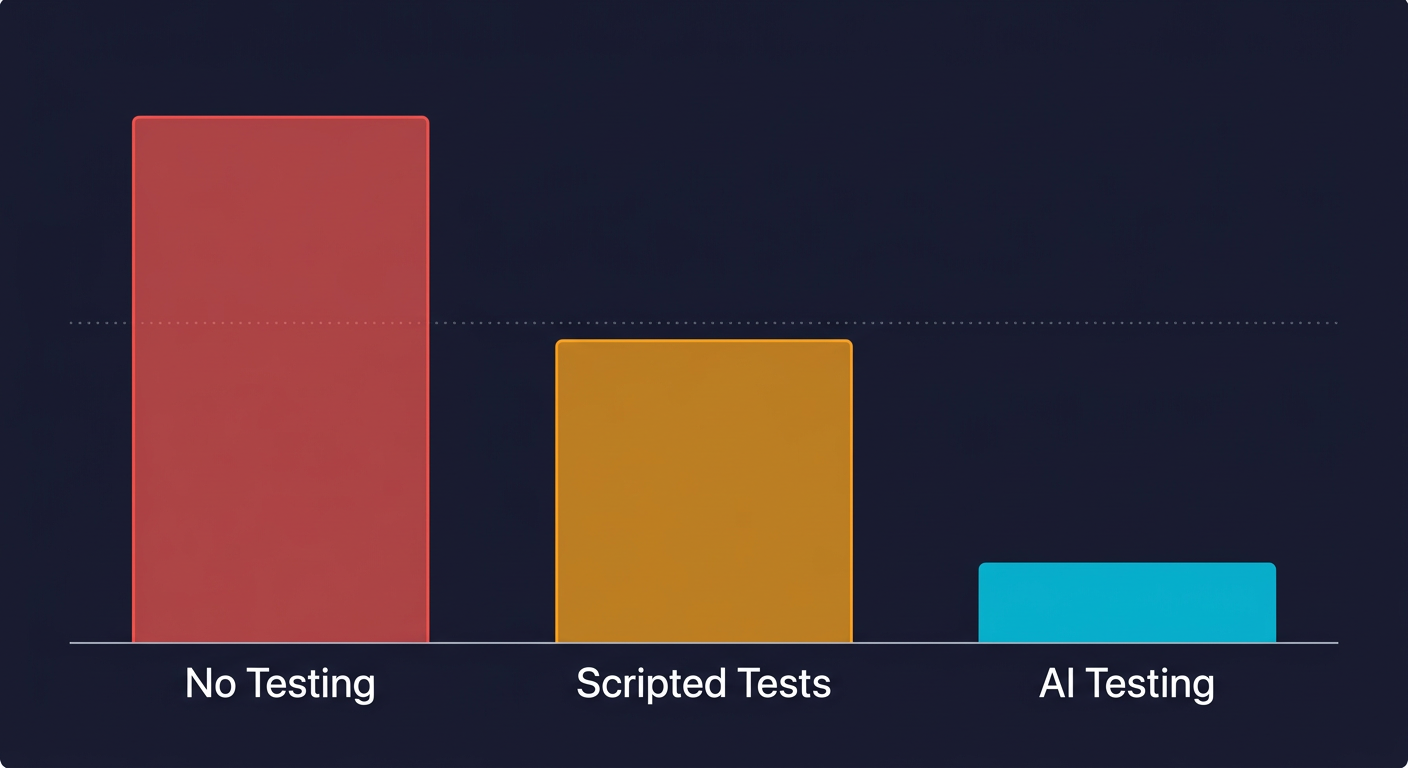
The scripted automation row tells the real story. If you add up incident savings ($15,000) but subtract maintenance cost ($13,500), the net benefit is smaller than expected. For a team where those 12 hours per month come from engineers who should be shipping features, the ROI can be close to neutral.
The calculus changes entirely when maintenance cost drops toward zero. That's where the economics of testing go from "debatable" to "obvious."
How AI Testing Changes the Math Further
Traditional scripted test automation has one fundamental problem: tests are written descriptions of how your UI looked on the day they were written. Your product doesn't look the same two sprints later. Every change that affects a selector, a URL, or a flow sequence breaks a test. Someone has to fix it.
Autonoma was built to solve exactly this problem. Instead of writing test scripts, you connect your codebase and tests are generated, executed, and maintained automatically as your product evolves. The key difference is where the test definition lives: a Playwright script encodes what your UI looked like when it was written, while Autonoma derives tests from the codebase itself, so when your code changes the tests change with it. For a deeper look at how this works, see what is agentic testing.
The economics in the table above reflect this. When maintenance cost drops from 12 engineer-hours per month to near-zero, the ROI calculation flips. You get better bug coverage than scripted automation, with less engineering overhead than no testing at all.
Where to Start With Smoke Testing
The practical question is not whether to test. It is where to begin, given that you have a roadmap, limited engineering hours, and a product that needs to ship.
Start with smoke tests on your top three critical paths this week. Pick signup/login, your core activation flow, and your billing flow if you have one. Write three Playwright tests or connect your codebase to Autonoma and let agents generate them. Get those three tests running in CI as a required merge gate. For a complete playbook on getting started, see our E2E testing guide for startups.
That one step, three tests, one CI check, catches a significant portion of the production bugs that would otherwise reach users. It doesn't require a testing strategy document or a QA roadmap. It requires an afternoon and a GitHub Actions file.
Once those three tests are running cleanly for two to three weeks, add three more. Cover the next highest-risk flows. Keep expanding until you have coverage on everything that, if broken, would generate a user complaint.
The goal is not comprehensive coverage immediately. It is a reliable signal on your most critical paths, running automatically on every pull request, blocking merges when something breaks. That single structural change moves the economics of testing from "debatable" to "clearly worth it" for every startup that has experienced a real production incident.
Your next production bug is coming. The question is whether you find it in CI before it ships, or users find it for you on a Friday night.
Frequently Asked Questions
Smoke testing is a minimal set of automated tests that verify the most critical user flows in your application still work after a code change. The goal is not comprehensive coverage but a fast signal that nothing fundamental broke before a deploy. For a typical SaaS startup, a smoke test suite covers authentication, the core activation flow, billing, and key API endpoints. It usually runs in under 5 minutes and catches the majority of production regressions.
For a 10-person startup, a single production incident typically costs $7,000 to $32,000 when you account for all four cost categories: engineering time (diagnosis, fix, hotfix deploy), lost revenue and signups from the outage, support load from affected users, and opportunity cost from the sprint capacity redirected to the incident. Two to four incidents per quarter, which is common without testing, translates to $15,000 to $130,000 in annual incident cost.
Most startups skip automated testing because they're making a rational but incomplete calculation. The upfront cost (writing tests) is visible. The ongoing cost of not testing (incident response, slower velocity, lost customers) accrues invisibly. The reasoning is also based on the scripted test automation model, where maintenance burden is high for fast-moving products. With AI-generated testing that self-heals as code changes, the maintenance cost that made testing impractical for lean teams no longer applies.
Start with the paths that, if broken, would cause immediate user pain or lost revenue. For most SaaS products that means: (1) authentication (signup, login, password reset), (2) the core activation flow (the first steps a new user takes to get value), (3) billing or checkout, and (4) any API endpoints that external customers or integrations depend on. Three to five tests covering these paths catch the majority of production regressions without creating an unmanageable maintenance burden.
The ROI depends heavily on the maintenance model. With traditional scripted tools like Playwright or Cypress, the ROI is often neutral for fast-moving startups because maintenance cost consumes much of the incident savings. With AI-generated testing that maintains itself automatically, the ROI is significantly positive: incident costs drop by 80-90% while engineering overhead stays near-zero. For a 10-person startup spending $22,000-$65,000 per quarter on production incidents, even basic automated testing coverage pays for itself within the first month.
The fastest path to smoke testing is: (1) pick three critical user flows, (2) write simple Playwright tests for them (or connect your codebase to Autonoma and let agents generate them), (3) add a GitHub Actions workflow that runs the tests on every pull request, (4) set the test results as required status checks. The whole setup takes an afternoon. The tests run in under 5 minutes. Engineers are never blocked waiting for slow CI. The maintenance overhead is minimal if you keep the suite small and focused on truly critical paths.
Smoke testing is a subset of automated testing. Automated testing encompasses all forms of programmatically executed tests: unit tests, integration tests, end-to-end tests, performance tests, security tests. Smoke testing specifically refers to a minimal, fast-running subset that verifies core functionality hasn't broken. Think of automated testing as your full testing strategy and smoke testing as the first, most important layer of it. For startups with no existing test coverage, starting with smoke tests on critical paths is the highest-leverage first step.
AI testing tools like Autonoma eliminate the maintenance cost that makes traditional automated testing impractical for fast-moving startups. Instead of writing test scripts that break whenever the UI changes, you connect your codebase and agents generate tests from your routes, components, and user flows. A Maintainer agent updates tests automatically as code changes, so tests don't go stale. This removes the primary objection to testing at early-stage companies: the ongoing engineering time required to keep tests current. The result is production bug rates similar to comprehensive test coverage, at a fraction of the engineering cost.



