Why Vibe-Coded Apps Need Agentic Testing, Not Manual QA

Agentic testing for vibe coding means connecting your codebase to AI agents that autonomously plan test strategies, execute them against your running app, and self-heal when the code changes. It is the only testing approach that matches vibe coding's velocity because it requires no human scripting, no recording, and no maintenance. Manual QA is too slow. Traditional test automation requires engineers the vibe coder doesn't have. AI-generated tests share the same blind spots as the code they're supposed to verify. Agentic testing is structurally independent from the coding AI, which is what makes it work.
You shipped a feature yesterday in forty minutes. Your AI coding agent rewrote the payment flow, refactored three components, and updated the API contracts. Everything looked right in the preview. You deployed.
Somewhere in that forty minutes, the AI made seventeen decisions you did not review. One of them was wrong. You will find out when a customer hits it.
This is the vibe coding quality problem, and it is not solved by clicking through your app before shipping. In our vibe coding testing gap analysis, we established why AI-to-AI symmetry is the core principle: code generated at AI speed requires tests generated at AI speed. This article goes one level deeper. Not just why you need AI-run tests, but what kind, and why only one approach is structurally equipped to handle what vibe coding actually produces.
The Three Testing Approaches That Don't Work
Before defining what agentic testing is, it helps to understand precisely why the alternatives fail. Not in theory, but in the specific way each one breaks for vibe-coded apps.
Manual QA assumes a human can keep up with the testing surface area. A solo founder vibe-coding five features a week is generating hundreds of new code paths. A QA engineer clicking through critical flows (even a thorough one) covers maybe 20% of what actually matters. The other 80% ships untested. Vibe coding failures happen in the untested 80%.
Traditional test automation (Selenium, Playwright, Cypress) solves the human throughput problem but creates a different one: someone has to write the scripts. Writing a Playwright test for a feature your AI coding agent generated takes longer than the generation itself. In a vibe coding workflow where the codebase can change substantially in a single session, those scripts go stale within days. Selectors break. API contracts shift. The team disables the failing tests and ships anyway. We covered this in depth in Death of the Test Suite; the maintenance burden alone makes traditional automation unsustainable for vibe-coded codebases.
AI-generated tests sound like the obvious fix. Ask your coding AI to write the tests. But there is a structural problem — what we first described as the circularity problem and call here the circularity trap: the same model that generated your implementation will generate tests that confirm what the code does, not what it should do. If the AI misunderstood a requirement when writing the feature, it misunderstands it the same way when writing the test. Both outputs share an identical frame of reference. The tests pass. The bug ships. The green CI suite becomes false confidence at scale. When 41% of all global code is AI-generated (GitHub Octoverse 2025), that false confidence is not a minor risk, it is the primary risk.
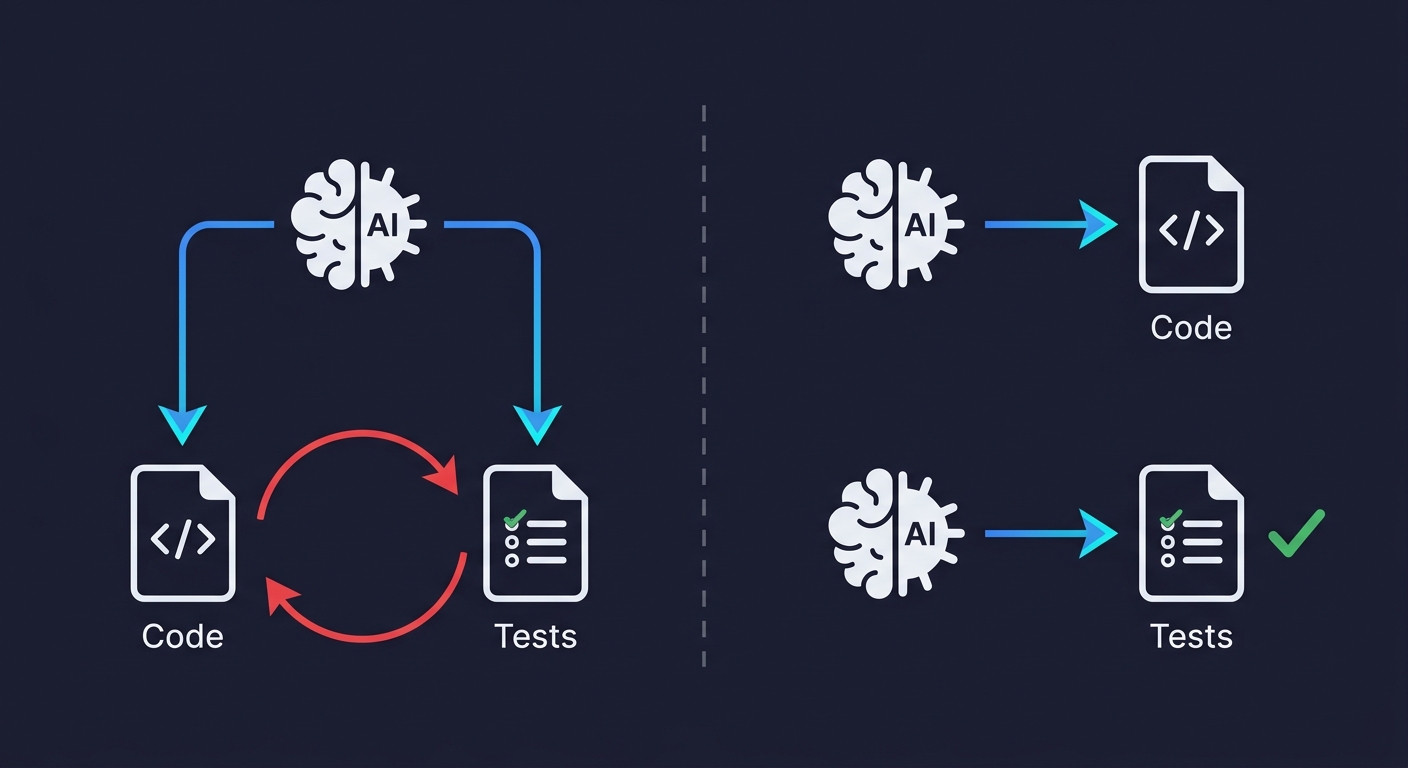
What Agentic Testing Actually Is
Agentic testing is a fundamentally different approach. Instead of a human writing scripts, or an AI generating tests from the same context that generated the code, an independent AI agent reads your codebase and derives test cases from what the application is actually designed to do.
The word "agentic" is precise here. An agent perceives its environment, makes decisions, takes actions, and adapts based on what it observes. It pursues a goal rather than executing a fixed sequence. Applied to testing, this means the agent does not need a human to specify which flows to test, which API contracts to verify, or which edge cases to cover. It reads the routes, components, and user flows directly from the codebase, plans a coverage strategy, and executes it.
At Autonoma, we built this as three specialized agents working in sequence. Some call this autonomous testing. We call it agentic testing because each agent has a distinct role, not because a single system does everything in a black box.
The Planner Agent
The Planner reads your codebase first. It maps routes, analyzes components, traces user flows, and constructs test scenarios grounded in what the application actually does. Critically, it also handles database state setup, which is the part that makes most testing approaches break on complex flows. Before testing a checkout flow, the Planner generates the API calls needed to put the database in the right state. No manual fixture configuration. No test data spreadsheets.
The Automator Agent
The Automator executes those test scenarios against your running application. It navigates your app the way a user would, but with the precision of something that read the codebase beforehand. It knows what the expected behavior is because it derived that expectation from the code itself, not from a test script someone wrote three months ago.
The Maintainer Agent
The Maintainer runs continuously as your codebase evolves. When your coding agent rewrites a component, the Maintainer detects what changed, updates the tests to reflect the new structure, and verifies that the behavior is still correct. Tests don't go stale. Coverage doesn't decay. The regression net stays intact regardless of how aggressively you ship.
Each agent includes verification layers at every step. They don't take random paths through your application. They derive paths from your code, verify them structurally, and execute them consistently. This is what makes agentic testing different from a probabilistic AI trying random interactions. The codebase is the spec, and the agents read it.
The Comparison You Need to Make
The vibe coding testing gap analysis breaks down why each traditional approach fails. Here is how they compare against the agentic alternative in a vibe coding workflow.
| Approach | Who writes the tests | Maintenance burden | Catches AI blind spots | Scales with vibe coding velocity |
|---|---|---|---|---|
| Manual QA | QA engineer, manually | Every sprint | Partially, if tester knows the code | No. Humans can't click fast enough |
| Selenium / Playwright | Engineer, by hand | Every code change | Only if engineer understood AI's decisions | No. Writing scripts takes longer than vibe coding |
| AI-generated tests (Copilot, etc.) | Same AI as the code | Low initially, but circularity compounds | No. Shares the same blind spots | Technically yes, but false confidence scales with it |
| Agentic testing (Autonoma) | Independent AI agents from codebase | Self-healing, no human maintenance | Yes. Structurally independent from coding AI | Yes. Agents read code as fast as it's committed |
| Best for | Teams with dedicated QA headcount and low change velocity | Teams with engineering capacity for script maintenance | Prototype-stage apps where false positives are acceptable | Vibe coding teams shipping daily without dedicated QA |
The key column is "Catches AI blind spots." Manual QA can catch some of them, when the tester knows the codebase well enough to know what questions to ask. Traditional automation catches none of them that the script author didn't anticipate. AI-generated tests catch none of them by definition. Agentic testing catches them because the verification is structurally independent: the testing agent reads the code without inheriting the coding agent's assumptions.
How the Independence Actually Works
The structural independence is worth understanding precisely, because it is what makes or breaks the approach.
When a developer writes a test for code they wrote, they test paths they designed. When an AI writes tests for code it generated, it does the same. Both suffer from the same limitation: verification is downstream of creation, which means it is contaminated by the creator's assumptions.
Agentic testing breaks this by making the testing agent's source of truth the codebase, not the development conversation. Our Planner agent does not have access to the prompts your coding AI received. It does not know what you intended to build. It reads what was actually built (the routes, the controllers, the components, the API contracts) and derives expected behavior from that structure.
This means it tests the decisions the coding AI made silently. The authentication edge cases nobody specified. The race condition the code handles (or doesn't). The database state the user might arrive in. The vibe coding best practices checklist we published covers what a human should verify manually. Agentic testing automates that checklist and extends it to every path in the codebase.
It also means it tests what changes. When your coding agent rewrites a component, the Maintainer reads the diff, understands what behavior changed, and updates the tests accordingly. Not by patching selectors. By re-reading the codebase and re-deriving expected behavior. Flaky tests are a symptom of tests that don't understand the code they're testing. Agentic tests understand the code.
What Changes When You Connect Your Codebase
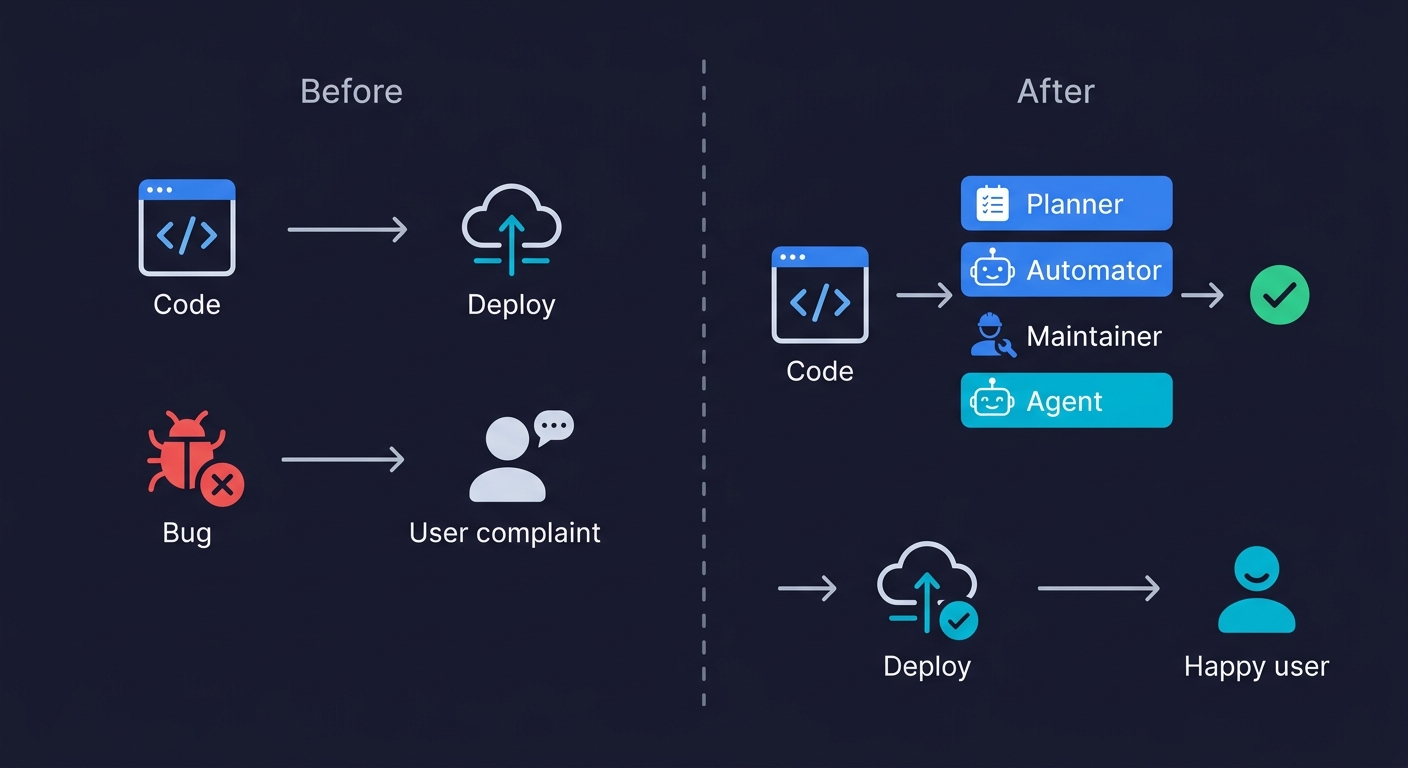
The before-and-after for a vibe coding team looks like this.
Before: you ship a feature. You click through the happy path. You check the console for errors. You deploy. Two days later a user finds an edge case. You debug for three hours. The edge case was in a flow the AI handled differently from what you assumed.
After: you ship a feature. The commit triggers the Planner agent. Within minutes, it has generated test scenarios covering the routes the feature touches, including edge cases derived from the code structure. The Automator executes them against your staging environment. One test fails: the AI's database handling for a concurrent request edge case doesn't match the expected behavior. You fix it before it hits production.
This is not a theoretical improvement. It is the difference between finding bugs in production and finding them in CI. For a team of founders or a small startup moving fast, one production incident costs $8K–$25K and erases weeks of velocity advantage.
The production readiness framework we published includes testing coverage as a scored dimension. Teams that score low on that dimension consistently report the same pattern: things look fine during development, then break in ways that seemed obvious in retrospect. Agentic testing is what closes that gap without adding engineering overhead.
Where Agentic Testing Has Limits
We would rather tell you this directly than have you discover it after connecting your codebase.
Agentic testing covers behavioral correctness: does the application behave as the code says it should? It does not replace design review, security audits, or accessibility testing. The Planner reads your code; it does not know your business requirements. If the AI built the wrong thing (feature-complete but misaligned with what the user actually needs) the agents will verify that the wrong thing works correctly.
This means agentic testing is strongest as a regression and correctness layer, not as a substitute for product thinking. For security risks specific to vibe coding, you still want static analysis tools running in parallel. The documented rate of OWASP vulnerabilities in AI-generated code is caught more reliably by security-specific scanners than by behavioral testing.
There is also a bootstrapping period. The Planner needs a codebase to read. If your app is three screens and four routes, coverage ramps up quickly. If it is a complex legacy system with undocumented internal APIs, the first pass will be less complete than it becomes after several iterations.
Who Gets the Most Value from Agentic Testing
The answer tracks with how much vibe coding you're doing and how few testing resources you have.
Solo founders and non-technical builders get the most dramatic shift. You were testing by clicking through the app before shipping. Now you have something that reads your codebase and generates test coverage automatically. No learning curve, no test script knowledge required. If testing a vibe-coded app without coding knowledge felt like a solved problem before, agentic testing is what actually solves it.
Startup engineering teams of 2-8 people are where the ROI is clearest. A team without a dedicated QA function (which is most early-stage startups) either ships untested code or pays an engineer to write Playwright scripts. Neither is a good outcome. Shipping reliable software without a QA team requires infrastructure that covers the testing surface area without consuming engineering time. Agentic testing is that infrastructure.
QA professionals at teams adopting vibe coding are the audience whose role shifts most significantly. If your team is now generating code ten times faster, your existing testing coverage cannot keep pace. The choice is not "write tests faster"; it is not possible. The choice is "adopt the infrastructure that matches the new velocity." The continuous testing loop that agentic testing enables is what a modern QA function looks like in a vibe coding environment.
The engineering leadership data on vibe coding quality failures shows the pattern clearly: teams that hit quality disasters within 90 days all had one thing in common. Their testing approach was designed for a world where humans wrote the code. Manual QA, handwritten Playwright scripts, or no testing at all. None of those approaches scale to a world where an AI agent can restructure your checkout flow in forty minutes.
The vibe coding bubble argument is that nobody is testing what AI ships. That is the surface observation. The deeper truth is that most teams are using testing approaches that predate AI code generation by a decade. The mismatch between AI-speed code generation and human-speed testing is not a temporary growing pain. It is a structural problem that requires a structural solution.
Agentic testing is that solution. Here is what it looks like in practice.
What Getting Started Looks Like
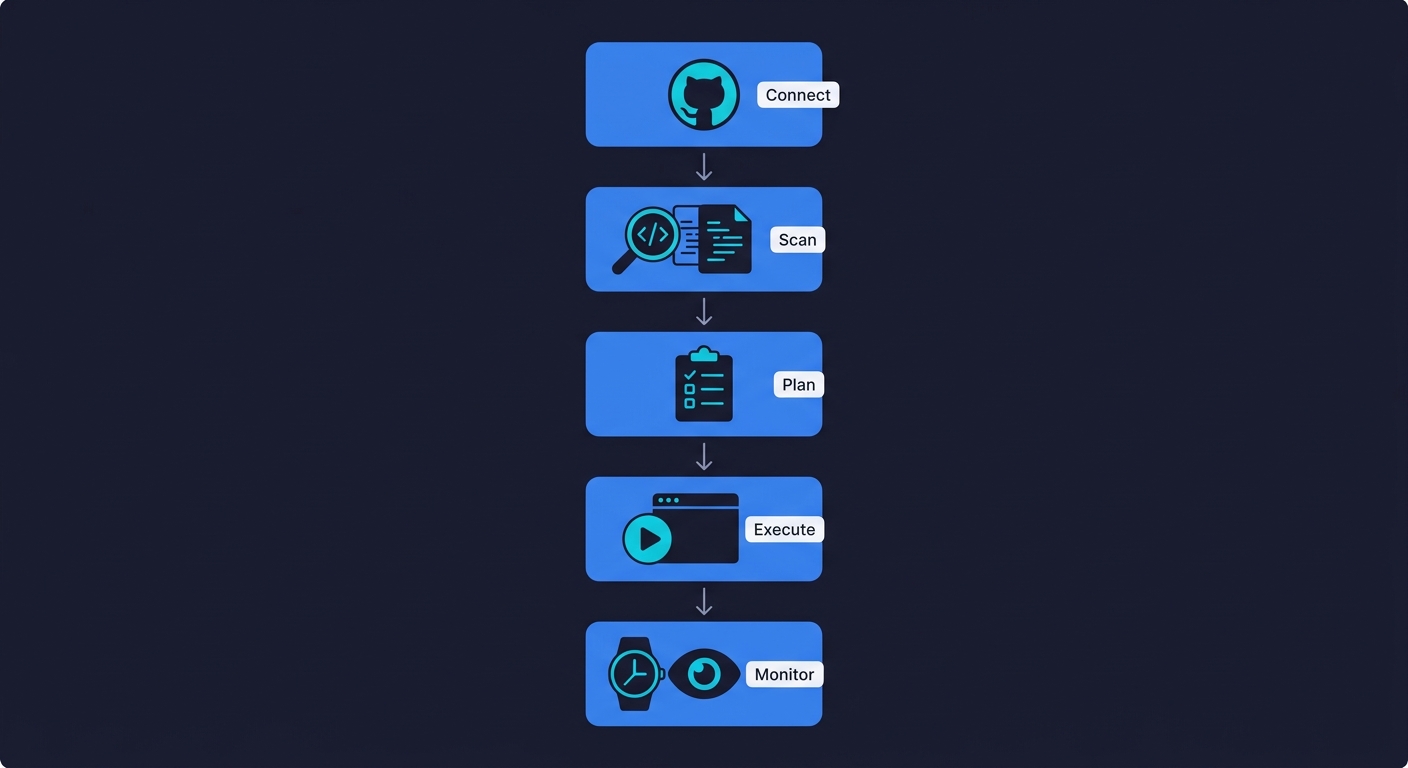
The entire setup takes minutes, not sprints.
Step 1: Connect your repository. Point Autonoma at your GitHub or GitLab repo. No configuration files, no test framework installation.
Step 2: The Planner scans your codebase. Within minutes, it maps your routes, components, and user flows. It generates a test plan covering the critical paths it identified, including the database state setup needed for complex flows.
Step 3: Review the test plan. You see which flows the Planner identified and what scenarios it will run. You can adjust priorities or add context, but most teams find the auto-generated plan covers more than they expected.
Step 4: The Automator executes against your staging environment. Tests run against your live application. Results show which flows pass, which fail, and exactly where the failures occur.
Step 5: The Maintainer watches your commits. From this point forward, every push triggers incremental re-analysis. Changed routes get re-tested. New components get new coverage. Tests self-heal as selectors and contracts evolve.
The first run typically surfaces issues that would have reached production within the week. After that, the continuous testing loop runs on its own.
Try Autonoma free and connect your codebase. No scripts, no recording, no maintenance. The codebase is the spec.
Frequently Asked Questions
Agentic testing for vibe coding means connecting your codebase to AI agents that independently plan test scenarios, execute them against your running application, and self-heal when your code changes. The key difference from other AI testing approaches is structural independence: the testing agents read your codebase directly without sharing the assumptions of the AI that wrote the code. This breaks the circularity problem where an AI that generated buggy code generates tests that confirm the bug is correct behavior. Autonoma implements agentic testing with three specialized agents: a Planner that maps your routes and flows, an Automator that executes tests, and a Maintainer that keeps tests current as code evolves.
Because the same model that wrote your code will write tests that confirm what the code does, not what it should do. This is the circularity trap. If the AI misunderstood a requirement when generating the implementation, it misunderstands it identically when generating the tests. Both outputs share the same frame of reference. The tests pass while the bug ships. At scale, this creates false confidence that is worse than no tests at all. It gives you a green CI suite you trust, while real edge cases remain uncovered. Agentic testing breaks this by using an independent agent that reads the codebase without inheriting the coding AI's context.
Traditional tools like Playwright and Selenium require an engineer to write and maintain test scripts by hand. In a vibe coding workflow, writing those scripts takes longer than generating the feature. When the AI coding agent rewrites a component, the scripts break. Within weeks, teams find that a significant portion of their test suite is disabled or skipped because it's too stale to trust. Agentic testing eliminates both problems. The Planner agent reads your codebase and generates the test scenarios automatically. The Maintainer agent updates those tests as code changes, so the coverage never goes stale. No scripts, no maintenance, no engineering time spent on test authoring.
Yes. Agentic testing requires no knowledge of testing frameworks, no script writing, and no understanding of selectors or API contracts. You connect your codebase to Autonoma, and the agents take it from there. The Planner reads your code and generates test coverage based on what your application actually does. This is specifically why agentic testing is the right approach for non-technical builders using vibe coding tools: the alternative approaches all require engineering knowledge you don't have. The codebase is the spec, and the agents read it. You don't need to.
Autonoma is the agentic testing tool built specifically for the vibe coding workflow. It connects directly to your codebase, uses three specialized agents (Planner, Automator, Maintainer) to generate and maintain tests automatically, and handles complex scenarios like database state setup without manual configuration. For teams that need behavioral coverage across routes, components, and user flows without writing scripts or maintaining test suites, Autonoma is the native solution.
No. Vibe testing refers to writing tests in natural language and letting an AI tool convert them into executable scripts. It still requires a human to decide what to test and how to phrase it. Agentic testing is fundamentally different: the AI agents independently read your codebase, derive what needs to be tested, generate the test scenarios, execute them, and maintain them as code changes. You do not need to specify what to test or write anything at all. Vibe testing makes test authoring faster. Agentic testing eliminates test authoring entirely.
Agentic testing catches behavioral correctness issues: cases where the application does not behave as the code specifies it should. This catches many security-adjacent bugs, like authentication edge cases, session handling errors, and improper permission checks that manifest as behavioral failures. However, for deep security analysis (XSS, SQL injection, OWASP Top 10) you still want static analysis security scanners running in parallel. The 45% of AI-generated code samples that introduced OWASP vulnerabilities are best caught by purpose-built security tools. Agentic testing and security scanning are complementary, not alternatives.
