Vibe Coding Tripled Your Bug Rate. Here's the Triage Playbook for the Week After It Happens.

Vibe coding quality issues describe the quality collapse that happens when engineering teams adopt AI-assisted development without corresponding quality guardrails. The pattern is consistent: output velocity doubles, but the vibe coding bug rate climbs 2-3x within 4 to 12 weeks. Of the engineering leaders we surveyed, 16 out of 18 reported a significant quality incident tied to vibe coding within their first 90 days of adoption. This article is the field guide for what to do after the bug rate spikes — how to stabilize fast, diagnose the root cause, and build a governance model that lets your team keep the speed without the chaos.
The incident is over. The post-mortem is written. Your team fixed the bug, documented the root cause, and everyone is back to shipping. But you're sitting with a harder question than "what broke" — you're asking "what do we change so this doesn't keep happening?"
That question is harder because the answer isn't technical. The code your AI tools write isn't the problem. The process your team runs around that code is. Vibe coding quality issues almost never trace back to a model hallucination or a bad suggestion. They trace back to a review culture that got calibrated for human-written code and never updated when the output rate tripled.
You can't slow the AI down. Your team won't accept that, and honestly, you shouldn't ask them to. What you can do is build a governance model that matches how AI-assisted development actually works, not how code review worked in 2019. That's what this article is.
The Pattern Is Predictable (And You Are Not Alone)
Before jumping to the triage playbook, it is worth naming the pattern clearly — because most engineering leaders who hit this moment assume they did something uniquely wrong. They did not.
We surveyed 18 engineering leaders across companies ranging from 10-person startups to 200-person scale-ups. Sixteen of them reported a significant quality incident within the first 90 days of their team adopting vibe coding practices at scale. The common thread was not the tools. It was the governance gap.
The pattern looks like this: in the first few weeks after a team broadly adopts AI-assisted coding, velocity climbs sharply. Tickets close faster. Standups feel good. Everyone is excited. Management is pleased. Then, around week four to eight, something starts creaking. Bugs in QA become more frequent. Code review starts surfacing strange issues — logic that is subtly wrong, edge cases that were never considered, dependencies that were silently introduced. By week eight to twelve, customer-facing bugs appear. By week twelve to sixteen, the vibe coding bug rate has doubled or tripled from the pre-AI baseline. Industry data supports this: a CodeRabbit analysis of 470 open-source GitHub PRs found that AI co-authored code contained 1.7 times more major issues than human-written code, and a Veracode study found that 45% of AI-generated code failed security testing on first pass.
The reason the pattern is so consistent is that vibe coding does not change what software needs to be correct. It changes who is responsible for catching what is wrong. Before AI tools, developers wrote code slowly enough that they caught many bugs during the writing process. With AI tools, code is generated faster than developers can mentally audit it. The review step did not get faster with AI. It got harder.
What You Should Do Right Now (The Monday Morning Playbook)
If you are in the middle of a quality crisis right now, here is the triage sequence that actually works.
Stop the bleeding first. Before diagnosing root causes, reduce the blast radius. This means temporarily tightening your deployment gates: require two reviewers for any AI-generated PR, add a mandatory smoke test run before any merge to main, and put a brief hold on deploying AI-assisted changes to your most critical paths (payment, auth, data writes). You are not banning AI tools. You are buying yourself 72 hours to diagnose without continuing to introduce new risk.
Identify the high-risk surface area. Not all code is equally dangerous. Pull the last 30 days of production incidents and tag each one by the category of change that caused it. You will almost certainly find a pattern: auth logic, payment flows, data migration scripts, and API integrations are where AI-generated bugs are disproportionately concentrated. These are the areas where edge cases matter most and where AI tools are most likely to generate plausible-but-wrong logic. Map them. These become your tier-one coverage targets.
Run a coverage audit, not a code audit. The instinct after a quality incident is to audit the code itself. This is mostly a waste of time. You cannot read 40,000 lines of AI-generated code and find the bugs manually. What you can do is audit your test coverage across the high-risk surface area you just identified. Where are you testing nothing? Where are you testing superficially? Those gaps are your actual risk map.
Have an honest conversation with your team. This is the one most leaders skip. The developers on your team who are using AI tools know exactly where they have been cutting corners on review. They know which PRs they approved too quickly. They know which generated functions they did not fully understand. Creating psychological safety to surface this information is worth more than any process change. Ask: "Where do you feel most uncertain about code we've shipped in the last month?" The answers will be uncomfortable. They will also be more useful than any static analysis tool.
Establish a temporary incident watch rotation. For the next two to four weeks, have someone monitoring production error rates and user-facing error signals actively every day. Not passively through dashboards — actively, with intent to catch signals early. This is not a permanent process. It is a containment measure while you build proper quality infrastructure.
Risk Tiers for AI-Generated Code
When mapping your high-risk surface area, this classification helps prioritize where to focus review and testing effort:
| Risk Level | Code Categories | Review & Testing Requirements |
|---|---|---|
| High Risk | Auth/login flows, payment processing, data writes/migrations, PII handling, API integrations with external services | Two-reviewer minimum, mandatory test coverage for happy path + error states, security review |
| Medium Risk | Business logic, data transformations, state management, API route handlers, form validation | Standard review with intent-level focus, test coverage for happy path required |
| Low Risk | UI scaffolding, config files, boilerplate, documentation, styling, internal tooling | Standard single-reviewer, testing optional |
Why the Vibe Coding Bug Rate Spikes: Three Failure Modes

This is worth understanding properly, because the wrong mental model leads to the wrong fix.
Vibe coding quality issues are not random noise that increases proportionally with code volume. They have a specific signature. AI-generated code fails in categories: boundary conditions, multi-step state logic, and integration edge cases. It tends to handle the happy path with high fidelity and handle error states badly or not at all.
The reason is structural. AI models were trained on code that represents the happy path far more than the error paths. Most code on GitHub is code that works. Code for failure cases, edge cases, and defensive programming is underrepresented. So AI tools generate code that is confident and functional on the expected path and quietly incomplete everywhere else.
This matters for your governance framework because it tells you where to concentrate quality effort. You do not need to test everything with equal rigor. You need to test the boundary conditions and the error states that AI tools systematically underproduce.
The second failure mode is subtler. AI tools are very good at making code that looks correct. A human reviewer reading AI-generated code is naturally inclined to trust it because it is readable, well-named, and internally consistent. The logic sounds right. The problem is often not in the syntax or the style but in a semantic assumption the AI made that happens to be wrong for your specific application context. A function that calculates a discount correctly in general but applies it before tax rather than after. A validation that checks the right field but uses the wrong comparison operator for your data format. These bugs pass review because they require knowledge of your specific business rules to catch — knowledge the AI did not have and the reviewer did not apply.
The third failure mode is dependency drift. AI tools readily introduce new libraries, utilities, and patterns. Over a few months of vibe coding at scale, a codebase can accumulate a significant number of silently-introduced dependencies that nobody fully understood or intentionally chose. This is where vibe coding tech debt becomes most insidious — it accumulates silently through dependencies nobody chose deliberately. These create upgrade risks, security surface area, and maintenance burden that compounds over time.
The fourth failure mode is security. AI tools reproduce insecure patterns from their training data: SQL injection vectors, hardcoded credentials, cross-site scripting vulnerabilities, and improper input validation. These bugs are especially dangerous because they pass functional review — the code works correctly in testing but is exploitable in production. We covered the security dimension in depth in our analysis of vibe coding security risks, but the short version is this: AI-generated code that handles user input, authentication, or data access should be treated as untrusted until specifically reviewed for security, regardless of how clean it looks. If you want to see what these failures look like in practice, our breakdown of 7 real vibe coding failures documents the exact root causes and the tests that would have caught them.
The Vibe Coding Governance Framework: Not a Rollback, a Ratchet
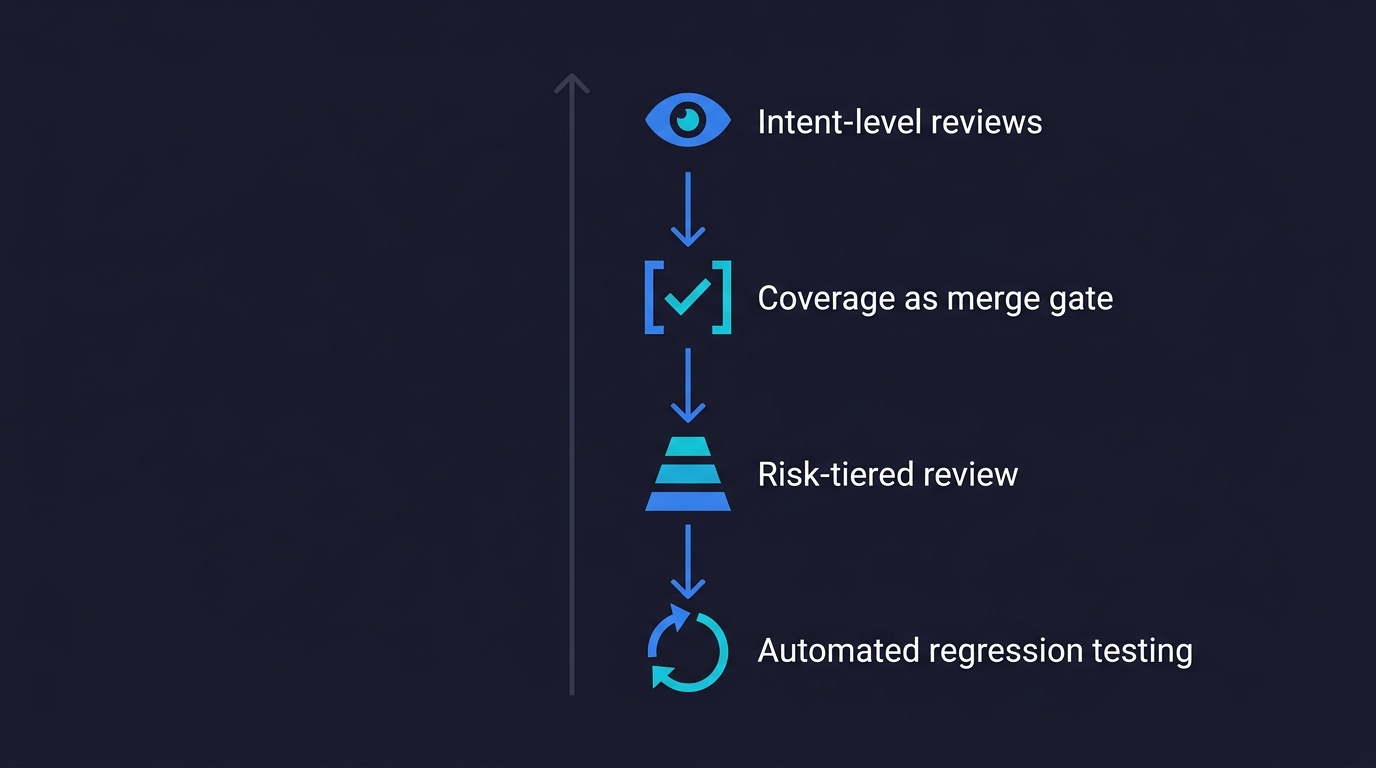
The wrong response to vibe coding quality issues is to pull back on AI tool usage. That has two problems. First, it is politically nearly impossible — your developers have adopted these tools and they are genuinely more productive with them. Second, it addresses the symptom, not the cause. The cause is that velocity increased without governance increasing to match.
The right response is what we call The Quality Ratchet — a framework with four components, where every step you take toward more AI-assisted development is matched by a corresponding step toward more automated quality assurance. This is not an AI code quality management overhead. It is the infrastructure that makes AI-assisted velocity sustainable.
Here is what The Quality Ratchet looks like in practice.
1. Shift Reviews From Line-by-Line to Intent-Level
Traditional code review is line-by-line because a human wrote every line and every line represents a decision. AI-generated code cannot be reviewed this way at volume. It is too much to read. Instead, reviewers need to shift to intent-level review: does this code do what the ticket says it should do, in the context of our actual application, for all plausible inputs including the ones we did not write in the ticket? This requires reviewers to think about the code rather than read it. It is a different skill and it needs to be explicitly developed. For more on how vibe coding changes the QA role, we wrote a dedicated breakdown.
2. Make Coverage a Merge Gate
Most teams track test coverage as a metric they review in retrospect. Under vibe coding, this is too slow. Coverage needs to become a merge gate: no PR that touches a critical path ships without test coverage for the happy path and the primary error states. You are not requiring 100% coverage. You are requiring coverage of the scenarios that matter. This is the structural fix for the testing gap that vibe coding creates.
3. Tier by Risk, Not by Author
Some engineering teams have tried to create two-tier review for "AI code" versus "human code." This is the wrong distinction. Risk tier should be based on what the code does, not how it was written. A human-written payment processing function deserves as much scrutiny as an AI-written one. A trivial AI-written config change does not deserve more scrutiny just because AI wrote it. Build your review and testing requirements around what is at stake, not around who (or what) wrote it.
4. Automate the Regression Floor
This is the most important structural change. Your developers cannot manually test every scenario every time they ship. The only sustainable answer is automated end-to-end testing that runs on every deployment and catches regressions before they reach users. The teams that vibe code successfully at scale are the ones where automated testing is doing the heavy lifting that human review cannot do at volume.
What Automated Testing Looks Like in Practice for Vibe Coding Teams
The teams that make vibe coding work at scale share one thing: they are not writing their tests manually either.
The logic is straightforward. If your code generation is AI-assisted, your test generation should be too. The development velocity that AI tools create makes hand-written test suites a bottleneck. You can't write tests as fast as AI generates code. Any gap between code velocity and test coverage velocity is risk accumulating in your codebase.
This is the problem Autonoma was designed for. Rather than asking developers to write and maintain test scripts at AI-code-generation speed, Autonoma's agents analyze your codebase and generate regression coverage that runs on every deployment. When the code changes — which, in a vibe coding workflow, is constantly — the tests adapt automatically. The result is a quality floor that scales with your team's output velocity instead of falling behind it.
The integration takes about a day. After that, every deploy triggers automated coverage of your critical paths. Bugs that would have reached production — the ones buried in boundary conditions and error states that AI tools characteristically miss — get caught in CI instead.
The Conversation You Need to Have With Your Team
Before any framework, tool, or process change lands, there is a human moment that most engineering leaders skip because it is uncomfortable.
Your team needs to hear that the quality problem is not their fault, and also that they are responsible for fixing it. Both things are true. The AI tools your team adopted are genuinely excellent. They also created conditions your existing quality process was not designed for. The team used the tools as directed. The process did not evolve fast enough to match. That is a leadership problem, not an individual failure.
The way to have this conversation well: name the pattern clearly (not a talent problem, a process gap), show the data (the coverage audit, the incident cluster analysis), and present the governance changes as guardrails that exist to protect speed, not to restrict it. The fastest-moving engineering teams in the world have more process than the slow ones, not less. The process is what makes speed sustainable.
Most developers, when you frame quality governance this way, will want to participate. They are not trying to ship bugs. They are trying to ship fast. Show them a path that does both and they will build it with you.
The Longer Game: Quality as a Competitive Advantage
This article has been about triage. But the teams that are going to win the next few years of software development are the ones that figure out how to make quality a competitive advantage, not just a cost center.
Vibe coding is not going away. The productivity gains are real and the tools are getting better. The question is not whether vibe coding is production ready — it is whether your vibe coding team management practices are ready for production. The engineering leaders who build governance frameworks that scale with AI-assisted development will have teams that ship faster and more reliably than those who either reject AI tools or adopt them without guardrails. The cost of poor software quality hit $2.41 trillion annually before AI tools accelerated the rate of code production. Without governance, that number only grows.
The goal is not to choose between speed and quality. It is to build systems where they reinforce each other: AI coding generates features fast, AI testing generates coverage fast, and the combination produces a team that ships more, breaks less, and compounds its advantage over time.
You are already past the point of deciding whether your team will vibe code. The question is whether you will build the quality infrastructure to make it sustainable. Start with the triage playbook this week. Start the governance conversation with your team next week. The infrastructure comes after you have stabilized the immediate crisis.
The bugs are fixable. The pattern is understandable. The framework exists. You just need to use it. For the developer-level checklist your team can start using immediately, see vibe coding best practices. For a deeper look at why traditional test suites break down under AI-speed development, see vibe coding and the death of the test suite.
The most common vibe coding quality issues fall into four categories: boundary condition failures (AI-generated code handles the happy path but silently breaks on edge cases), error state gaps (AI tools underreproduce defensive error handling), domain logic errors (AI generates plausible code that is wrong for your specific business rules), and security vulnerabilities (AI reproduces insecure patterns from training data). A CodeRabbit analysis found AI co-authored code has 1.7x more major issues than human-written code. Teams adopting AI tools at scale consistently see the vibe coding bug rate climb 2-3x within 4-12 weeks because code velocity increases faster than review and testing capacity. The fix is not slowing down AI adoption but building automated quality infrastructure that matches the pace of AI code generation.
The immediate triage sequence: first, tighten deployment gates temporarily (require two reviewers on AI-generated PRs, run smoke tests before merging to main). Second, identify your highest-risk surface areas by reviewing recent production incidents and tagging them by change category. Third, audit your test coverage against those high-risk areas rather than trying to audit the code itself. Fourth, have an honest conversation with your team about where they feel most uncertain about recently-shipped code. Fifth, establish a temporary incident watch rotation for 2-4 weeks while you build proper automated testing infrastructure.
No. Banning AI tool usage after a quality incident addresses the symptom rather than the cause. The cause is that development velocity increased without quality governance increasing to match. The sustainable path forward is a governance ratchet: shift code review from line-by-line to intent-level, make test coverage a merge gate rather than a retrospective metric, tier review requirements by what the code does (not who wrote it), and automate your regression testing floor. Teams that implement this governance framework keep the productivity benefits of vibe coding while building a quality baseline that is actually more robust than their pre-AI process.
Effective vibe coding governance has four components. Intent-level code review: reviewers assess whether the code does what the ticket requires for all plausible inputs, not whether each line looks correct. Coverage as a merge gate: critical path changes require test coverage for the happy path and primary error states before shipping. Risk-tiered review: scrutiny is based on what the code does, not how it was written (an AI-generated config change deserves less scrutiny than a human-written payment function). Automated regression testing: end-to-end tests run on every deployment to catch regressions that human review misses at velocity. [Autonoma](https://getautonoma.com) automates the last component -- agents read your codebase, generate test coverage, and self-heal tests as code changes.
The framing that works: the quality problem is not a talent failure, it is a process gap. AI tools moved your team to a higher velocity. Your quality process did not evolve at the same pace. That is a leadership and systems problem, not an individual failure. Present quality governance changes as guardrails that protect speed rather than restrict it. The fastest engineering teams in the world typically have more process than slow ones, not less. Show your team a path to sustainable speed: AI coding for velocity, AI testing for coverage, and clear review standards that let everyone move fast with confidence.
The best automated testing solutions for vibe coding teams are ones that can match the pace of AI code generation -- meaning they should not require manual test script writing or ongoing maintenance. The top options include [Autonoma](https://getautonoma.com) (agents read your codebase and generate E2E tests automatically, with self-healing as code changes), Playwright with AI-assisted test generation, and Cypress for teams with existing JavaScript testing infrastructure. Autonoma is purpose-built for the vibe coding use case: no test scripts, no maintenance, coverage that self-heals as your AI-generated codebase evolves.
