
A quality gate for vibe coding is a vibe coding CI/CD enforcement layer that runs automatically on every pull request before merge. Because the author of a vibe-coded PR may not fully understand what the AI wrote, the gate has to catch what code review misses: type errors, security vulnerabilities, unverified behavior, and regressions. This guide walks through a five-layer quality gate stack (linting, type checking, security scanning, automated test generation, and agentic testing) with a complete GitHub Actions YAML you can drop into any repository today.
Traditional code review assumes the author understands the diff. With vibe-coded PRs, that assumption breaks. A developer who prompted Cursor to build an authentication flow may have shipped working code they could not explain line by line. The PR looks clean. Reviewers approve it. The gate was the last defense, and it was not there.
This article is the engineering-lead companion to our broader vibe coding quality issues breakdown. That article explains why the problem exists. This one tells you exactly how to set up quality checks for AI-generated code so that a vibe-coded PR cannot merge without passing real verification. Whether you call it a vibe coding CI/CD pipeline, a CI pipeline for vibe-coded apps, or a PR quality gate, the goal is the same: automated verification that compensates for what the human author did not manually verify.
Why the Vibe Coding Code Review Process Needs Different Quality Gates
Every code review process implicitly trusts the author to have thought through what they wrote. The reviewer's job is to spot what the author missed, not to compensate for an author who may not have read the generated output at all.
Vibe-coded PRs break that contract in specific ways. The author may have iterated rapidly through five AI-generated revisions, accepted whichever one passed the click-through test, and opened a PR without tracing through the security implications of the final diff. This is not negligence. It is the natural behavior when generation velocity decouples from comprehension velocity.
The quality gate has to compensate for what the author did not verify. That means checking things a careful human author would have checked mentally: type consistency, input validation, authorization on new routes, absence of hardcoded secrets, and behavioral correctness against your existing application. Our vibe coding best practices guide covers the manual workflow for this. Quality gates automate it so it happens on every PR, not just the ones where someone remembers to check.
The other thing that changes is the blast radius of a missed check. A vibe-coded PR touching an authentication route might silently expose a privilege escalation vulnerability that neither the author nor the reviewer caught, because the generated code looked semantically correct. Static analysis, security scanning, and behavioral testing catch these in CI. Code review often does not.
The Five-Layer Quality Gate Stack
Not all checks are equal. Some catch bugs at the syntax level. Others catch behavioral regressions only visible when the application actually runs. Layering them gives you coverage across the entire failure surface of vibe-coded output.
| Layer | What It Catches | Key Tools | CI Runtime | Priority |
|---|---|---|---|---|
| 1. Linting & Formatting | Dead code, hallucinated imports, style drift | ESLint, Prettier, Biome | ~1 min | Required |
| 2. Type Checking | Type drift, any fallbacks, shape mismatches | TypeScript --strict | ~2 min | Required |
| 3. Security Scanning | Hardcoded secrets, SQL injection, insecure defaults | Semgrep, Gitleaks, npm audit | ~3 min | Required |
| 4. Test Coverage | Untested new code, regressions in changed files | Jest, Vitest | ~5 min | Required |
| 5. Agentic Testing | Behavioral regressions, flow-level failures, auth gaps | Autonoma | ~10 min | Recommended |

The foundation is linting and formatting. This layer is fast, cheap, and catches a reliable class of generated code problems: unused variables that signal dead code paths, imports that reference modules the AI hallucinated, style inconsistencies that make the diff harder to review. For vibe-coded PRs specifically, it also catches the pattern where the AI generated two versions of the same logic and left both in the file.
Type checking is the second layer, and for TypeScript projects it is arguably the most valuable one. AI coding agents generate type-safe code most of the time. When they do not, the type errors tend to be in exactly the places that matter: API response shapes that do not match what the component expects, function parameters that accept any where a specific type is required, and return types that silently change when the AI refactors a shared utility. A strict TypeScript compile pass in CI blocks these before they reach production.
Security scanning is the third layer and the one most teams skip because it generates false positives. For vibe-coded PRs, the tradeoff changes. AI-generated code has documented patterns of insecure defaults: SQL queries built with string interpolation, file upload handlers without type validation, API routes that trust user-supplied IDs without verifying ownership. A lightweight scanner like Semgrep with a focused ruleset catches these patterns reliably with low false-positive rates. We cover the full taxonomy of these vulnerabilities in our vibe coding security risks breakdown.
Automated test generation and execution is the fourth layer and where vibe coding quality gates diverge most sharply from traditional CI. Traditional CI runs tests that humans wrote before the PR. For vibe-coded PRs, that suite may not cover the new code at all, because the AI generated a feature that no one wrote tests for. This layer generates tests from the PR diff and runs them as part of the gate.
Agentic testing is the capstone layer, and the one that provides end-to-end behavioral verification. This is covered in depth in the final section.
This is the layer where Autonoma plugs into your PR workflow — agents read the changed code, generate behavioral tests for the new flows, and run E2E verification against your deployed environment before the merge gate opens.
Complete Vibe Coding CI/CD Pipeline: GitHub Actions Configuration
Below is a complete GitHub Actions workflow you can copy into .github/workflows/vibe-coding-gate.yml. It implements all five layers in sequence, with each layer blocking the merge if it fails.
name: Vibe Coding Quality Gate
on:
pull_request:
branches: [main, develop]
types: [opened, synchronize, reopened]
concurrency:
group: ${{ github.workflow }}-${{ github.ref }}
cancel-in-progress: true
jobs:
# Layer 1: Linting and formatting
lint:
name: Lint & Format Check
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Set up Node.js
uses: actions/setup-node@v4
with:
node-version: '20'
cache: 'npm'
- name: Install dependencies
run: npm ci
- name: Run ESLint
run: npx eslint . --ext .ts,.tsx,.js,.jsx --max-warnings 0
- name: Check formatting (Prettier)
run: npx prettier --check "src/**/*.{ts,tsx,js,jsx,json,css}"
# Layer 2: Type checking
typecheck:
name: TypeScript Type Check
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Set up Node.js
uses: actions/setup-node@v4
with:
node-version: '20'
cache: 'npm'
- name: Install dependencies
run: npm ci
- name: Run TypeScript compiler (no emit)
run: npx tsc --noEmit --strict
# Layer 3: Security scanning
security:
name: Security Scan
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Run Semgrep (OWASP ruleset)
uses: returntocorp/semgrep-action@v1
with:
config: >-
p/owasp-top-ten
p/javascript
p/typescript
auditOn: push
- name: Check for hardcoded secrets (Gitleaks)
uses: gitleaks/gitleaks-action@v2
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
- name: Dependency vulnerability audit
run: npm audit --audit-level=high
# Layer 4: Unit and integration tests
test:
name: Test Suite
runs-on: ubuntu-latest
needs: [lint, typecheck]
steps:
- uses: actions/checkout@v4
- name: Set up Node.js
uses: actions/setup-node@v4
with:
node-version: '20'
cache: 'npm'
- name: Install dependencies
run: npm ci
- name: Run test suite with coverage
run: npx jest --coverage --coverageThreshold='{"global":{"lines":70}}'
env:
NODE_ENV: test
- name: Upload coverage report
uses: actions/upload-artifact@v4
if: always()
with:
name: coverage-report
path: coverage/
# Layer 5: Agentic end-to-end testing
agentic-testing:
name: Agentic E2E Testing
runs-on: ubuntu-latest
needs: [lint, typecheck, security]
if: github.event.pull_request.draft == false
steps:
- uses: actions/checkout@v4
- name: Trigger Autonoma test run
run: |
curl -X POST https://api.getautonoma.com/v1/runs \
-H "Authorization: Bearer ${{ secrets.AUTONOMA_API_KEY }}" \
-H "Content-Type: application/json" \
-d '{
"ref": "${{ github.sha }}",
"pr_number": ${{ github.event.number }},
"repository": "${{ github.repository }}"
}'
- name: Wait for Autonoma results
run: |
# Poll for completion (Autonoma posts back via GitHub Checks API)
echo "Agentic test run triggered. Results will appear as a GitHub Check."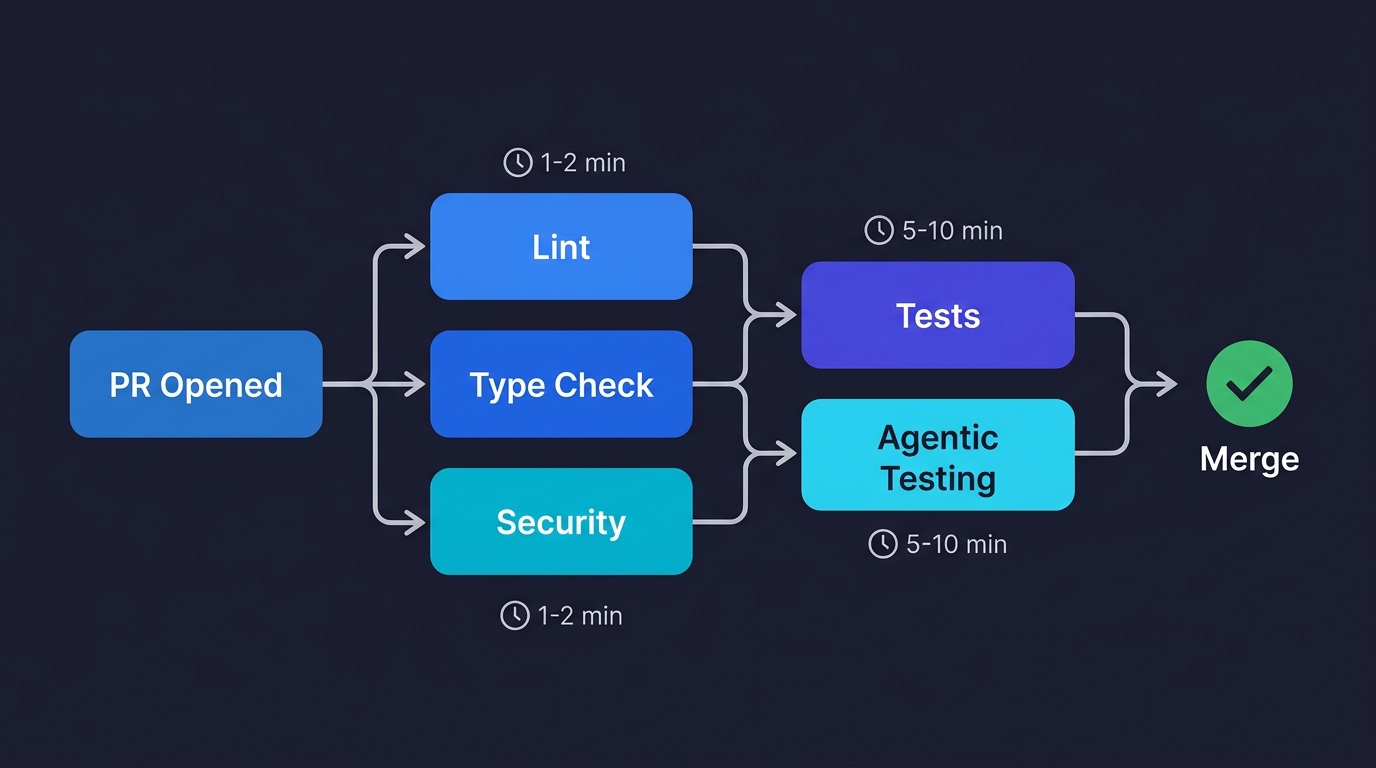
Save this as .github/workflows/vibe-coding-gate.yml. The five jobs run in parallel where dependencies allow: linting and type checking run immediately, security scanning runs in parallel with type checking, and the test suite and agentic testing layer wait for the fast checks to pass first. This keeps the critical feedback loop short: a lint failure surfaces in under two minutes, before the slower jobs waste compute.
Layer 1 and 2: Linting and Type Checking in Depth
These two layers are fast and nearly zero-maintenance. Configure them once and they run on every PR without tuning.
For linting, the --max-warnings 0 flag is critical for vibe-coded projects. Without it, warnings accumulate quietly. AI-generated code tends to introduce unused variables and imports at a higher rate than hand-written code, because the AI generates what it needs for the implementation it chose, not necessarily what your project's conventions expect. Making every warning a failure keeps the signal clean.
If you are not already using Biome as a unified linter and formatter, vibe-coded projects are a good reason to start. A single biome check command replaces both ESLint and Prettier with zero configuration drift:
- name: Run Biome (unified lint + format)
run: npx @biomejs/biome ci ./srcFor TypeScript, the --strict flag is the key addition for vibe-coded projects. Many projects run TypeScript without strict mode to allow the any type, which is exactly what AI coding agents fall back to when they are uncertain about a type. Strict mode forces the issue. If the AI generated an any where a specific type should exist, the compile fails and the reviewer knows exactly where to look.
If adding --strict to an existing project breaks hundreds of checks, scope it to the changed files only using a PR-level tsconfig:
- name: Type-check changed files strictly
run: |
CHANGED=$(git diff --name-only origin/${{ github.base_ref }}...HEAD \
| grep -E '\.(ts|tsx)$' | tr '\n' ' ')
if [ -n "$CHANGED" ]; then
npx tsc --noEmit --strict $CHANGED
fiLayer 3: Security Scanning for AI-Generated Code
Security scanning for vibe-coded PRs is different from scanning a traditional codebase in one important way: the failure modes are patterned. AI coding agents produce the same classes of security issues repeatedly, because they draw from training data where those patterns are common. This makes rule-based scanning unusually effective.
The Semgrep configuration in the workflow above uses p/owasp-top-ten and p/javascript. For teams with TypeScript backends (Node/Express, Next.js API routes), add p/nodejs and p/expressjs. For SQL databases, add p/sql-injection. Each ruleset adds maybe thirty seconds to CI runtime and catches an entire class of vulnerabilities.
Gitleaks catches the other common vibe coding security failure: hardcoded credentials. AI coding agents will sometimes embed literal API keys, database URLs, or JWT secrets in generated code when the developer's context window includes those values from an .env file. Gitleaks scans the entire diff, not just the current state of the file, so it catches secrets that were added and then removed within the same PR.
For teams that want tighter control over exactly which Semgrep rules run, replace the config block with an inline rules file:
- name: Run Semgrep with custom rules
uses: returntocorp/semgrep-action@v1
with:
config: .semgrep/vibe-coding-rules.ymlThen create .semgrep/vibe-coding-rules.yml with rules targeting the specific patterns your AI tool generates. The patterns worth writing custom rules for, based on what we see in vibe-coded codebases, are: missing authorization checks on API routes, eval() usage with user-controlled input, and file system operations on paths derived from request parameters.
Layer 4: Test Coverage Without a Preexisting Suite
The test suite layer assumes you have tests. For vibe-coded projects that are being quality-gated for the first time, that assumption may be wrong. This is the layer where most teams get stuck.
The workaround is to require coverage only on new code, not the entire codebase. Jest supports this through its --changedSince flag combined with coverage collection scoped to the changed files:
- name: Run tests on changed files
run: |
npx jest \
--testPathPattern="$(git diff --name-only origin/${{ github.base_ref }}...HEAD \
| grep -E '\.(test|spec)\.(ts|tsx|js)$' | tr '\n' '|')" \
--coverage \
--collectCoverageFrom="$(git diff --name-only origin/${{ github.base_ref }}...HEAD \
| grep -E '\.(ts|tsx|js)$' | tr '\n' ',')"This pattern is useful during the transition period when you are retrofitting quality gates onto an existing vibe-coded project. It does not require a fully passing test suite from day one. It requires that whatever code was changed has test coverage.
The coverage threshold in the base workflow (70% line coverage) is deliberately achievable. For teams in the early stages of adding tests to a vibe-coded codebase, starting at 70% and raising it incrementally is more effective than blocking PRs entirely with an unreachable threshold. The vibe coding testing guide covers the test generation workflow for bringing coverage up.
Layer 5: Agentic Testing as the Capstone Gate
The first four layers are necessary. They are not sufficient. Linting cannot tell you whether your checkout flow correctly handles a cart with a deleted product. Type checking cannot tell you whether your auth middleware applies to every route that needs it. Security scanning cannot tell you whether a sequence of user actions exposes data from another account.
Behavioral verification requires running the application. That is what the agentic testing layer does, and it is the layer that makes quality gates for vibe-coded PRs qualitatively different from traditional CI.
We built Autonoma to be the agentic testing layer in CI pipelines. Our approach: a Planner agent reads the codebase (including the diff), identifies the critical user flows affected by the PR, and generates test scenarios for each. An Automator agent executes those scenarios against a preview deployment. A Maintainer agent keeps the tests valid as the codebase evolves. This is what we described in detail in our agentic testing for vibe coding article.
For a vibe-coded pull request, this means the CI pipeline tests behaviors the author may not have thought to verify. The Planner derives test cases from the code itself, not from what the developer described in the PR description. If the AI-generated auth middleware has a gap, the Planner finds it by reading the route definitions, not by trusting that the author tested every case.
The Autonoma CI trigger in the workflow above posts back results to GitHub via the Checks API, which means the result appears as a named check on the PR, blocking merge if tests fail. No separate dashboard to check. No manual step to trigger.
Enforcing Gates Without Killing Velocity
The biggest objection from engineering leads who have seen CI friction slow teams down is reasonable: if every PR has to wait twenty minutes for a security scan and an agentic test run, developers will find ways around the gate.
The workflow addresses this through sequencing. The lint and type check jobs run first and fail fast, usually within two to three minutes. These catch the majority of obvious problems and provide immediate feedback. Security scanning and agentic testing run in parallel with each other, only after the fast checks pass. By the time a developer has addressed any lint or type errors and pushed again, the agentic test run is often already complete.
For teams with faster iteration requirements, two configuration options help. First, scope the agentic testing trigger to non-draft PRs only (already in the workflow with if: github.event.pull_request.draft == false). Developers work in draft PRs, run the full gate only when they mark ready for review. Second, use required status checks selectively. Make lint and type checking required for all PRs. Make security scanning and agentic testing required only for PRs touching specific paths (authentication, payments, data access).
# Scope agentic testing to high-risk paths only
jobs:
check-paths:
runs-on: ubuntu-latest
outputs:
high-risk: ${{ steps.filter.outputs.high-risk }}
steps:
- uses: actions/checkout@v4
- uses: dorny/paths-filter@v3
id: filter
with:
filters: |
high-risk:
- 'src/auth/**'
- 'src/api/**'
- 'src/payments/**'
agentic-testing:
name: Agentic E2E Testing
needs: [check-paths, lint, typecheck, security]
if: |
needs.check-paths.outputs.high-risk == 'true' &&
github.event.pull_request.draft == false
runs-on: ubuntu-latestThis keeps the gate overhead proportional to the risk of the change. A PR that updates a landing page component does not trigger the full agentic test run. A PR that modifies the payment flow does.
Common Pitfalls in Automated Testing for Vibe Coding PRs
Three patterns appear consistently when teams first add quality gates to vibe-coded repos.
Warning suppression as the first response. When lint gates start failing, the instinct is to add eslint-disable comments to the generated code. This is the wrong response. Each suppression is a decision to not fix the problem rather than fix the problem. Set a policy: suppressions require a comment explaining why. Even AI coding agents can be prompted to not generate suppress comments.
Type checking disabled for "speed." Projects that run tsc --noEmit without --strict miss the class of type errors that matter most in vibe-coded code. The argument that strict mode is too disruptive to add later is true if you wait long enough. Add it early. If the project is already large and non-strict, use the changed-files approach above to enforce strictness on new code only.
Security scanning tuned to silence. Semgrep with broad rulesets generates false positives. The wrong response is to turn off the scanner. The right response is to tune the ruleset to the patterns that matter for your stack. Start with a focused ruleset (one or two Semgrep registries) and add rules deliberately rather than starting broad and suppressing. The vibe coding best practices guide describes the specific vulnerability patterns worth prioritizing.
Treating agentic testing as optional. The first four layers catch structural problems. They do not verify behavior. A PR can pass all four layers and still ship a regression. Engineering leads who implement the first four layers and skip the fifth are still exposing themselves to the class of vibe coding failure that causes production incidents. See our breakdown of real vibe coding quality issues for examples of what passes static analysis and breaks in production.
A Note on AI-Powered Code Review Tools
Tools like CodeRabbit, SonarQube, GitHub's CodeQL, and Anthropic's Claude Code Review offer AI-powered code review that can flag logic errors, architecture violations, and code quality issues beyond what traditional linters catch. These are a valuable complement to the five-layer stack, not a replacement for it. AI code review operates on the diff, analyzing structure and patterns. Agentic testing operates on the running application, verifying behavior. For a thorough vibe coding pull request review process, consider adding an AI reviewer between layers 2 and 3, then relying on Autonoma's agentic testing as the behavioral verification at the end.
Rolling Out the Gate in Stages
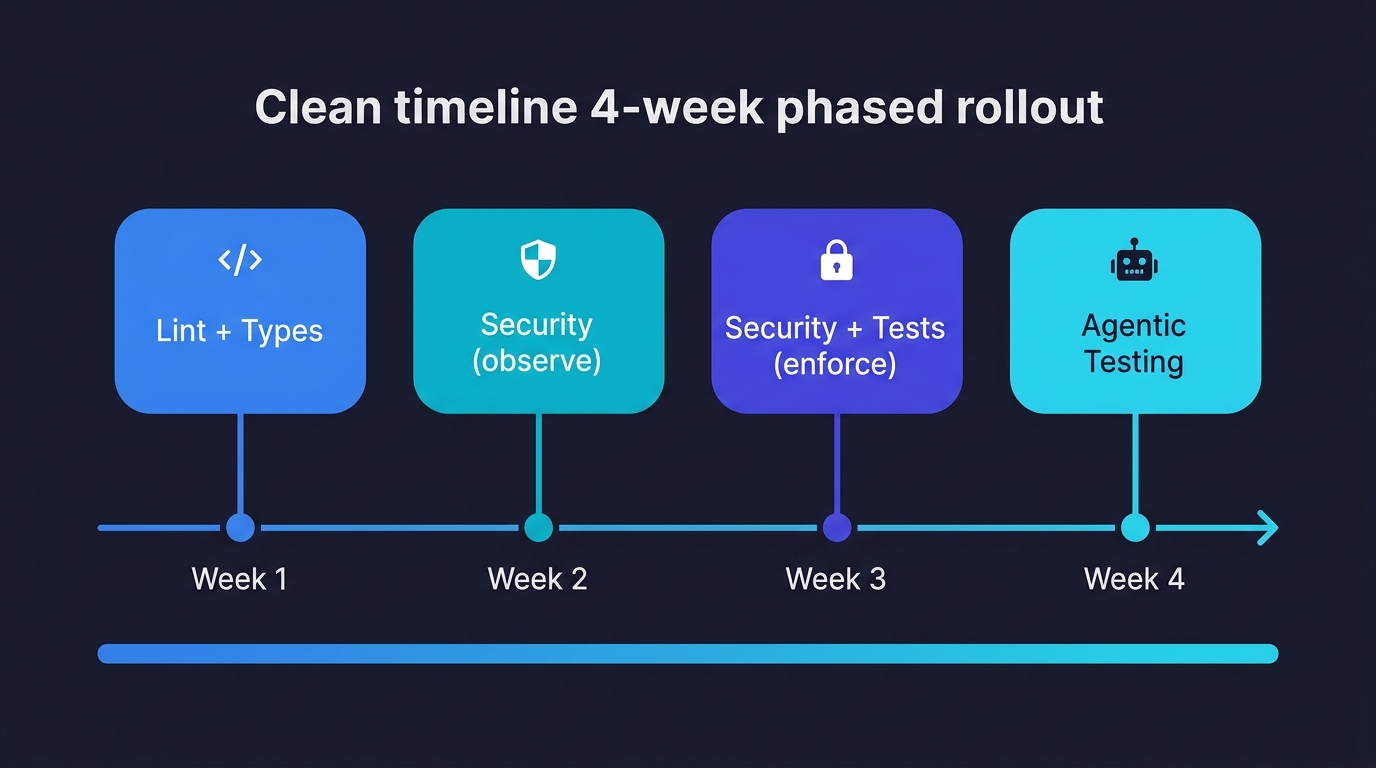
Implementing all five layers at once can feel overwhelming, especially for teams retrofitting gates onto an existing vibe-coded project. A phased approach reduces friction and builds confidence.
Week 1: Add linting and TypeScript type checking as required status checks. These are fast, low-noise, and immediately valuable. Use the changed-files-only strict mode if your project is not already strict.
Week 2: Add security scanning in observation mode. Run Semgrep and Gitleaks but do not block merge on their results. Use this week to tune your ruleset and suppress false positives.
Week 3: Enforce security scanning as a required check. Add the test coverage layer, scoped to changed files with a 70% threshold.
Week 4: Connect agentic testing on non-draft PRs. Start with path scoping so only high-risk changes trigger the full behavioral test run. Expand coverage as the team builds confidence.
This staged rollout means you get value from day one without blocking the entire team while you configure the more complex layers.
A quality gate for vibe coding is an automated CI/CD enforcement layer that runs on every pull request before merge. Because vibe-coded PRs are generated by AI, the author may not fully understand the diff. The gate compensates by running checks the author may not have done manually: linting, type checking, security scanning, and behavioral testing. Tools like Autonoma provide the agentic testing layer that verifies behavioral correctness end-to-end.
For vibe-coded PRs, the highest-value checks in order of priority are: TypeScript strict mode type checking (catches type drift from AI refactors), security scanning with Semgrep and Gitleaks (catches hardcoded secrets and insecure patterns AI generates frequently), and agentic behavioral testing (catches functional regressions that static analysis misses). Linting is table stakes. The agentic testing layer, provided by tools like Autonoma, is what differentiates a vibe coding quality gate from a standard CI pipeline.
Start with linting and type checking. They require no test infrastructure and provide immediate value. Add the GitHub Actions workflow from this article, scoped to `--changedSince` so it only checks files modified in the PR. Add security scanning next. For the test coverage layer, use the changed-files pattern to require coverage only on new code, not the full codebase. Connect Autonoma last for behavioral testing coverage. Each layer can be added independently without blocking on the others.
Use sequencing and path scoping. Run fast checks (lint, type checking) first so failures surface in two to three minutes. Run security scanning and agentic testing in parallel after fast checks pass. Limit agentic testing to non-draft PRs and to PRs touching high-risk paths (auth, payments, data access). This keeps the gate overhead proportional to the risk of the change. A styling PR should not trigger a full behavioral test run.
Yes. The five-layer stack (linting, type checking, security scanning, test coverage, agentic testing) is CI-agnostic. GitLab CI, CircleCI, and Bitbucket Pipelines all support equivalent job configurations. The specific syntax differs but the layer logic is identical. Autonoma's agentic testing layer integrates with any CI system that can make an HTTP request and read GitHub Check results.
Semgrep with the OWASP Top Ten ruleset catches the patterns AI coding agents produce most frequently: SQL injection via string interpolation, missing authorization checks, and insecure direct object references. Gitleaks catches hardcoded secrets, which are a specific risk when the developer's context window contains environment variables. npm audit covers dependency vulnerabilities. Together, these three tools cover the primary security failure surface of vibe-coded pull requests without excessive false positives.



