
Adding tests to a zero-coverage codebase does not require a grand plan, a dedicated QA hire, or a chosen test automation framework. The only thing that matters in the first two weeks is identifying your three most critical user flows and getting automated coverage on them. That alone eliminates the majority of real production risk. Everything else, unit tests, integration tests, coverage percentages, can follow at whatever pace makes sense.
You've been meaning to add tests for months. Maybe a production bug finally forced the conversation. Maybe a new engineer joined and asked, "what's the testing setup?" and the answer was awkward. Either way, you're staring at a codebase with zero coverage and the problem feels bigger than it actually is. Michael Feathers defined legacy code as any code without tests. By that definition, your six-month-old startup codebase qualifies. The good news is that the cost of not testing is avoidable, and the path out is the same regardless of age.
The instinct is to do it properly: research frameworks, pick the right architecture, plan for 80% coverage, set up everything before writing a single test. That instinct is wrong. It's the instinct that keeps the test count at zero for another quarter.
The right move is to get one test working today. Then add two more this week. Then build from there.
Start With Your Three Most Dangerous Flows
Before picking a tool or framework, identify the three user flows where a bug would hurt the most. Not the most common flows. The most dangerous ones.
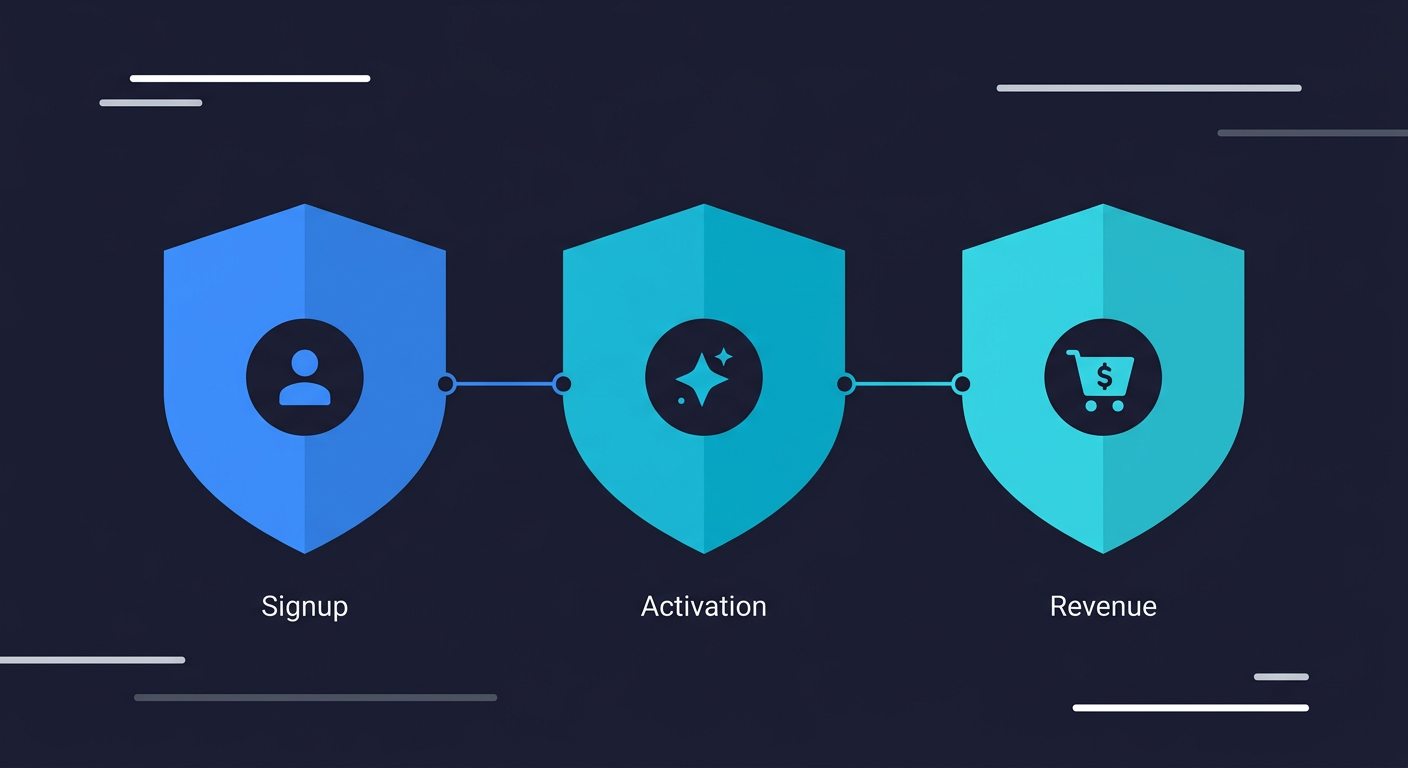
For most products, these are obvious once you say them out loud: user signup and login, the core activation step that delivers value, and the transaction or conversion that drives revenue. For a SaaS product, that's create account, reach the "aha moment," and upgrade or checkout. For an API product, it might be authentication, the primary endpoint, and the webhook delivery path. The specific flows depend on your product, but the logic is the same: if this breaks and nobody catches it for 12 hours, what are the consequences?
These flows are your starting point. Not because they're the most likely to break, but because a break in any of them hits users immediately and directly. Every minute of testing investment you make should protect against that category of risk first.
The corollary is what you deliberately skip for now: edge cases, error states, admin interfaces, internal tooling, and anything that only affects your team. Those matter, but they can wait. The goal of week one is not comprehensive coverage. It's a safety net around the flows that would cause real damage if they broke silently.
Pick a Test Automation Framework and Move On
The framework debate is where most teams stall. Playwright vs Cypress vs Selenium. TypeScript vs Python. Hosted test runners vs self-managed CI. If you're starting from zero, none of these decisions matter as much as the decision to write a test at all.
Here's a practical starting point for most web applications: use Playwright with TypeScript. It's well-maintained, has excellent documentation, installs in minutes, and runs cross-browser. The official docs include a create-playwright command that scaffolds a working test project in under five minutes. If your application is a React or Next.js frontend backed by an API, Playwright handles your E2E testing flows cleanly and the test automation framework setup is minimal.
If your primary surface is an API with no UI, use your language's native HTTP testing library. For Node.js, supertest with Jest or Vitest works fine. For Python, pytest with httpx or requests. These are not glamorous choices but they're fast to set up and easy to run in CI.
Here's the full picture at a glance:
| Framework | Best For | Setup Time | Learning Curve |
|---|---|---|---|
| Playwright | Web apps (E2E) | ~5 min | Medium |
| Cypress | Web apps (E2E) | ~5 min | Low |
| Selenium | Enterprise / multi-language | 15-30 min | High |
| Jest + supertest | Node.js APIs | ~2 min | Low |
| pytest + httpx | Python APIs | ~2 min | Low |
The framework you pick matters less than the consistency with which you use it. Pick one. Start writing tests. You can always migrate later, and you probably won't need to.
If you want to skip the scripting entirely, Autonoma reads your codebase and generates E2E tests for your critical flows automatically — so you get test coverage from day one without choosing a framework or writing a single test file.
Use AI Test Generation to Write Your First Tests
This is the part most guides skip. Writing your first tests from scratch is genuinely annoying, especially when the codebase has no existing test patterns to follow. The blank page problem is real.
AI tools are very good at generating test scaffolding when you give them the right inputs. Open your codebase in Claude Code, Cursor, or whatever AI coding assistant you use. Point it at the component or route that handles your most critical flow. Ask it to generate a Playwright test (or whatever framework you chose) that covers the happy path.
The output won't be perfect. The selectors might need adjustment. The assertions might miss nuances. But you'll get from zero to a runnable test structure in 10 minutes instead of 90, and that's the only thing that matters at this stage.
Be specific about what you hand the AI. Paste the route handler, the form component, or the API endpoint code alongside your request. The more context it has, the closer the generated test will be to something that runs on first try. Ask for the happy path specifically. Ask it to avoid complex setup. Ask for inline comments explaining each step.
Here's what that output might look like for a signup flow:
import { test, expect } from '@playwright/test';
test('user can sign up and reach dashboard', async ({ page }) => {
// Navigate to signup page
await page.goto('/signup');
// Fill in the registration form
await page.fill('[name="email"]', 'test@example.com');
await page.fill('[name="password"]', 'SecurePass123');
// Submit the form
await page.click('button[type="submit"]');
// Verify redirect to dashboard
await expect(page).toHaveURL('/dashboard');
await expect(page.locator('h1')).toContainText('Welcome');
});That's 12 lines. It took an AI assistant about 30 seconds to generate, and maybe 10 minutes to adjust the selectors and assertions to match the real application. That's the effort bar for your first test.
Once the generated test runs, read it carefully. Fix what's wrong. Adjust the assertions to match what your application actually does. That review process is itself valuable, forcing you to think precisely about what your most critical flows are supposed to do.
Get It Running in CI Before Adding More Tests
The single biggest mistake teams make when adding their first tests is treating them as a local development tool. Tests that only run on a developer's machine before a deploy are not a safety net. They're a habit, and habits degrade under sprint pressure.
Before you write your second test, get the first one running in CI. For most teams, this means GitHub Actions. The configuration is straightforward and adding it early, when you only have one test, is much easier than adding it later when you have 50 and need to figure out environment variables, database seeds, and build steps all at once. This is the first step toward continuous testing, where every code change gets validated automatically.
A minimal GitHub Actions workflow that runs Playwright tests on every pull request looks like this:
name: E2E Tests
on:
pull_request:
branches: [main]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-node@v4
with:
node-version: 20
- run: npm ci
- run: npx playwright install --with-deps
- run: npm run build
- run: npx playwright testAdd this to .github/workflows/e2e.yml. For a more complete CI/CD setup with environment variables and database seeding, see our E2E testing for startups playbook. The next time you open a pull request, the test runs automatically. When it passes, you have structural enforcement: any change to the codebase gets checked against your critical flow. That's a safety net, even if it only covers one flow so far.
The CI setup is the multiplier. A single test running on every PR does more work than ten tests running manually.
Build Outward, Not Upward
Now you have one test running in CI. The instinct at this point is to go deep: add 15 more assertions to the existing test, cover every edge case, handle every error state. Resist it.
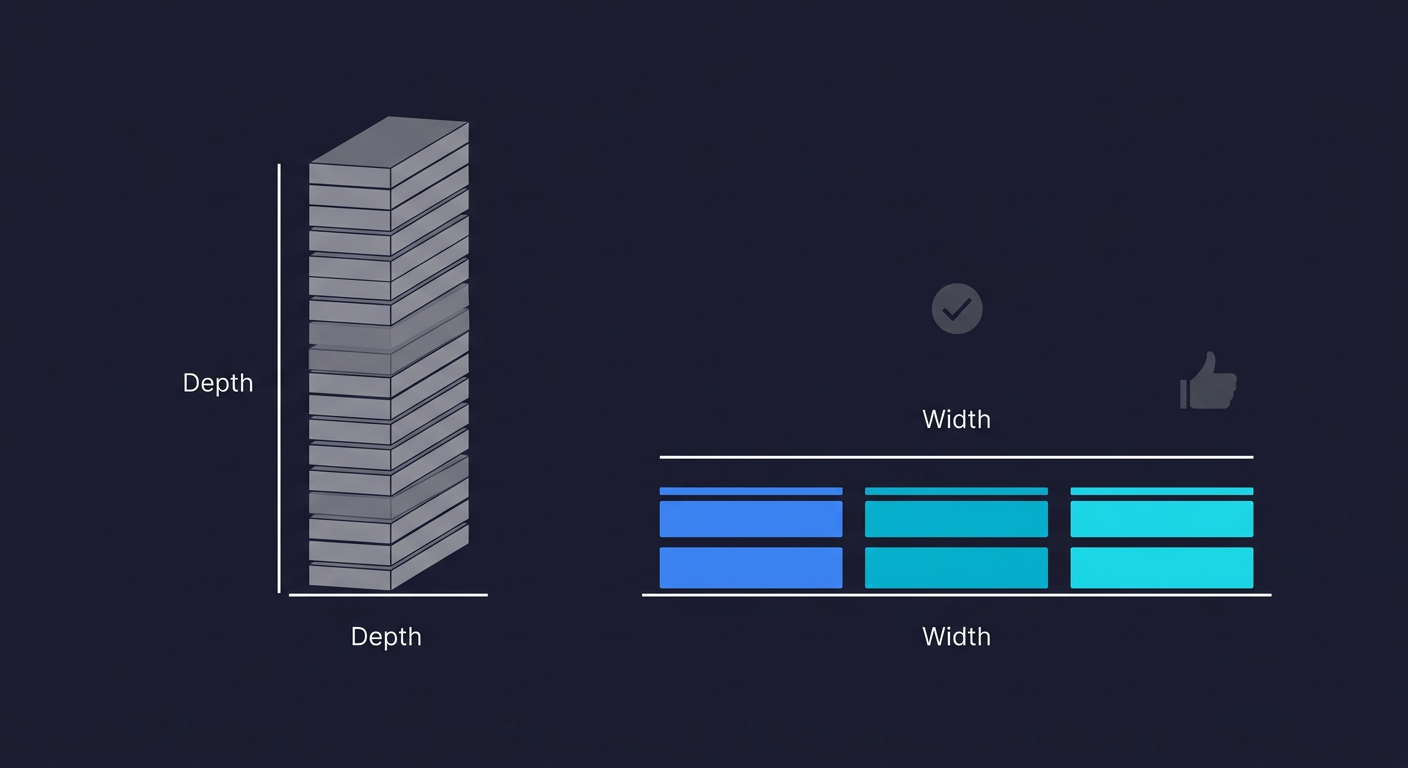
Go wide first. Cover your second critical flow. Cover your third. Three stable, reliable E2E tests on your three most important flows are worth more than one exhaustive test suite on a single flow. Width of coverage across critical paths reduces real production risk faster than depth on any single path.
After you have the three critical flows covered, start adding tests in a specific order based on where bugs actually hurt. The next highest-value targets are usually the flows adjacent to your critical path: password reset, the step before the core activation, the post-purchase confirmation. These are not as dangerous as your primary flows but they're the next tier of user impact.
This approach deliberately inverts the traditional test pyramid, which recommends many unit tests at the base and a small number of E2E tests at the top. That pyramid assumes you're building tests alongside new code. When you're retrofitting tests onto an existing codebase, the calculus changes: E2E tests on critical flows give you the highest risk reduction per test written. You can build the bottom of the pyramid later.
Unit tests fit well for specific, high-complexity business logic: pricing calculations, permission rules, data validation, anything with conditional branching that's hard to test through the UI. They're fast, stable, and good documentation for complex logic. But they're not where you start from zero, and they shouldn't be the primary content of a testing best practices conversation for teams without existing coverage.
The Coverage Metric Is a Trap
Most engineers have been told that 80% code coverage is the goal. It's not a useful target for teams starting from zero, and chasing it will derail the effort.
Code coverage measures which lines of code are executed during tests. It does not measure whether your tests are actually useful. A codebase with 80% coverage can have all three of its critical user flows completely untested, if the 80% happens to cover utility functions, configuration parsing, and internal helpers. Meanwhile a codebase with 15% coverage that has its signup, activation, and checkout flows under test is dramatically safer to ship.
Coverage is a useful metric once you have a mature testing practice and want to find gaps. It's a counterproductive metric when you're starting from zero, because it will push you toward writing tests that inflate the number without protecting against the risks that actually matter.
Instead of tracking coverage percentage, track flow coverage: which critical user flows have automated tests, and when did each one last run green. That's the metric that tells you whether your users are protected.
What Comes After the Foundation
Once you have your three critical flows covered and running in CI, the testing practice sustains itself through a simple rule: when you ship a new feature, add a test for its happy path. When you fix a production bug, add a test that would have caught it. This rule, applied consistently, means your coverage grows with your product without requiring any dedicated sprint capacity.
The teams I've seen build genuinely strong testing practices didn't do it through a big upfront effort. They did it through a small, consistent habit: new feature goes in, test goes in alongside it. The foundation was just the three critical flows. Everything else accumulated on top.
If maintaining that foundation starts to feel like work, because the tests break when the product changes and someone has to fix them constantly, that's the right time to think about tools that reduce maintenance cost. Platforms like Autonoma generate and maintain tests from your codebase directly, so the tests stay current as the product evolves without requiring someone to repair selectors after every sprint. For a founding engineer wearing five hats, removing that maintenance burden is often more valuable than the tests themselves.
But that's a later problem. Right now, the problem is zero tests. Start with one.
For most web applications, Playwright with TypeScript is the practical starting point. It installs quickly, has excellent documentation, and runs cross-browser. If your product is primarily an API, use your language's native HTTP testing library (supertest for Node.js, pytest for Python). The framework matters far less than the decision to start. Pick one and write a test today rather than spending a week evaluating options.
The most important testing best practice when starting from zero is to cover your three most critical user flows before anything else. These are the flows where a silent bug would cause direct user harm or revenue loss. Get those tests running in CI before adding more. Avoid chasing code coverage percentages early. Once the foundation is in place, the sustainable best practice is: every new feature ships with a test for its happy path, and every production bug gets a regression test.
Start with E2E tests covering your critical user flows. Unit tests are excellent for complex business logic (pricing calculations, permission rules, data validation) but they don't tell you whether users can actually complete a purchase or sign up. E2E tests on your three most important flows give you the highest risk reduction per test when starting from zero. Add unit tests as you go for logic-heavy code, but don't let them crowd out critical-path E2E coverage.
GitHub Actions is the fastest path for most teams. Create a `.github/workflows/e2e.yml` file with a workflow that checks out your code, installs dependencies, installs Playwright (or your chosen framework), builds the app, and runs the tests. Get this working before you write your second test. A single test in CI provides more structural protection than ten tests running manually.
AI coding assistants like Claude Code or Cursor can generate test scaffolding from your existing routes and components. Give them the source code for the flow you want to test and ask for a Playwright test covering the happy path. The output needs review and adjustment but eliminates the blank-page problem. For teams that want tests generated and maintained automatically from the full codebase, [Autonoma](https://getautonoma.com) reads your code and generates tests without any manual input, then keeps them current as the codebase changes.



