
Vibe coding security risks include an entire class of vulnerabilities that static scanners cannot detect. SAST tools and secret scanners are pattern matchers: they compare your code against known vulnerability signatures. They catch XSS patterns, SQL injection, exposed credentials, and outdated dependencies. What they cannot do is run your application and observe whether it behaves correctly. Broken object-level authorization (IDOR), business logic bypasses, frontend-only validation, and race conditions in financial flows are all invisible to scanners, and they are disproportionately common in AI-generated code. The result is a false sense of security: a clean scanner report on a vibe-coded app does not mean the app is secure. It means no known code patterns were found. Those are different claims.
Your scanner came back clean. You shipped.
That is the scenario that should worry you more than a scanner that found something. A scanner report with zero findings on a vibe-coded application is not a green light. It is a measurement of one specific slice of your risk surface, a slice that happens to exclude the most common failure modes of AI-generated code.
The broader statistics on vibe coding security vulnerabilities are already well-documented. This post is about something narrower and more uncomfortable: what happens to teams who run scanners, see clean results, and conclude they are covered.
What Scanners Actually Do (And Do Well)
Before attacking scanner limitations, give them credit. Static analysis tools have a genuine, important job, and they do it well.
SAST tools like Semgrep, Snyk, and SonarQube read your source code as text and compare it against libraries of known vulnerability patterns. They find things like SQL string concatenation that enables injection: SELECT * FROM users WHERE id = ' + userId where a parameterized query should be. They flag use of deprecated cryptographic functions, MD5 for password hashing being the textbook case. They catch dependency versions with published CVEs before those dependencies ever reach production. Secret scanners find API keys and tokens in source files before they are committed.
These are real vulnerabilities. Catching them matters. The tools are fast, they integrate into CI pipelines without much friction, and they scale to codebases of any size. A team that runs no static analysis is genuinely more exposed than a team that does.
DAST tools (Burp Suite, OWASP ZAP) take a different approach. They send malicious payloads to a running application and observe responses. They catch injection vulnerabilities and some authentication flaws that SAST misses. But DAST tools still work from predefined attack patterns. They cannot infer your business rules, your plan limits, or your ownership model. They are better than SAST at finding runtime injection issues, but the scanner gap described in this post affects both categories.
The problem is not that scanners are bad. The problem is that teams treat a clean scanner report as a security posture, when it is really just one input into a much larger question: does this application behave the way it should?
What Security Scanners Miss in Vibe-Coded Apps
Scanners read code. They do not run applications.
That distinction is fine when the most dangerous vulnerabilities live in the code itself. A hardcoded password is visible in the source. An unparameterized SQL query is readable as text. These things exist in the file, and a pattern matcher can find them.
The most common critical vulnerabilities in vibe-coded applications are different. They are not patterns in the code. They are behaviors at runtime, things that only become visible when you actually make an HTTP request, observe the response, and check whether the server did what it was supposed to do.
Here is what that looks like in practice across the four vulnerability categories that scanners consistently miss.
IDOR / Broken Object-Level Authorization (CWE-639)
OWASP's API Security Top 10 ranks broken object-level authorization as the number one API vulnerability. Not because it is exotic, but because it is everywhere and consistently invisible to automated code analysis.
The pattern: your application has an endpoint like GET /api/documents/:id. A scanner reads the route handler, sees that it requires authentication, and marks it acceptable. Clean bill of health.
What the scanner cannot verify: does the authentication check confirm that the authenticated user owns document with that ID? The code might check for a valid session token. It might not check whether that session belongs to the user who created the document. Those are different checks, and the second one is frequently missing from vibe-coded applications.
Here is the actual code a vibe coding tool might generate:
// What the AI generates - looks correct to a scanner
app.get('/api/documents/:id', authenticate, async (req, res) => {
const document = await db.documents.findById(req.params.id);
if (!document) return res.status(404).json({ error: 'Not found' });
return res.json(document);
});The authenticate middleware is there. The scanner sees it and moves on. The missing check: there is no if (document.userId !== req.user.id) before returning the document. User A can request document 847, which belongs to User B, and the server returns it without complaint.
A behavioral test catches this in seconds:
// Test that a scanner cannot replicate
test('User cannot access another user document', async () => {
const userA = await createTestUser();
const userB = await createTestUser();
const docId = await createDocument(userB.id);
const response = await request(app)
.get(`/api/documents/${docId}`)
.set('Authorization', `Bearer ${userA.token}`);
expect(response.status).toBe(403);
});The test authenticates as User A, requests User B's document, and asserts a 403 response. If the server returns a 200, the vulnerability is confirmed. The scanner cannot make this test. It can only read the route handler and note that authentication is present.
Frontend-Only Validation (CWE-602)
Vibe coding tools generate React components with full validation logic. The form checks that an email field contains a valid email, that a price field is a positive number, that a required field is not empty. The scanner reads the component, sees the validation, considers the input validated.
The API endpoint that receives the form submission often has no server-side validation at all. The tool generated a working form, and the form works. What the tool missed: the API is a separate surface from the form. Anyone who calls the API directly (with curl, with Postman, with a script) bypasses the form entirely.
This matters more in vibe-coded apps than in traditionally-written ones because the developer-as-QA mental model does not exist. A human developer who writes a form usually has some sense that the API is also an attack surface. A vibe coding tool generating a form has no such mental model. It generates code that satisfies the stated requirement, and the stated requirement was "build a form that validates X."
The test is straightforward:
// Bypass the form, call the API directly with invalid data
test('API rejects negative price even when form would block it', async () => {
const response = await request(app)
.post('/api/products')
.set('Authorization', `Bearer ${user.token}`)
.send({ name: 'Test Product', price: -500 });
expect(response.status).toBe(400);
});If this returns a 201 with a product at -$500, there is no server-side validation. The scanner found the client-side validation and had nothing more to say.
Business Logic Errors
This is the category where the scanner gap is most fundamental. Scanners work from a library of known vulnerability signatures. Business logic bugs, by definition, do not have signatures. They are errors in how an application implements its own specific rules, rules that are unique to each application.
Some common patterns in vibe-coded apps:
Plan limit enforcement only in the UI. A free-tier user is capped at 5 projects. The limit check fires when the "Create Project" button renders and it is grayed out when the count reaches 5. The API endpoint that creates projects has no limit check. Call the API directly after hitting the UI limit and project 6 creates without complaint.
Coupon and credit double-spending. A coupon can be applied once per account. The check runs at application time, not at an atomic transaction level. Submit two redemption requests simultaneously and both succeed: two discounts for the price of one. No scanner has a signature for "this coupon redemption is not idempotent under concurrent requests."
Privilege escalation through role assignment. An admin endpoint allows changing a user's role. The code checks that the requester is authenticated. It does not check whether the requester is an admin. A regular user can promote themselves by calling the endpoint directly.
The only way to catch business logic errors is to write tests that encode your business rules and verify they are enforced at the API layer. That is not something a scanner can approximate.
Race Conditions (CWE-362)
Race conditions in critical operations are a class apart. They do not exist in the code at rest. They emerge from the timing of concurrent requests against a shared state. A scanner reading a redemption handler sees the check-then-act sequence. It cannot simulate two clients hitting that endpoint at the same millisecond.
The classic example: a gift card or one-time coupon with a database check followed by a redemption update.
// Looks fine in a scanner - vulnerable under concurrent load
app.post('/api/redeem-coupon', authenticate, async (req, res) => {
const coupon = await db.coupons.findById(req.body.couponId);
if (coupon.redeemed) return res.status(400).json({ error: 'Already redeemed' });
// Time window: between this check and the next update, another request can pass the check above
await db.coupons.update({ id: coupon.id, redeemed: true });
await db.orders.applyDiscount(req.user.id, coupon.discount);
return res.json({ success: true });
});Two requests arrive within milliseconds of each other. Both read coupon.redeemed === false. Both proceed. Both apply the discount. The coupon is now used twice.
A test that fires two simultaneous requests and asserts exactly one discount was applied catches this. The fix is a database-level lock or an atomic check-and-set operation. The scanner sees the check, sees the update, and reports no vulnerability. The race condition is a runtime behavior, not a code pattern.
Why AI-Generated Code Security Falls Short
The scanner blind spots described above affect all codebases. They are disproportionately common in vibe-coded apps for a specific, structural reason: AI code generators optimize for functional correctness, not defensive completeness.
When a developer writes a GET /api/documents/:id endpoint, they carry a mental model of the security requirements. They know to check ownership because they have seen what happens when that check is missing, through security training, code review, and past incidents. That knowledge shapes what they write.
A vibe coding tool has no such model. It generates code that satisfies the stated prompt. The prompt was "create an endpoint to retrieve a document by ID." The tool generated a working endpoint. The ownership check was not in the prompt, so it was not generated.
This is not a criticism of the tools. It is a description of what they are: extremely capable code generators that are only as secure as the requirements they are given. The issue is that human developers implicitly provide security requirements through their domain knowledge. Vibe coding tools do not have domain knowledge to draw on. They have the prompt.
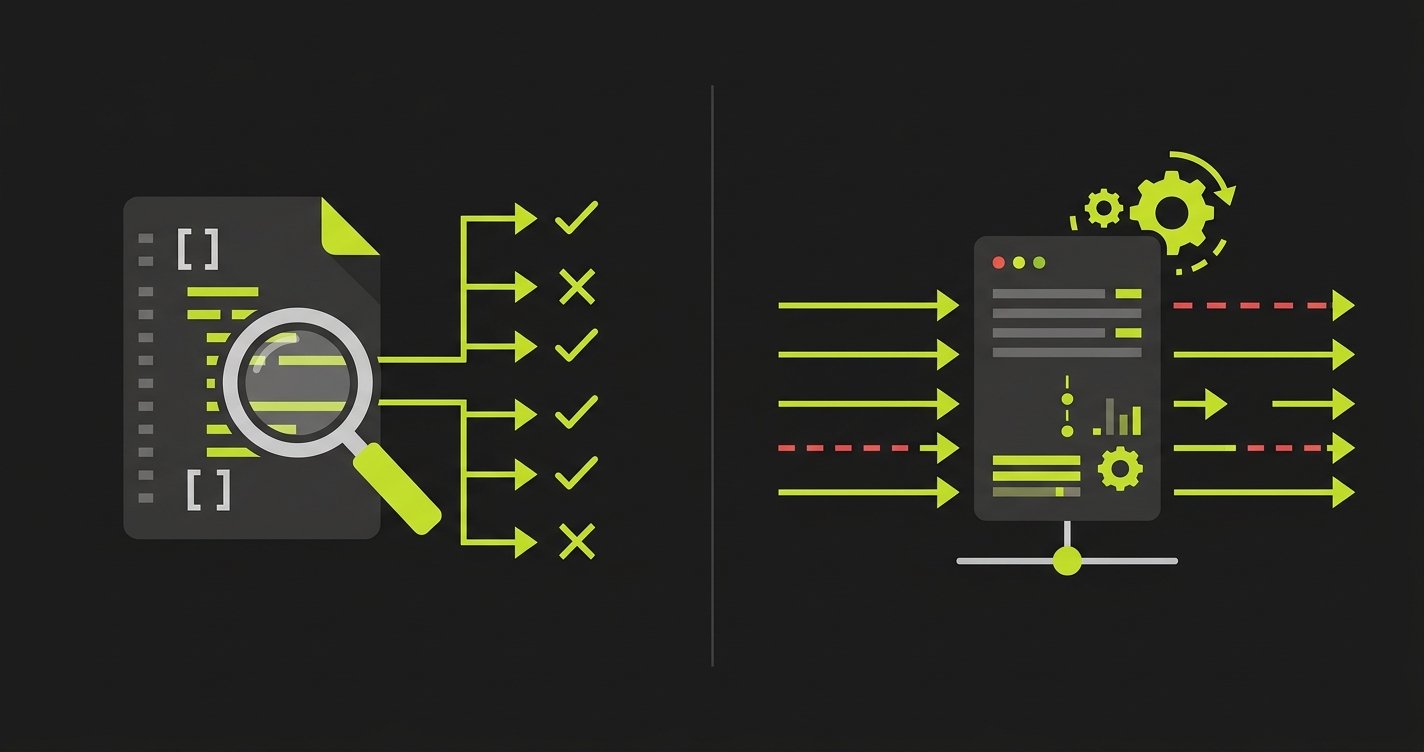
The consequence is a consistent pattern: vibe-coded applications have structurally correct security scaffolding (authentication middleware, token generation, validation components) without the enforcement wiring that connects the scaffolding to actual data access. The scanner sees the scaffolding. The test sees whether the wiring works.
Kaspersky's research added another dimension: they tracked how vulnerability counts changed across multiple iterations of AI-generated code. After five revision cycles, the code contained 37% more critical vulnerabilities than the initial generation. Prompts focused on features introduced new security gaps even when the original code was clean. Each iteration without a behavioral test suite is an iteration where the gap between "scanner says clean" and "application is actually safe" widens.
For the broader picture of how vibe coding failures compound in production, the pattern is consistent: the structural code looks correct, the behavioral enforcement is missing, and neither the developer nor the scanner caught it before launch.
What Actually Catches Business Logic Bugs in AI Code
The answer is behavioral testing: tests that interact with a running application and assert on what it actually does, not on what the code says it should do.
This is not a new insight. Security-conscious engineering teams have run authorization tests, input fuzz tests, and state integrity tests for years. What is new is the gap between how fast vibe coding tools ship applications and how slowly testing practices have kept up with that speed.
The specific tests that close the scanner gap are not complex to write once you know what to target.
Authorization boundary tests for every endpoint that returns or modifies user-scoped data. The pattern: authenticate as User A, request a resource that belongs to User B, assert a 403. This single test pattern covers the most common critical vulnerability class in APIs. One test per endpoint, written once, running on every deploy.
Direct API tests that bypass the form. For every data-accepting endpoint, write tests that send inputs the frontend would never permit: negative numbers where positive is required, empty required fields, strings longer than the UI would allow, SQL fragments, script tags. These run against the API directly, not through the browser, not through the form component. They find the validation gap in minutes.
Business rule enforcement tests. Encode your plan limits, coupon redemption rules, and role requirements as tests at the API layer. A free-tier user tries to create project 6. A regular user tries to call an admin endpoint. A coupon gets submitted twice. Each of these should produce a predictable server response, and the test verifies that the server actually produces it.
Concurrent request tests for state-critical operations. For any endpoint that involves a check-then-act pattern on shared state, fire two simultaneous requests and assert the expected idempotent result. This is where race conditions in financial flows get caught before they hit production.
Writing these four test categories by hand is feasible but slow, especially across a growing vibe-coded application where new endpoints appear with every sprint. Autonoma generates all four categories automatically: its AI agents read your routes and data models, then produce authorization boundary tests, direct API validation tests, business rule enforcement tests, and concurrent request tests from the codebase itself. The tool is open-source, so you can inspect every generated test before it runs.
| Vulnerability Type | Scanner Verdict | What Actually Reveals It |
|---|---|---|
| IDOR / broken object-level auth | Auth middleware present: pass | Cross-user request test returns 200 instead of 403 |
| Frontend-only input validation | Validation logic found in component: pass | Direct API call with invalid data returns 201 |
| Business logic bypass (plan limits) | No signature exists for this rule: no finding | API call after limit hit creates resource successfully |
| Race condition in coupon redemption | No detection capability: no finding | Concurrent requests result in double discount applied |
| Missing role check on admin endpoint | Authentication present: pass | Non-admin user successfully calls admin endpoint |
This is where Autonoma fits in the security stack. We built an open-source agentic testing layer that generates behavioral tests for exactly these failure modes. AI agents read your routes and data models, then produce test scenarios that include cross-user authorization checks, direct API validation tests, and boundary conditions for your business rules. The tests run against your live application. A scanner runs against your source files. Neither replaces the other, and both are necessary. For a deeper look at how this approach works, see what is agentic testing.
For teams adopting vibe coding tools and building out their verification layer, the quality gate guide for vibe-coded PRs covers how to integrate these checks into your CI pipeline without slowing down the iteration speed that made vibe coding worth adopting in the first place.
The False Sense of Security from Clean Scanner Reports
There is something specific about a passing scanner that is worth naming directly.
A failing scanner gets attention. The CI pipeline goes red, the team investigates, someone fixes the finding. A passing scanner is invisible. It does its job quietly and teams stop thinking about it. Over time, "we run Snyk" becomes part of the security identity of the team. It is cited in compliance reviews, mentioned in security questionnaires, listed in the runbook. It is a true statement that creates a false impression.
The impression is that the security posture is covered. The reality is that one specific tool is covering one specific slice of the risk surface. The vibe coding security risks that sit outside that slice (IDOR, logic bypasses, race conditions, missing server-side enforcement) are not diminished by the scanner passing. They are simply unmeasured.
For engineering leaders evaluating their AI coding adoption, the vibe coding risks guide covers the full landscape of where the verification gap creates exposure beyond just the scanner blind spot. The agentic testing for vibe-coded apps piece covers how behavioral test generation addresses the problem at the velocity vibe coding creates.
The starting point is simple: take one endpoint in your vibe-coded application that handles user-scoped data. Write a test that authenticates as a different user and tries to access that data. Run it. Check whether it fails with a 403 or succeeds with a 200.
That test takes five minutes to write. The answer it gives you is one your scanner cannot provide.
Security scanners miss any vulnerability that only appears at runtime, when the application is actually running and responding to requests. The top categories are: broken object-level authorization (IDOR), where a user can access another user's data through legitimate endpoints; frontend-only validation, where input validation exists in the UI component but not in the API handler; business logic errors, where your specific rules (plan limits, coupon redemption, role restrictions) are not enforced server-side; and race conditions, where concurrent requests on shared state produce incorrect outcomes. All of these require a running application to detect. Static scanners read source files and compare against known patterns, and none of these vulnerability types have patterns that appear in static code.
Yes, and they are worth running. SAST tools reliably catch hardcoded secrets and credentials in source files, dependency versions with published CVEs, use of deprecated cryptographic functions, SQL string concatenation patterns that enable injection, and some XSS patterns in template code. These are real vulnerabilities and finding them before production matters. The scanner gap is not that scanners are useless. It is that the specific failure modes most common in AI-generated code (authorization enforcement, business logic, runtime validation) are outside what scanners can detect. Run both SAST and behavioral testing. They cover different surfaces.
AI code generators optimize for functional correctness: the code does what the prompt says. Human developers bring implicit security knowledge: they know to add ownership checks on data endpoints because they have encountered IDOR vulnerabilities before, either directly or through code review. That tacit knowledge is not in the prompt, so it is not generated. The result is structurally correct security scaffolding (authentication middleware is present, tokens are generated correctly) without the enforcement wiring that connects scaffolding to actual data access. The more iterations a vibe-coded codebase goes through, the wider this gap tends to become. Each feature prompt adds new endpoints without necessarily adding the ownership checks those endpoints require.
Pick any endpoint that returns user-scoped data (documents, invoices, messages, profile data). Create two test users. Authenticate as User A. Make a request for a resource that belongs to User B, using that resource's actual ID. Assert that the response status is 403, not 200. If you get a 200, the endpoint has an IDOR vulnerability. In Playwright or any HTTP testing library, this is roughly 10 lines of code. If you want this test generated automatically across all your endpoints rather than written manually, [Autonoma](https://getautonoma.com) is an open-source agentic testing tool that reads your codebase and generates these cross-user authorization tests as part of the standard test suite.
Start with the highest-impact tests first: one cross-user authorization test per data endpoint, one direct-API test per form that accepts user input, and one business rule test per plan limit or usage cap. These cover the most common critical vulnerabilities. Write them against your API directly, not through the browser. Use your framework's HTTP client (request in Node.js, fetch with fetch-mock, or Playwright's request context). Run them in CI on every pull request. For teams that want test generation rather than manual test writing, [Autonoma](https://getautonoma.com) is open-source and uses AI agents to connect to your codebase and generate behavioral tests from your routes and data models, including the authorization and validation boundary tests that catch scanner-invisible vulnerabilities. The [E2E testing tools comparison](/blog/e2e-testing-tools) covers the underlying framework options if you want to build the suite yourself.