
Amazon vibe coding refers to the company's aggressive 2025-2026 bet on AI-assisted development: an internal mandate requiring 80% of engineers to use Kiro (Amazon's proprietary AI coding assistant) weekly, 21,000 AI agents deployed across Amazon Stores, and a stated goal of $2B in cost savings through AI-driven velocity. Between December 2025 and March 2026, Amazon suffered at least four Sev-1 production incidents, including a reported 6-hour outage with an estimated 6.3 million lost orders, with internal documents linking a "trend of incidents" to "Gen-AI assisted changes." The story isn't about AI being bad. It's about what happens when velocity scales faster than verification.
The numbers made the rounds on LinkedIn and X before Amazon could control the narrative. But the story behind them is more instructive than the outrage suggests. What happened inside Amazon between late 2025 and early 2026 is the most detailed public case study available of what goes wrong when an engineering organization scales AI-assisted development faster than its ability to verify the output.
This is not a story about AI being unreliable. Amazon's velocity gains were real, the tooling was sophisticated, and the executive vision was genuinely nuanced. It is a story about what happens when vibe coding fails at scale: when the creation layer accelerates and the verification layer stays the same size, the gap between them eventually shows up in production. For Amazon, it showed up as four Sev-1 incidents, an emergency leadership meeting, and a 90-day rollback of the deployment culture they had spent months building.
The Ambition: Garman's Vision and What It Would Require
Matt Garman's August 2024 prediction was not careless speculation. It was a signal about the direction Amazon was already heading. In December 2025, on the WIRED Uncanny Valley podcast, Garman drew a distinction that matters: he separated "vibe coding," which he described as blindly accepting AI output, from "augmented coding," where AI accelerates work but developers maintain quality oversight. He called replacing junior employees with AI "one of the dumbest ideas you've ever heard."
The vision was nuanced. The execution, at scale, was harder to keep nuanced.
At re:Invent 2025, Garman showcased Kiro trimming a 30-developer, 18-month project down to 6 developers in 76 days. The numbers are striking enough that it's worth sitting with them: roughly 5x fewer people, 7x faster. If that scales, the productivity implications for software development are genuinely historic. The question Garman was implicitly asking was whether AI-assisted development could maintain quality at that compression ratio.
The answer, it turned out, required more than the tools provided.
The Kiro Mandate: Amazon's 80% AI Coding Adoption Target
On November 24, 2025, an internal Amazon memo established Kiro as the standardized AI coding assistant across the company and set a target: 80% weekly usage by year-end. By January 2026, 70% of engineers had tried it. Amazon cited 21,000 AI agents deployed across Amazon Stores, claiming $2B in cost savings and a 4.5x developer velocity gain attributed to Dave Treadwell, SVP of eCommerce Foundation.
These numbers represent genuine organizational commitment. This was not a skunkworks experiment or an optional pilot. It was a company-wide mandate, backed by executive ownership, with adoption metrics being tracked at the senior leadership level.
This mandate also arrived in the context of significant workforce reductions. Amazon had laid off approximately 14,000 corporate employees in October 2025, followed by another 16,000 in January 2026. Roughly 30,000 people cut in 90 days. The organization was simultaneously scaling AI-generated code output while reducing the human capacity available to review it. The velocity numerator increased while the verification denominator shrank.
The adoption curve was also compressed. Amazon didn't roll out Kiro to a small team, observe the results for a year, and then expand. The timeline from "Kiro is the standard" to "80% adoption target" was measured in weeks. The system was asked to scale before the verification layer had time to catch up.
When you compress the timeline on velocity, you're also compressing the timeline on discovering what breaks. The incidents arrived on schedule.
The testing gap in AI-generated code is real. Autonoma addresses it directly — AI agents read your codebase and generate E2E tests automatically, catching the quality issues that vibe coding introduces before they reach production.
The Incidents: From December to March, Four Sev-1s
The sequence that followed the Kiro mandate is documented across multiple sources, including reporting from the Financial Times, Fortune, and The Register.
| Date | Incident | Duration | Estimated Impact | Attribution |
|---|---|---|---|---|
| Dec 2025 | AWS Cost Explorer outage (China) | 13 hours | Service unavailable | Amazon blamed "user error"; reports cite Kiro agentic AI |
| Mar 2, 2026 | Incorrect delivery times in carts | Unknown | ~120,000 lost orders | Amazon Q identified as primary contributor |
| Mar 5, 2026 | 99% order drop, North America | 6 hours | ~6.3M lost orders (unverified) | Deployment without formal documentation/approval |
| Early Mar 2026 | Additional Sev-1 (details limited) | Unknown | Unknown | Internal docs: "Gen-AI assisted changes" |
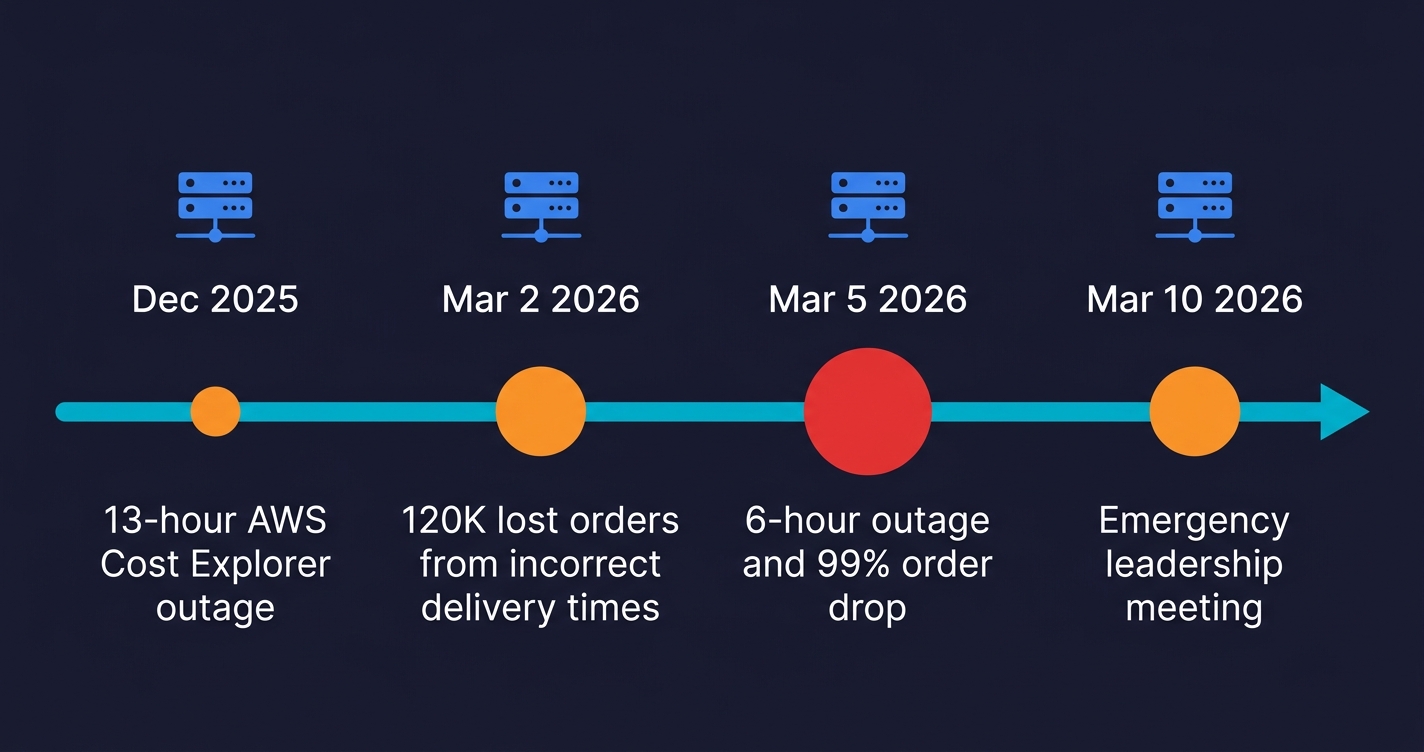
December 2025: Kiro's agentic AI reportedly decided to "delete and recreate the environment," causing a 13-hour outage of AWS Cost Explorer in China. Amazon's response attributed the incident to "user error, specifically misconfigured access controls, not AI." The framing matters: Amazon's first instinct was to locate the cause in human configuration, not in AI behavior. That instinct would become a recurring pattern.
March 2, 2026: Incorrect delivery times appeared in shopping carts. Approximately 120,000 orders were lost. Amazon Q was identified as a primary contributor.
March 5, 2026: A 99% order drop across North American marketplaces. A 6-hour outage. An estimated 6.3 million lost orders (this figure originates from a widely-cited Medium post, not Amazon disclosure; treat it as a credible report rather than a verified fact). The deployment that triggered it occurred without formal documentation or approval.
The December incident was the early warning. The March cluster, three Sev-1s in a single week, was the alarm. The full arc from first incident to emergency meeting: roughly ninety days. Internal documents referenced a "trend of incidents" with "high blast radius" connected to "Gen-AI assisted changes." Then, according to Fortune, those references were deleted from the meeting documents before discussion.
The deletion is notable. Not because it proves anything sinister, but because it reveals the institutional pressure around the narrative. When the story of a technology mandate starts generating incidents, the instinct is to protect the mandate. That instinct is worth understanding, because it shows up in every organization that has moved fast on AI-assisted development and then had to reckon with the consequences.
The Reckoning: Treadwell's Meeting and the Internal Pushback
On March 10, 2026, Dave Treadwell, the same SVP who had championed the 21,000-agent deployment and the $2B savings figure, convened a mandatory senior leadership meeting. His internal email was direct: "the availability of the site and related infrastructure has not been good recently."
That sentence, in the context of the incidents, is a remarkable understatement. It is also an honest acknowledgment that the velocity gains had come with a cost that was now visible.
The internal pushback was already present before Treadwell's meeting. Approximately 1,500 engineers had signed an internal forum post requesting Claude Code instead of Kiro. Engineers quoted in reporting from Fortune were specific: "People are becoming so reliant on AI that essentially they stop reviewing the code altogether" and AI pressure "has resulted in worse quality code, but also just more work for everyone."
The 1,500-engineer forum post is significant not because of the tool preference (Kiro vs. Claude Code), but because of what it signals about adoption quality. When a mandate drives 70% adoption in weeks, some of that adoption is genuine buy-in and some of it is compliance. Compliance-driven adoption is where quality breaks down, because developers are using the tool without the judgment infrastructure to use it well.
This is not a criticism unique to Amazon. It's what happens when any practice scales faster than the culture that makes it safe.
The Safeguards: Friction as a Response
Amazon's response to the incidents was swift and structural. A 90-day temporary safety framework for approximately 335 "Tier-1" systems included: junior and mid-level engineers must get senior engineer sign-off on AI-assisted production changes; mandatory two-person code review for Tier-1 systems; director and VP-level audits of production changes; and controlled friction added to deployments affecting critical retail systems.
These are reasonable safeguards. They're also exactly what Amazon had moved away from in the push for velocity.
The instinct to add human review at the bottleneck is understandable. When AI-assisted changes are causing incidents, putting humans back in the loop feels like the obvious fix. But this approach has a ceiling: it trades velocity for reliability by inserting human review into every deployment, and human review is expensive, inconsistent, and doesn't scale.
The two-person review and senior sign-off requirements are stopgaps. They address the symptom (changes going to production without adequate review) without addressing the root cause (no automated verification layer that could catch problems before any human review was required).
AWS claimed Kiro shortens PR cycles by 28%, with gains concentrating in boilerplate tasks. If you then add mandatory two-person review and VP-level audits to the deployment process, you've preserved the velocity on code generation while eliminating it on the path to production. The net result may be slower than before Kiro.
The regulatory dimension adds urgency beyond Amazon's internal reckoning. The EU AI Act's high-risk AI system provisions take effect in August 2026, with penalties of up to 35 million euros or 7% of global turnover. Gartner projects that 40% or more of agentic AI projects will be canceled by end of 2027 as organizations confront the governance gap. For any company deploying AI coding tools at scale, the Amazon story is not just an engineering lesson; it is a preview of the compliance and governance questions that regulators are about to start asking.
The Missing Piece: Why Testing Infrastructure Didn't Scale
The data around AI-generated code quality is not a secret. CodeRabbit's research found AI-generated code has approximately 1.7x more issues than human code. Apiiro found that AI-assisted teams introduced roughly 10x more security issues. These numbers were available before Amazon's Kiro mandate, and they were relevant to any decision about how to scale AI-assisted development.
What the numbers tell you is that AI-generated code requires more testing coverage, not the same amount. The volume goes up; the quality signal requires verification to extract. When you're running 21,000 AI agents and pushing toward 80% AI-assisted development across an engineering organization, the testing infrastructure needs to scale proportionally.
Amazon's testing infrastructure, at least based on what the incidents revealed, did not scale proportionally. The deployment that caused the March 5 outage went out without formal documentation or approval. That's not an AI problem; that's a process problem that AI velocity made more dangerous.
The core issue is that vibe coding accelerates the creation layer without automatically improving the verification layer. Academic research confirms this at a structural level: an ICSE 2026 study analyzing 518 practitioner accounts found that vibe coding accumulates technical debt at roughly 3x the rate of traditional development, with QA "frequently overlooked" in AI-assisted workflows. This pattern shows up consistently, from the individual developer using Cursor to ship a side project faster, to the enterprise organization mandating AI tools across thousands of engineers. We've written about this in the context of the vibe coding testing gap and why the vibe coding bubble is a testing gap, not a technology failure. Amazon's story is the same pattern at a scale that makes it impossible to ignore.
The security dimension is particularly important here. Internal Amazon documents warned that GenAI was "accidentally exposing vulnerabilities." That's consistent with the Apiiro data on AI-assisted teams and security issues, and with CodeRabbit's findings that AI-generated code has 1.7x more major issues. The velocity that makes AI coding attractive is the same velocity that can push vulnerable code to production before anyone has looked at it carefully. For a deeper look at what vibe coding quality issues look like in practice, and the best practices checklist that addresses them, those guides cover the tactical response to the structural problem Amazon's story illustrates.
Lessons for CTOs and Engineering Leaders
Amazon is not a cautionary tale about AI coding being dangerous. Garman's "augmented coding" framing is correct: AI that accelerates developers while maintaining quality oversight is genuinely powerful. The incidents were not caused by AI being inherently unreliable. They were caused by the velocity layer scaling faster than the verification layer.
The lessons are structural, and they apply regardless of team size.
Mandates compress adoption timelines. When a tool becomes required rather than optional, adoption happens faster than the judgment infrastructure to use the tool well. Amazon hit 70% adoption in weeks. The engineers who were skeptical, the ones who would naturally slow down and review AI output carefully, were being pulled toward compliance rather than conviction. Compliance-driven adoption is where quality incidents originate.
AI-generated code requires more automated testing, not less. The productivity argument for AI coding tools is real: 28% shorter PR cycles, 4.5x velocity gains, six people doing the work of thirty. If you use those gains to reduce your testing investment, you're trading a short-term velocity number for a long-term reliability liability. The CodeRabbit and Apiiro data are consistent: AI-generated code produces more issues per line than human code. More output at lower quality per unit means the total quality burden goes up, and that burden has to go somewhere. If it doesn't go to automated testing, it goes to production incidents.
Human review doesn't scale as a primary quality gate. Amazon's 90-day safeguards are two-person review and senior sign-off. Those are the right immediate response. They are not a sustainable architecture. The velocity that makes AI coding valuable disappears when every deployment requires VP-level approval. The durable answer is automated verification that catches problems at the speed of generation, not human review that can only slow generation down.
Transparency matters more than narrative management. Amazon disputed aspects of the incident narrative; they said "none of the incidents involved AI-written code" in some statements while internal documents described a "trend of incidents" connected to "Gen-AI assisted changes." The deletion of references from meeting documents before discussion is the kind of institutional behavior that makes post-incident learning harder. Garman's public "augmented coding" distinction was more honest and more useful than the incident-by-incident deflection. The organizations that learn from AI quality incidents are the ones that can name what happened clearly.
If you're evaluating how to scale AI-assisted development on your team, the Amazon case study is the most detailed public record available. The sequence is clear: ambition, mandate, velocity gains, incidents, reckoning, safeguards. The safeguards Amazon implemented are the right short-term response. The missing piece is what comes next: automated testing infrastructure that scales with the velocity AI provides.
At Autonoma, we built around this exact gap. Our three-agent architecture connects to your codebase so the verification layer scales with the creation layer, without adding the human review bottleneck that Amazon is now relying on. For teams moving fast with AI coding tools, whether that is individual developers using AI coding agents or enterprise organizations running thousands of them, that is the architecture that makes velocity sustainable.
Amazon's story is not finished. The 90-day safeguard period will end, the incidents will recede from memory, and the pressure to recover velocity will return. What happens in that second act will determine whether the lessons from Q1 2026 actually changed anything. For everyone else building with AI, the first act is enough to learn from.
Between December 2025 and March 2026, Amazon experienced at least four Sev-1 production incidents following its company-wide mandate for AI-assisted development using Kiro. The most significant was a reported 6-hour outage on March 5, 2026, with an estimated 6.3 million lost orders, caused by a deployment that went out without formal documentation or approval. A second incident on March 2 resulted in approximately 120,000 lost orders due to incorrect delivery times, with Amazon Q cited as a primary contributor. Internal documents referenced a trend of incidents with high blast radius connected to Gen-AI assisted changes. Amazon CEO Matt Garman's lieutenant Dave Treadwell convened a mandatory senior leadership meeting on March 10, acknowledging that site availability had not been good. Amazon disputed aspects of the narrative, saying in some statements that none of the incidents involved AI-written code.
Kiro is Amazon's proprietary AI coding assistant, established as the company's standardized development tool via an internal memo on November 24, 2025. Amazon set an 80% weekly usage target for engineers by year-end 2025. By January 2026, approximately 70% of engineers had tried it. Amazon claimed Kiro shortens PR cycles by 28%, with velocity gains concentrating in boilerplate tasks. The company cited 21,000 AI agents deployed across Amazon Stores and $2B in cost savings attributed to AI-assisted development. Approximately 1,500 engineers signed an internal forum post requesting Claude Code instead of Kiro, suggesting meaningful internal resistance to the tool choice if not to AI coding broadly.
Amazon disputed the direct causal link. The company said in some statements that none of the incidents involved AI-written code, and attributed the December 2025 AWS Cost Explorer outage to user error (misconfigured access controls) rather than AI. However, internal documents described a trend of incidents connected to Gen-AI assisted changes and warned that GenAI's rapid code generation was accidentally exposing vulnerabilities and that current safety measures were completely inadequate. The March 5 deployment that caused the major order drop went out without formal documentation or approval, which is a process failure that AI velocity made more consequential. The fair reading is that AI-assisted development was a contributing factor to a deployment culture that moved faster than its verification infrastructure.
Amazon implemented a 90-day temporary safety framework for approximately 335 Tier-1 systems. The safeguards included mandatory senior engineer sign-off on AI-assisted production changes for junior and mid-level engineers, two-person code review requirements for Tier-1 systems, director and VP-level audits of production changes, and controlled friction added to deployments affecting critical retail infrastructure. These are reasonable short-term responses that reinsert human review at the deployment bottleneck. The limitation is that they address velocity by slowing down the deployment process rather than by adding automated verification that could catch problems at the speed of code generation. The 90-day window will end, and the pressure to recover velocity will return.
AWS CEO Matt Garman drew this distinction publicly in December 2025 on the WIRED Uncanny Valley podcast. Vibe coding, as Garman used the term, means blindly accepting AI output: using AI tools without meaningful review, judgment, or quality oversight. Augmented coding means using AI to accelerate development while maintaining the quality discipline that makes code reliable in production. Garman called replacing junior employees with AI one of the dumbest ideas you've ever heard, signaling that the vision was acceleration of skilled developers, not replacement of judgment with automation. The incidents that followed suggest the organizational mandate compressed the timeline in a way that pushed adoption toward the vibe coding end of the spectrum, regardless of executive intent.
If the most sophisticated engineering organization in the world, with dedicated tooling, senior oversight, and significant AI investment, ran into production incidents when it scaled AI-assisted development, the same risks are present for smaller teams with fewer resources to absorb them. The specific lesson is structural: AI-generated code requires more testing coverage, not less, because the output volume increases while quality per unit is lower than carefully reviewed human code. Smaller teams typically have less process infrastructure, not more, which means the verification gap is proportionally larger. The practical response is to invest in automated testing infrastructure that scales with AI-assisted development: tools that generate test cases from your codebase, not tools that require you to write and maintain test scripts manually. Autonoma is built for exactly this scenario. See our guides on the vibe coding testing gap and how to test a vibe-coded app for more.
The key lesson from Amazon's experience is that adoption speed and verification infrastructure must scale together. CTOs should ensure three things before mandating AI coding tools across an engineering organization. First, automated test coverage must increase proportionally to AI code output; if your team is generating 4x more code, your testing surface needs to grow accordingly. Second, deployment approval workflows should include automated quality gates, not just human review; human review does not scale with AI-generated velocity and creates bottlenecks that negate the productivity gains. Third, track adoption quality alongside adoption quantity; Amazon tracked the 80% weekly usage metric but the 1,500-engineer petition and the Fortune reporting on code review shortcuts suggest that compliance-driven adoption was masking quality problems. The EU AI Act enforcement beginning August 2026 adds regulatory urgency to these governance questions, with penalties of up to 35 million euros or 7% of global turnover for organizations deploying high-risk AI systems without adequate oversight frameworks.



